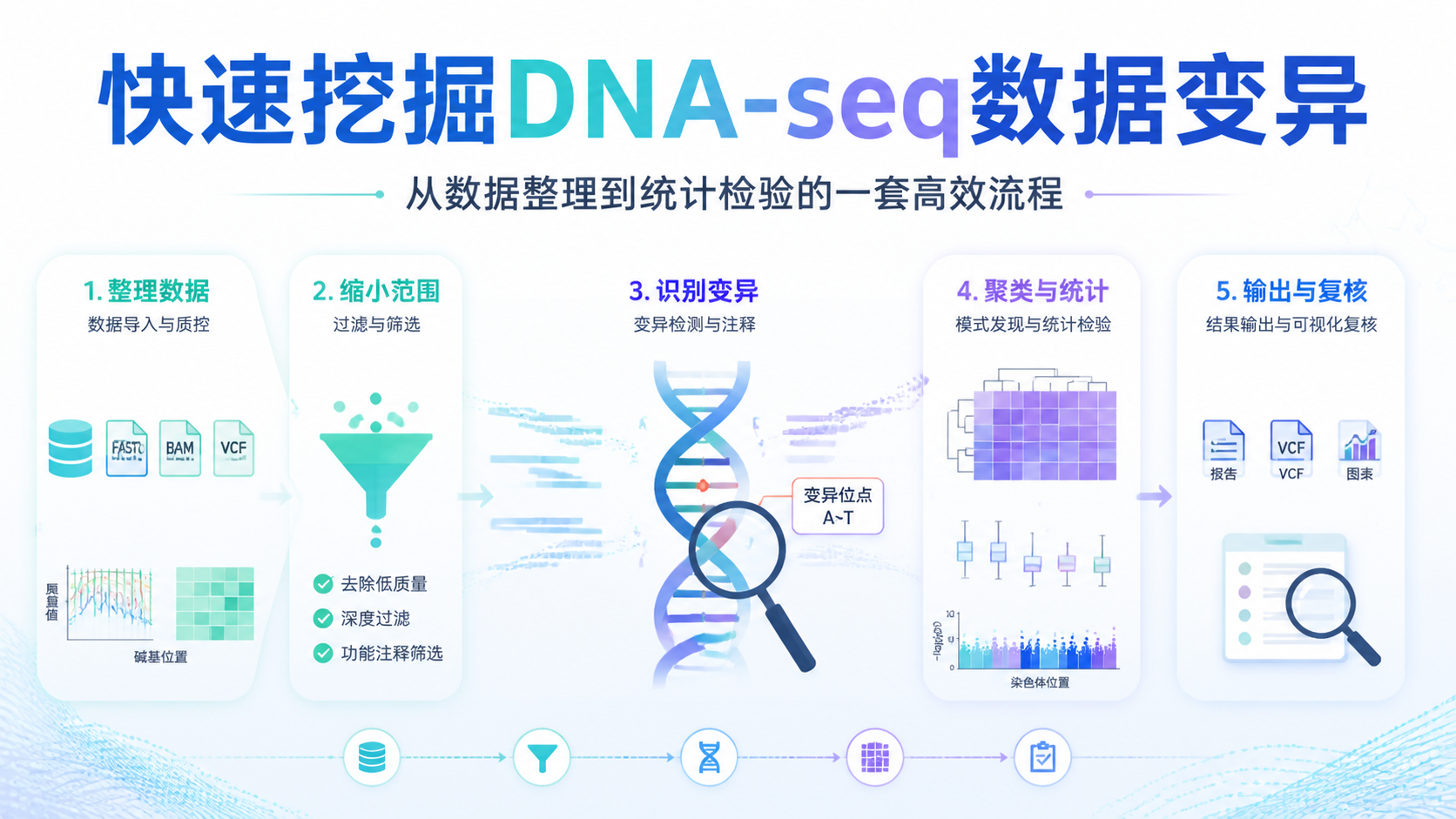
引言Introduction
外显子测序数据看起来只是“原始 reads”。但真正难的是,如何把它变成可比较、可解释的表达结果,尤其是 count、FPKM、FPKM UQ 和 TPM 之间的转换。如果你在分析中遇到样本间口径不一致、基因长度偏差、批量处理效率低,这篇文章会直接帮你理清思路。
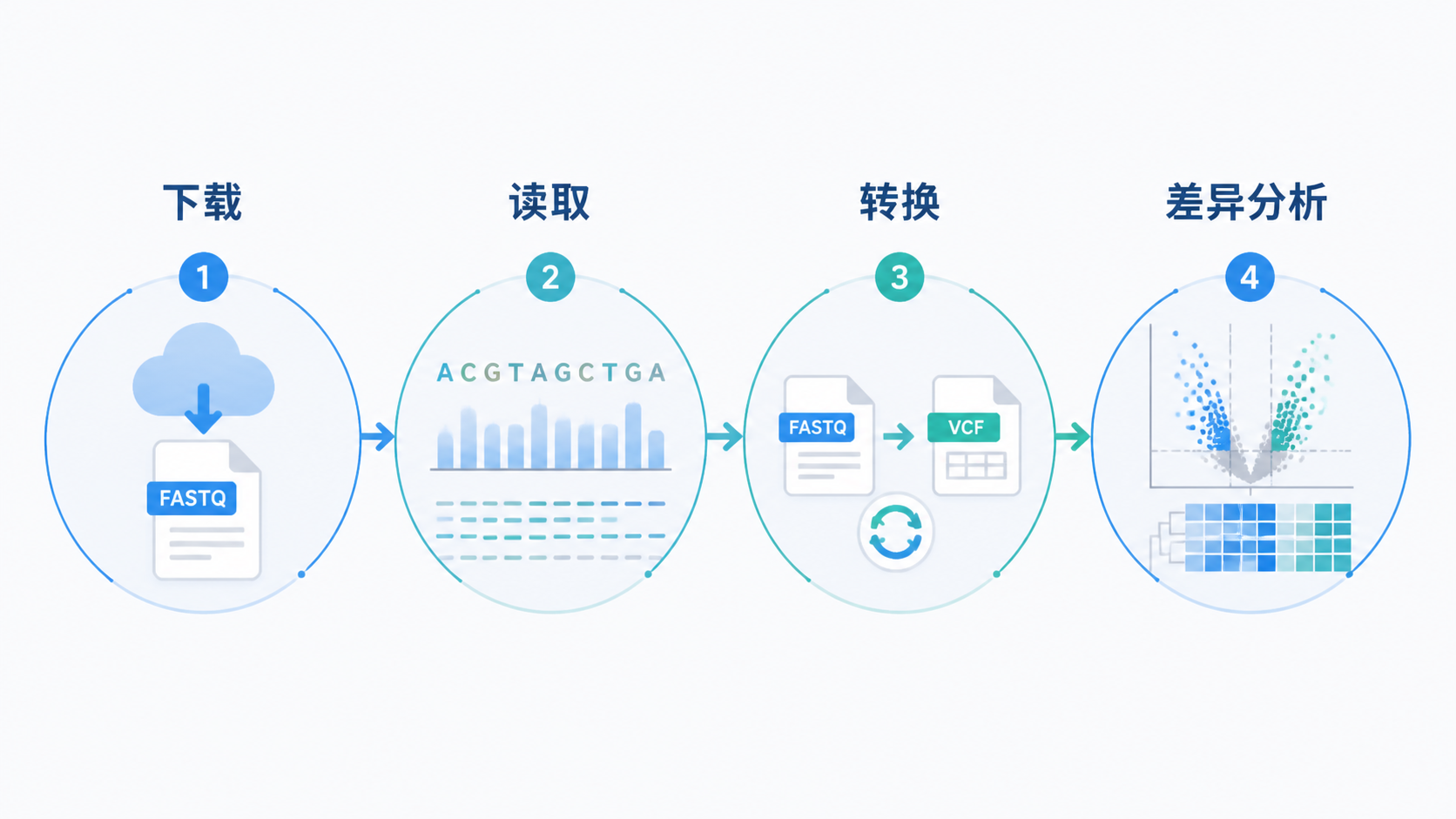
1. 先搞清楚外显子测序数据的核心类型
1.1 Count 是差异分析的起点
外显子测序数据的最原始表达量通常是 count。 它是非负整数,表示某个样本中某个基因被测到的 reads 数。这个数值受两件事影响明显,第一是测序深度,第二是基因长度。
这也是为什么 count 不能直接跨基因比较。一个长基因 count 高,不一定代表真实生物学意义上的高表达。做差异分析时,count 常作为后续标准化和建模的基础。
1.2 RPM、RPKM、FPKM、TPM的区别
在表达量转换中,最容易混淆的是这些单位。可以简单理解为,它们都是在不同层面纠正偏差。
- RPM/CPM ,校正测序深度,不校正基因长度。
- RPKM ,校正测序深度和基因长度,适合单端测序场景。
- FPKM ,与RPKM相近,但用于双端测序,按片段数计算。
- TPM ,先按长度标准化,再统一样本总量,便于不同样本间比较。
对外显子测序数据来说,TPM更适合做样本间表达量展示,count更适合差异分析建模。
1.3 FPKM UQ为什么常被用来补充比较
FPKM UQ用样本中所有基因片段数的上四分位数做归一化。它的目的,是减少极端高表达基因对总量校正的干扰。对于 TCGA 这类大规模项目,FPKM UQ常用于与原始 count、FPKM 共同核对,验证转换结果是否一致。
