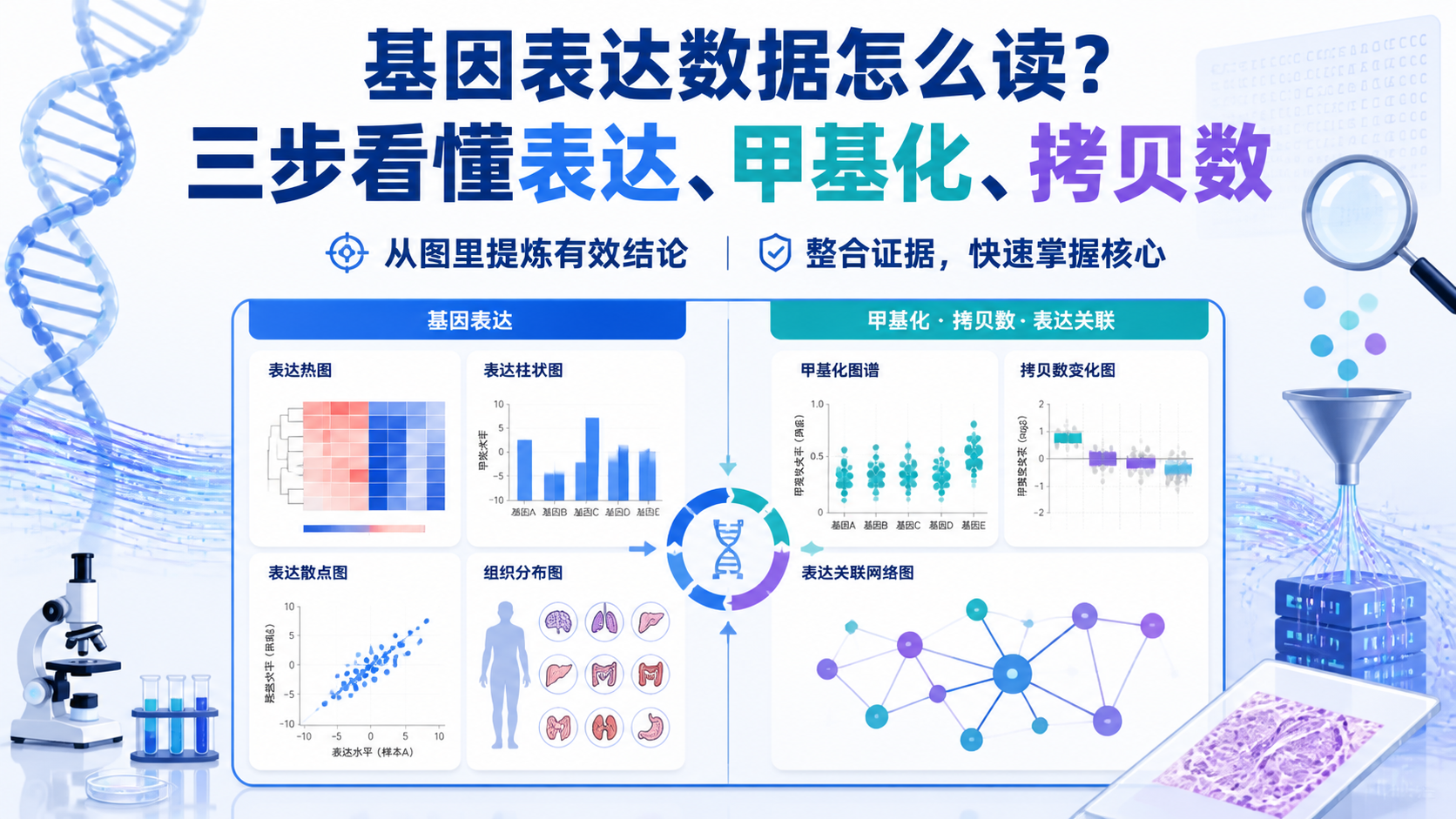
引言Introduction
转录组数据看起来容易做,真正难的是做得严谨。样本怎么分组,测序深度够不够,分析流程是否一致,都会直接影响结论可信度。如果前期设计不稳,后面的差异分析再漂亮也可能是偏的。 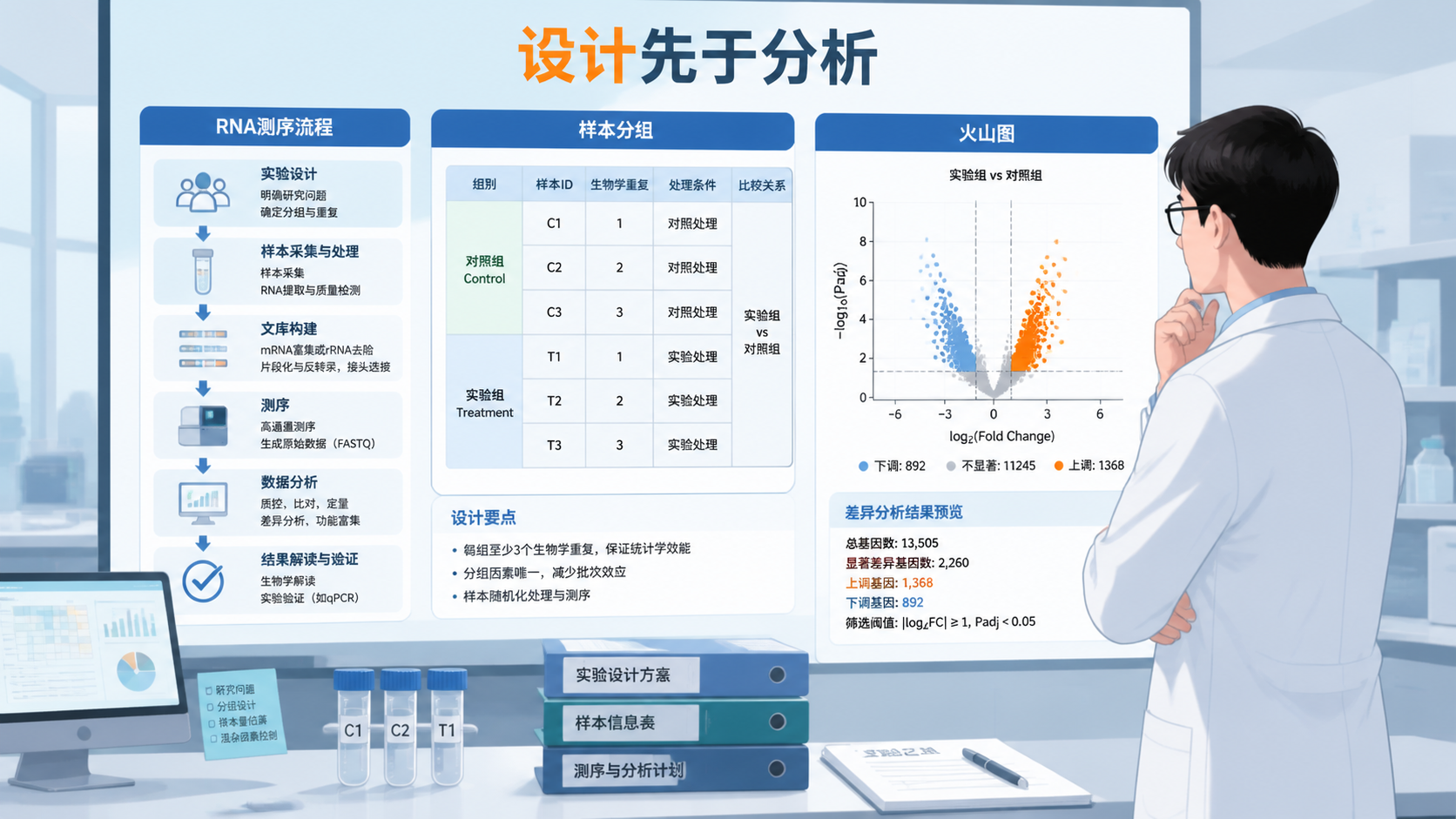
1. 先把研究问题定义清楚
1.1 明确转录组数据回答什么问题
严谨的第一步,不是上机器,而是先定义问题。你要先想清楚,转录组数据是用来找差异基因,还是找通路,还是做分型,还是服务机制研究。
如果问题不清,后面所有分析都会发散。
比如疾病相关研究里,表达差异只能说明相关性,不能直接推出因果。转录组数据最适合做“发现”,但不适合单独承担“证明”。
1.2 样本分组要符合生物学逻辑
分组要围绕核心变量设计。病人和对照,治疗前和治疗后,高低风险组,或者不同表型组,必须有明确的生物学依据。
同时要控制混杂因素。年龄、性别、分期、组织来源、治疗史,都会影响表达谱。
如果分组混乱,后面的差异结果很可能只是临床变量的投影。
2. 前处理决定转录组数据的下限
2.1 样本质量比分析方法更重要
很多问题不是出在统计,而是出在样本本身。RNA完整性差、降解严重、污染明显,都会让转录组数据失真。
对于测序前样本,至少要关注这些核心指标。
- RNA纯度是否达标。
- RNA完整性是否稳定。
- 样本是否存在明显批次差异。
- 处理时间是否一致。
