引言Introduction
生信数据类型决定了你能做什么分析,也决定了文章能否成立。很多医学生和科研新人卡在第一步,不是不会跑流程,而是不知道生信数据类型 怎么分、怎么选、怎么对应研究问题。
1. 先弄清楚,生信数据类型为什么重要
1.1 数据类型不是一个概念,而是一组研究入口
在生信研究里,数据是起点。同样的分析方法,换了生信数据类型,结论可能完全不同。 这也是为什么文章解构时,先看数据来源,再看分子类型,再看实验平台。
从知识库内容看,医学方向的生信研究数据主要来自高通量实验,常见维度包括DNA、RNA和蛋白。进一步展开后,可以把生信数据类型 理解为不同层级、不同来源、不同平台的数据集合。
1.2 选对数据类型,才能匹配研究问题
生信研究不是“先有工具再找课题”,而是“先定问题,再定数据”。
如果是肿瘤机制挖掘,常用的是转录组或突变数据。
如果是预后模型,临床信息和表达矩阵就更关键。
如果是调控网络分析,miRNA、lncRNA、mRNA数据就会成为主线。
一句话:数据类型选错,后面所有分析都会偏。
2. 生信数据类型有哪5类?
2.1 DNA类数据
DNA类数据是最基础的组学数据之一,核心关注基因组层面的变化。知识库提到的代表包括Mutation突变、Methylation甲基化和SNP单核苷酸多态性 。
这类数据常用于:
- 肿瘤驱动基因筛选
- 基因变异与疾病风险分析
- 甲基化位点和表型关联
- 遗传易感性研究
DNA类数据的优势是稳定,适合做“上游原因”的探索。
它的局限也很明显,不能直接反映当前的表达状态。
2.2 RNA类数据
RNA类数据是当前生信研究最常见的数据类型之一。它主要包括mRNA和非编码RNA ,比如miRNA、lncRNA、circRNA。
这类数据通常用于:
- 差异表达分析
- ceRNA网络构建
- 功能富集分析
- 生存分析和预后建模
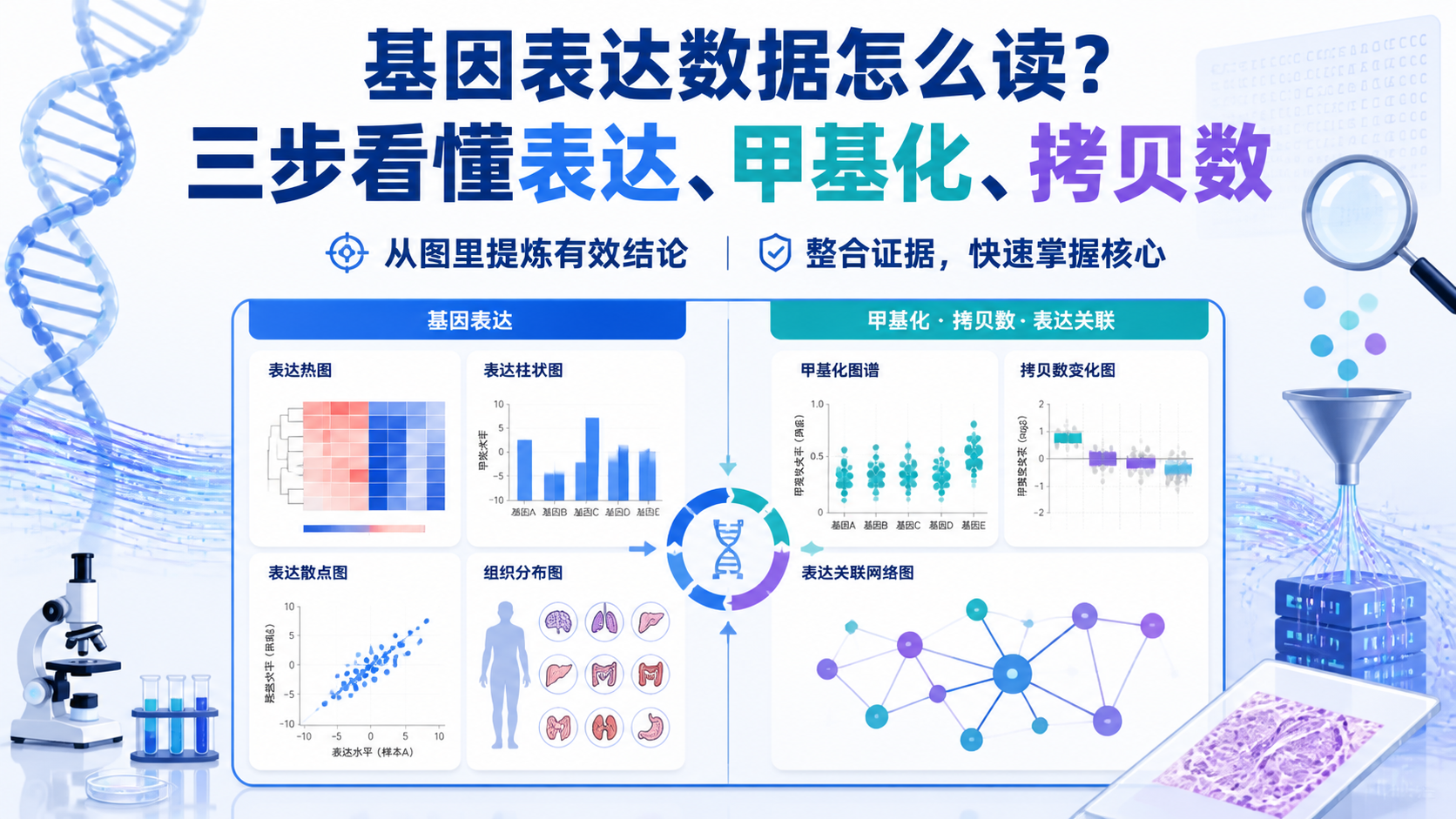
知识库中多次强调,表达差异分析是所有生信研究必不可少的第一步基础分析 。先筛出上调和下调分子,再进入网络、功能和临床模块,这是典型路径。