2. 获取并整理外显子测序数据
2.1 先下载原始文件和元数据
分析外显子测序数据前,先确认数据来源和文件结构。课程中以 TCGA 肝癌数据为例,需要下载 count、FPKM 和 FPKM UQ 数据,同时配套 metadata。
下载后要统一放入同一文件夹,并完成解压。这样后续读取、匹配样本名、核对MD5值会更稳定。
2.2 元数据清洗是关键一步
元数据中通常包含文件名、MD5 sum、TCGA ID、组织类型和分组信息。读取后建议先做清洗,再合并样本注释。这样可以避免后面出现样本名不一致、分组错配的问题。
对医学生和科研人员来说,这一步不是“辅助工作”,而是保证结果可信度的前提。
如果元数据错了,后面所有表达量结果都可能失真。
3. 掌握外显子测序数据的转换逻辑
3.1 单个样本怎么从count转成FPKM和TPM
转换外显子测序数据时,必须同时知道原始 count 和基因长度。课程中使用的是 GTF V22 注释文件,并把外显子长度求和,得到每个基因的长度。
基本逻辑如下:
- 读取单个样本的 count。
- 结合基因注释信息,获得外显子总长度。
- 按公式计算 FPKM。
- 再进一步计算 FPKM UQ 和 TPM。
这里的核心不是公式本身,而是长度信息是否准确。 基因长度取错,后面所有归一化结果都会偏移。
3.2 批量转换更适合真实项目
真实项目里,外显子测序数据往往不是一个样本,而是几十个、几百个样本。课程中使用批量读取与转换方法,把 count 数据统一处理成 FPKM 和 FPKM UQ。
这种方式有两个好处:
- 节省人工操作时间。
- 降低逐个样本计算带来的误差。
批量处理后,还要把结果与 TCGA 官方提供的数据进行比对。 这一步很重要。若计算结果一致,说明流程可靠;若不一致,就要回头检查注释版本、长度定义和样本匹配是否正确。