样本质量不稳定时,后续再高级的算法都只能放大噪音。
2.2 生物重复不能省
严谨的转录组数据,必须有足够的生物重复。
只有技术重复,不能代表真实生物差异。因为技术重复只能说明机器和流程稳定,不能说明结论可靠。
一般来说,生物学重复越充分,越有利于估计真实变异。
如果样本条件有限,至少也要保证组内一致性,并在论文中如实说明限制。
3. 测序和建库环节要标准化
3.1 建库和测序参数要统一
同一项目里,尽量使用同一建库方案、同一测序平台、同一批次策略。
否则批次效应会进入表达矩阵,后面很难彻底消除。
对于单细胞转录组,更要注意细胞捕获效率、barcode、UMI、测序饱和度等问题。
对于bulk RNA-seq,则要重点关注文库复杂度、比对率和reads分布。
3.2 测序深度要和研究目的匹配
不是越深越好,而是要够用。
如果目标是做常规差异表达,重点是组内一致性和覆盖均衡。
如果目标是低丰度转录本、剪接变体或异构体分析,就需要更高深度。
测序深度不足时,低表达基因和边缘变化会被系统性漏掉。
4. 分析流程必须可重复
4.1 原始数据处理要保留完整链条
严谨的转录组数据分析,必须保留从原始数据到结果表的完整过程。
包括质控、过滤、比对、定量、标准化、差异分析、富集分析,每一步都应可追溯。
如果中间任一步骤不可复现,最后结果的可信度就会下降。
建议在项目中固定版本信息,包括软件版本、参考基因组版本、注释文件版本和参数设置。
4.2 质控不能只看一个指标
转录组数据质控不能只盯一个PCA或一个火山图。
