





引言Introduction
基因表达数据看似复杂,常见问题却很集中。找不到目标基因,分不清不同数据类型,也不会快速判断表达差异是否可信。本文用3步梳理基因表达数据的核心解读方法,帮助医学生、医生和科研人员高效上手。
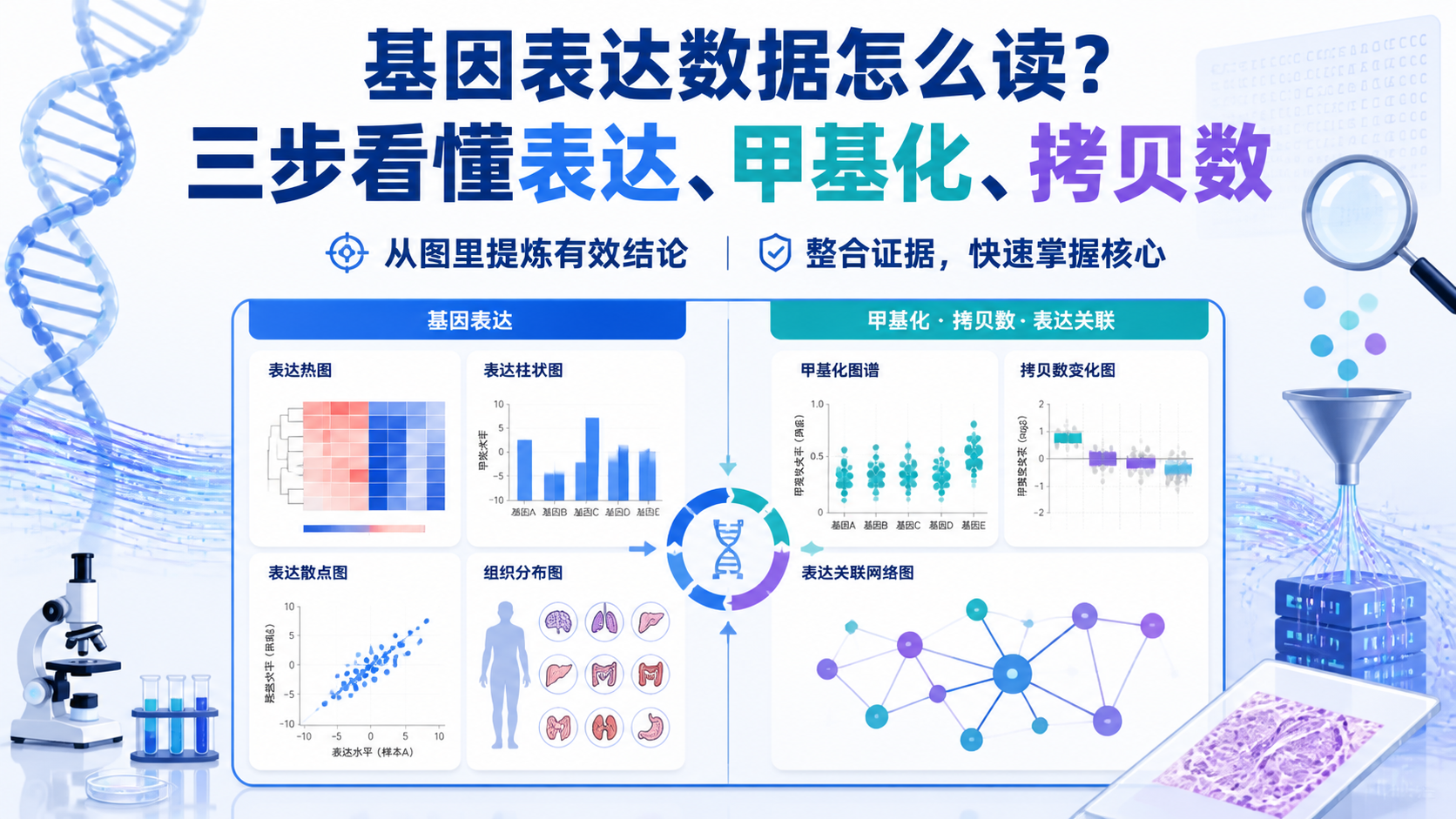
1. 先认清基因表达数据的基本结构
1.1 先看检索入口和基础信息
在CCLE数据库中,检索基因表达数据时,可以直接在搜索栏输入基因名或细胞系名。例如输入 TP53 ,系统会给出模糊提示,方便排查相近基因。点击后再检索,页面会刷新出对应结果。
结果页通常先显示三类关键信息。
- 基因名称。
- Entrez ID。
- 基因描述。
这一步的核心,不是急着看图,而是先确认你查到的是不是目标对象。 一旦基因名或ID混淆,后续表达解读都会偏离。
1.2 先区分不同表达数据类型
基因表达数据不只一种。CCLE 中默认常见的是 mRNA表达谱(RNAseq) 。但研究中还可以切换到不同数据集,比如拷贝数、DNA甲基化,甚至敲低相关数据。
这很重要。因为表达变化未必只来自转录水平。
例如,某基因在 mRNA 层面上调,不代表它一定没有受到拷贝数改变或甲基化调控。真正严谨的表达解读,必须先把“表达变化”和“调控来源”分开看。
1.3 先理解结果图的含义
基因表达数据常见展示方式包括条形图和散点图。条形图适合快速查看不同样本或细胞系的表达水平。散点图适合比较两个数据集之间的关系。
以散点图为例,X轴可选 Copy Number,Y轴可选 mRNA expression。点击 Load Plot 后即可出图。正值通常提示表达上调,负值提示表达下调。
需要注意的是,这类图默认展示的是全部细胞系混合结果。如果不筛选组织来源,结论容易过于笼统。
2. 再学会从图里提炼有效结论
2.1 先按研究目的筛选样本
基因表达数据的价值,不在于“看见图”,而在于“找到可解释的模式”。如果你研究的是乳腺相关问题,就应优先筛选 breast 细胞系。CCLE 中可以通过点击某一类细胞系名称,单独显示对应数据。
这样做后,图上的点会明显更聚焦。鼠标悬停在点上,还能看到细胞系名称及对应坐标值。这一步能把“全局趋势”变成“特定背景下的真实差异”。
如果不筛选,混合样本会把关键信号稀释。对医学生和科研人员来说,最常见的错误不是不会画图,而是把所有样本当成同一生物学场景来解读。
2.2 再比较不同基因之间的关系
基因表达数据的分析不应只停留在单基因层面。CCLE 提供了 Different Gene 功能,可直接比较两个基因的数据关系。比如输入 TP53 和 METTL1,就可以在不同数据集之间建立对比。
这种方法适合回答更具体的问题。
- 某个基因的表达与拷贝数是否相关。
- 两个基因在同类细胞系中是否呈协同变化。
- 某些分子是否存在潜在调控关联。
当两个变量放在同一张图里时,研究假设就会更容易被验证。 这也是高质量基因表达数据分析和普通浏览式查看之间的最大区别。
2.3 再关注结果是否有组织特异性