3.3 TPM适合做展示,count适合做统计
很多初学者会直接拿 TPM 做差异分析。严格来说,这并不适合所有场景。TPM更适合做可视化、横向展示和表达谱描述。
而差异表达分析通常建议以原始 count 为输入,再通过 DESeq2 等方法建模。
原因很直接。差异分析需要保留计数分布信息,而不是先把信息压缩掉。这个原则对外显子测序数据尤其重要。
4. 用DESeq2做差异表达分析
4.1 先完成样本筛选和分组
在进行差异分析前,需要先根据样本注释信息把样本分成癌组织和癌旁正常组织。课程示例中,经过过滤后保留了 401 个样本,并进一步整理成适合 DESeq2 的输入格式。
同时,还要引入 batch 信息。批次效应在多中心数据里很常见。如果不处理,PCA 图可能更多反映批次差异,而不是疾病差异。
4.2 构建DESeq2对象并做VST转换
DESeq2 分析的核心是先构建 DDS 对象,再进行差异分析。分析前通常会做 VST 转换,用于稳定方差,并便于 PCA 可视化。
常见流程是:
- 导入 count 数据和 metadata。
- 检查行名和列名是否完全一致。
- 构建 DESeq2 对象。
- 做 VST 转换。
- 使用 PCA 观察样本分布。
如果正常与肿瘤样本在 PCA 上明显分离,说明数据结构比较清晰。 若分离不明显,可能需要进一步检查批次效应或样本质量。
4.3 去除批次效应后再看结果
课程中还演示了使用 limma 的 removeBatchEffect 去除 batch 效应。去批次后再做 PCA,能更直观地判断分组信号是否增强。
这一步对外显子测序数据很实用。尤其是来自不同平台、不同批次、不同中心的数据,批次效应往往会掩盖真实生物学差异。
5. 结果提取、过滤与保存
5.1 差异分析前先做基础过滤
在正式运行 DESeq2 前,常见做法是先过滤低表达基因。课程里使用的标准是,counts 大于零的样本数至少为四个。