至少要同时看以下几个层面。
- 样本测序质量。
- 比对质量。
- 基因覆盖情况。
- 表达分布是否异常。
- 样本间相关性是否合理。
这些信息合起来,才能判断数据是否可用。
只要有一个关键环节异常,就要先排查,而不是急着做结论。
5. 统计分析要避免“看起来显著”
5.1 多重检验要控制假阳性
转录组数据的基因数很多,天然容易产生假阳性。
因此差异分析不能只看P值,还要看FDR或校正后的显著性结果。
如果不控制多重比较,结果中会混入大量偶然显著。
这也是为什么转录组研究很强调统计规范,而不是只追求“显著基因列表”。
5.2 结果要结合效应量解释
严谨分析不能只问“显不显著”,还要问“变化大不大,是否有生物学意义”。
一个基因即使统计显著,如果fold change很小,实际解释价值可能有限。
建议同时看:
- 差异倍数。
- 校正P值。
- 表达稳定性。
- 与已知通路的一致性。
统计显著不等于生物学重要。
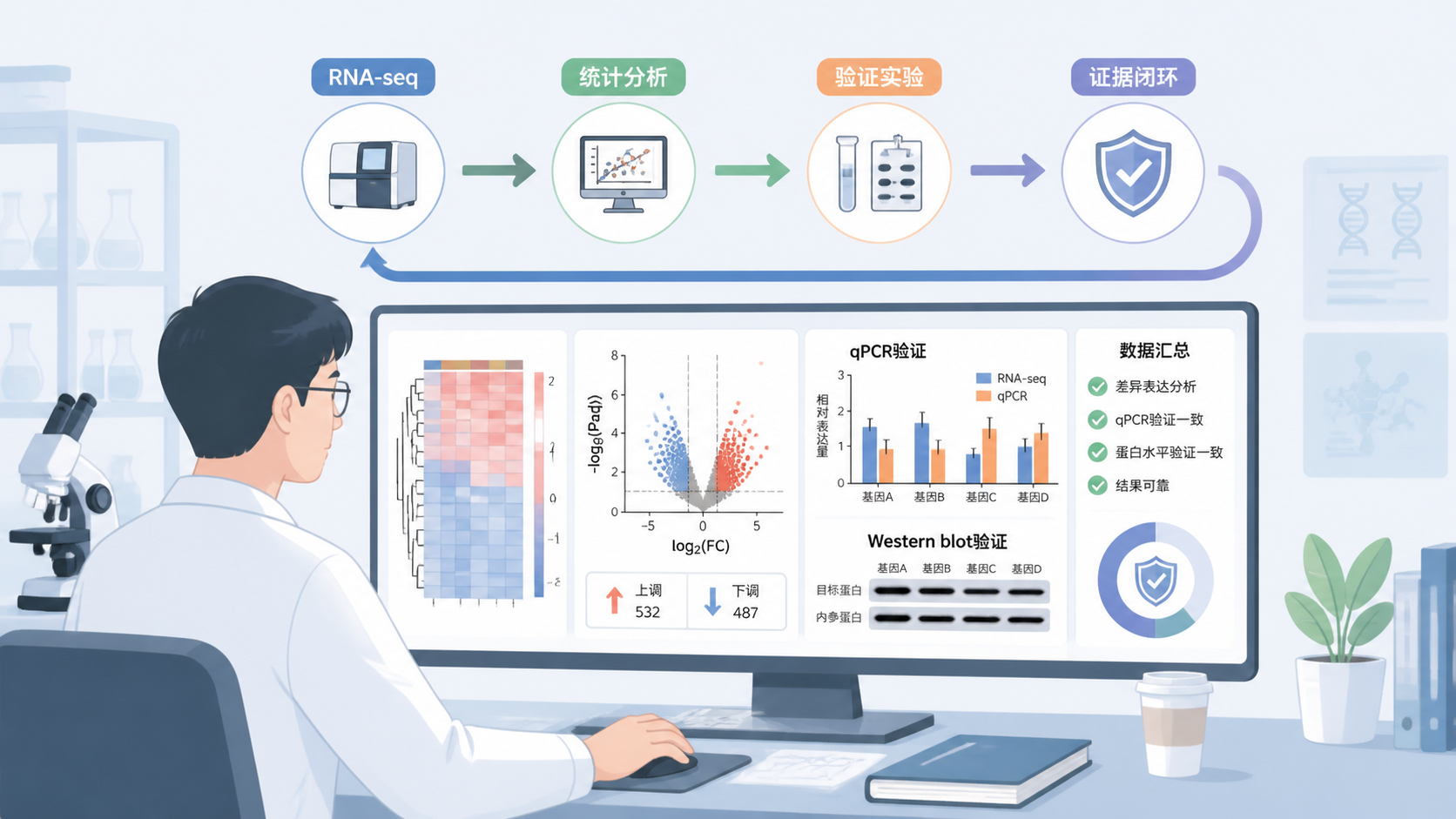
6. 结果验证决定文章说服力
6.1 转录组数据必须回到实验验证
RNA测序是发现工具,不是最终结论。
高质量文章通常都会做qPCR、Western blot、免疫组化,或者功能实验来验证关键结果。
如果研究的是机制,还要进一步做干预和回复实验。
例如上调、下调、阻断后,表型是否逆转。
这类设计能把“相关”向“因果”推进一步。
6.2 公共数据库和内部数据结合更稳