同一个基因,在不同细胞系中表现可能完全不同。比如 TP53 的散点图结果,如果只看混合样本,结论会偏宽泛;如果只看 breast 细胞系,就能更接近乳腺研究场景。
因此,解读基因表达数据时要问自己三个问题。
- 这个表达变化发生在哪类细胞中。
- 是否只在特定组织来源中成立。
- 是否能被其他分子层面的数据支持。
只有同时满足“场景清楚、方向明确、逻辑闭环”,表达差异才更有说服力。
3. 最后把表达数据和其他分子信息合起来看
3.1 不要只盯着表达本身
基因表达数据只是其中一层。CCLE 中还可以联动查看突变、融合/异位、CpG甲基化等信息。对肿瘤研究而言,这些信息往往和表达强相关。
例如在 Mutation Data 页面,可以查看样本中的突变信息,还可通过筛选功能按关键词检索。结果中还能导出对应格式文件,便于进一步分析。如果一个基因表达异常,同时伴随突变或甲基化变化,机制解释就更完整。
3.2 甲基化和表达要一起解读
CpG Methylation Viewer 可以帮助观察目标基因在特定细胞系中的甲基化情况。气泡颜色代表甲基化程度,红色表示高甲基化,蓝色表示低甲基化,范围从 0 到 1。气泡大小则反映覆盖度。
这类信息对表达数据解读非常关键。因为启动子区或第一外显子附近的 CpG 甲基化,常与转录活性相关。高甲基化并不一定直接等于低表达,但它提供了重要的方向性证据。
对科研人员而言,这比单看表达箱线图更接近机制层面的判断。
3.3 用“表达-拷贝数-甲基化”建立闭环
一个完整的基因表达数据解读,通常至少要形成以下闭环。
- 表达是否改变。
- 改变是否与拷贝数一致。
- 是否伴随甲基化或突变信息。
如果三者之间能形成一致趋势,结论就更稳。若不一致,也不是失败,而是提示存在更复杂的调控层次。这正是分子肿瘤学和转化研究的价值所在。
在实际项目中,这种闭环分析尤其适合论文复现、候选基因筛选和机制预实验设计。它能帮助研究者从“看结果”转向“找原因”。
4. 三步法总结,快速掌握核心
4.1 第一步,确认对象
先确认基因名、Entrez ID 和数据类型。不要一上来就解释趋势。对象不准,后面全错。
4.2 第二步,看清背景
结合细胞系或组织来源筛选结果。再比较单基因与双基因关系,判断表达变化是否具有特异性。
4.3 第三步,整合证据
把表达和拷贝数、甲基化、突变一起看。只有多层证据相互支持,基因表达数据才真正具备研究价值。
对临床和科研工作者来说,这三步能显著提升分析效率,也能减少“只会看图,不会下结论”的问题。
总结Conclusion
基因表达数据并不难,难在解读是否规范。记住这三步。先确认对象,再看背景,最后整合多组学证据。这样才能从一张图,走到一个可信结论。
如果你希望更高效地完成基因表达数据分析、论文复现和候选基因筛选,可以借助解螺旋 的专业内容与科研服务,把复杂流程变成标准化路径。

- 引言Introduction
- 1. 先认清基因表达数据的基本结构
- 2. 再学会从图里提炼有效结论
- 3. 最后把表达数据和其他分子信息合起来看
- 4. 三步法总结,快速掌握核心
- 总结Conclusion