这个过滤条件能减少极低表达基因对统计模型的干扰,也能提升运算效率。
5.2 提取结果时要关注哪些字段
差异分析完成后,通常会提取结果对象,并整理出这些信息:
- 基因ID。
- 校正后的P值。
- log2 fold change。
- 显著性筛选结果。
真正有价值的不是结果表本身,而是你是否能把结果和样本分组、批次信息、基因注释对应起来。 只有这样,后续才能做通路分析、候选基因筛选和实验验证。
5.3 保存结果,方便复现和复核
完成分析后,建议保存以下内容:
- VST 转换后的表达矩阵。
- 基因注释信息。
- 差异分析结果。
- 分组和批次信息。
这样做的意义很明确。后续无论是论文复现、补充分析,还是答辩现场追问,都能快速回到同一套数据逻辑。
如果你希望把外显子测序数据分析做得更稳、更快,关键在于标准化流程。 从下载、读取、转换,到批次校正和差异分析,每一步都要可追溯、可验证。解螺旋品牌提供的课程体系,正是围绕这类真实项目场景设计,适合医学生、医生和科研人员系统提升分析能力。
总结Conclusion
外显子测序数据分析不是单纯跑代码,而是一个从原始 count 到可解释结果的完整流程。你需要先理解数据类型,再完成元数据整理、表达量转换、差异分析和结果验证。count 适合建模,TPM 适合展示,FPKM 和 FPKM UQ 适合辅助核对。
如果你想少走弯路,建议直接采用成熟的标准流程。借助解螺旋的系统课程,你可以更快掌握外显子测序数据分析的关键步骤,减少试错成本,提升科研效率。
- 引言Introduction
- 1. 先搞清楚外显子测序数据的核心类型
- 2. 获取并整理外显子测序数据
- 3. 掌握外显子测序数据的转换逻辑
- 4. 用DESeq2做差异表达分析
- 5. 结果提取、过滤与保存
- 总结Conclusion