单一数据集容易受样本量和队列偏倚影响。
如果条件允许,建议把内部实验结果与公共数据库交叉验证。
内部数据提供直接证据,外部数据库提供可重复性。
两者一致时,结论的可信度会明显提高。
这也是很多高质量转录组研究常用的写法。
7. 常见的几个坑
7.1 只做差异,不做解释
差异基因列表只是起点。
真正有价值的是把差异基因放回通路、临床分层和机制框架里解释。
否则文章很容易停留在“罗列结果”。
7.2 批次效应处理不足
不同日期、不同试剂、不同操作者,都会引入批次效应。
如果批次效应比生物效应还强,聚类和差异分析都会被干扰。
7.3 过度依赖单一图形
PCA、热图、火山图都很重要,但它们只是展示。
严谨的转录组数据,核心永远是设计、重复、统计和验证。
总结Conclusion
转录组数据要做得更严谨,关键不在于把流程走完,而在于把每一步做实。先明确问题,再稳定样本和分组,统一建库和测序流程,最后用可重复的分析和独立验证来支撑结论。对医学生、医生和科研人员来说,这才是把表达谱结果做成可信证据的关键。
如果你希望把转录组数据分析流程、结果解释和论文写作进一步标准化,可以关注解螺旋品牌,获得更系统的科研支持。
- 引言Introduction
- 1. 先把研究问题定义清楚
- 2. 前处理决定转录组数据的下限
- 3. 测序和建库环节要标准化
- 4. 分析流程必须可重复
- 5. 统计分析要避免“看起来显著”
- 6. 结果验证决定文章说服力
- 7. 常见的几个坑
- 总结Conclusion