2.3 蛋白类数据
蛋白类数据关注的是表达结果的最终执行层。转录并不等于翻译,RNA水平高,不一定代表蛋白水平也高。
蛋白组数据常用于:
- 标志物筛选
- 信号通路验证
- 药物靶点研究
- 蛋白互作网络分析
在知识库里提到,质谱可以解决蛋白和代谢物检测。相比RNA数据,蛋白数据更接近功能表型,但公开资源相对少一些。
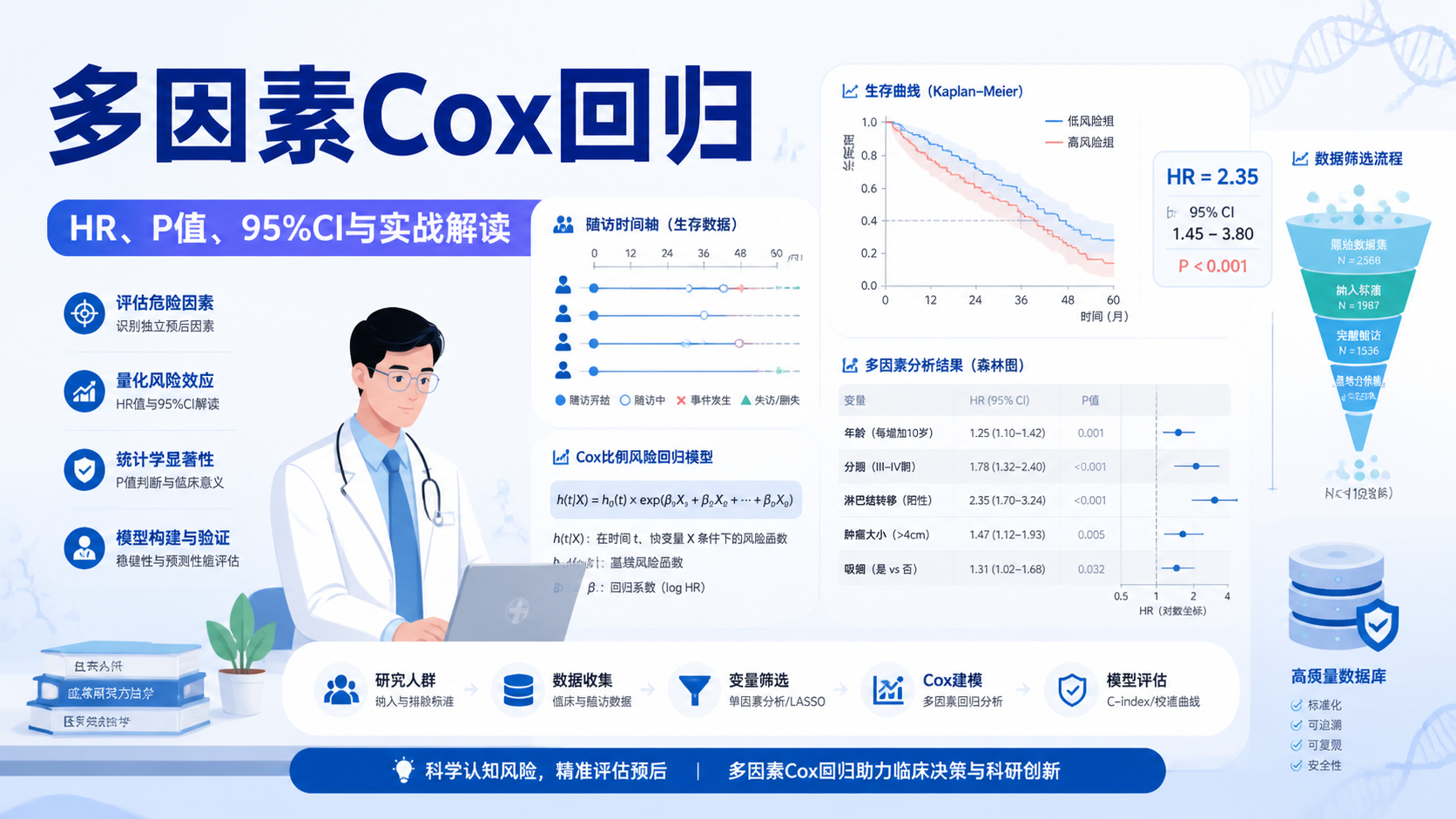
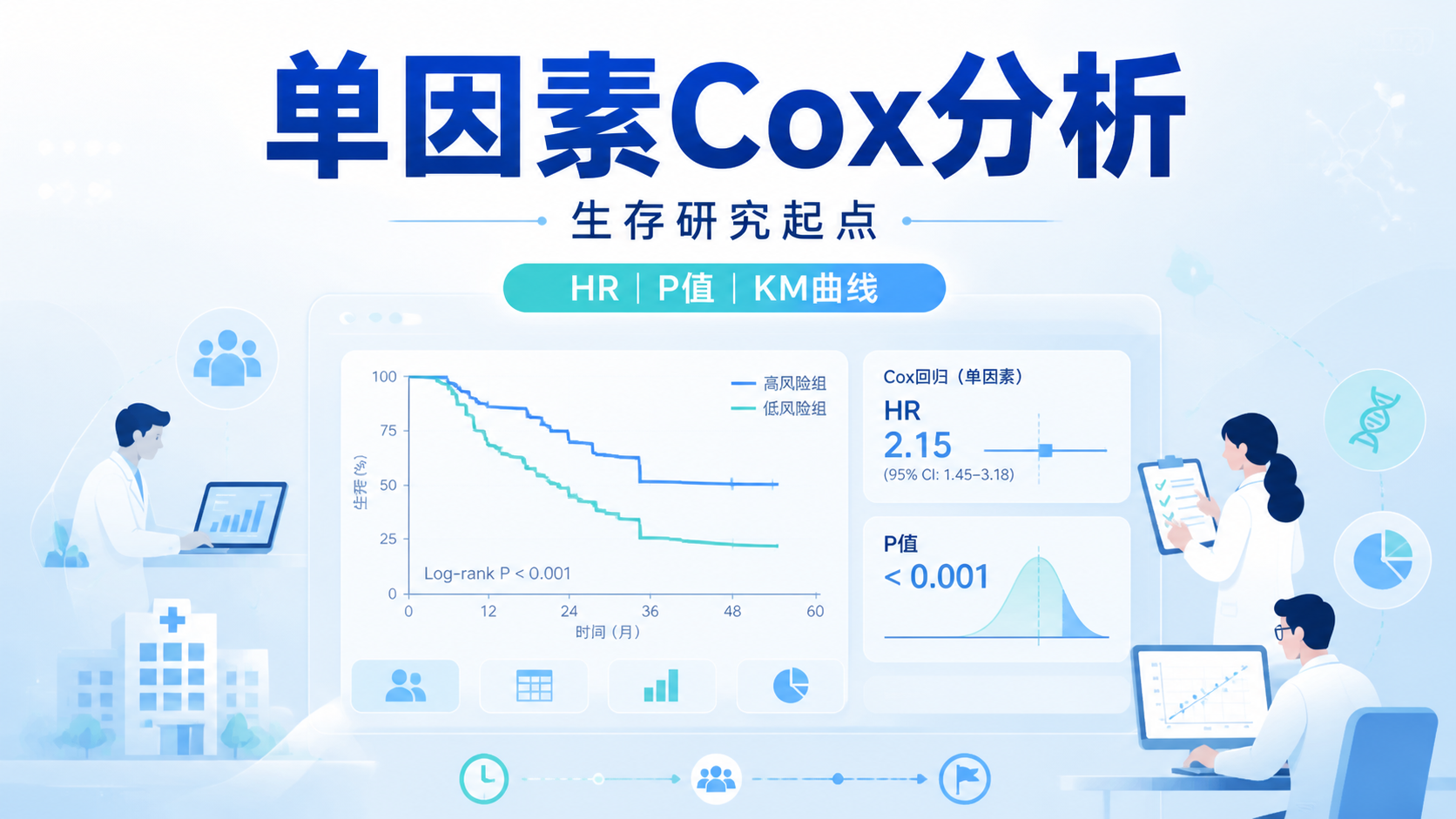
2.4 临床表型数据
临床数据是生信研究中常被低估的一类数据。它不是分子数据,但在文章中非常关键。知识库里提到,临床研究文章本质上是按照PICOS 原则组织的,而生信文献检索中的“靠”,也包括三表一图和临床预测模型。
临床表型数据常见于:
- 年龄、性别、分期
- 生存时间、结局事件
- 治疗反应
- 复发、转移信息
这类数据的作用是把分子发现落到临床意义上。
没有临床表型,很多生信结果只能停留在“相关”,难以进入“可用”。
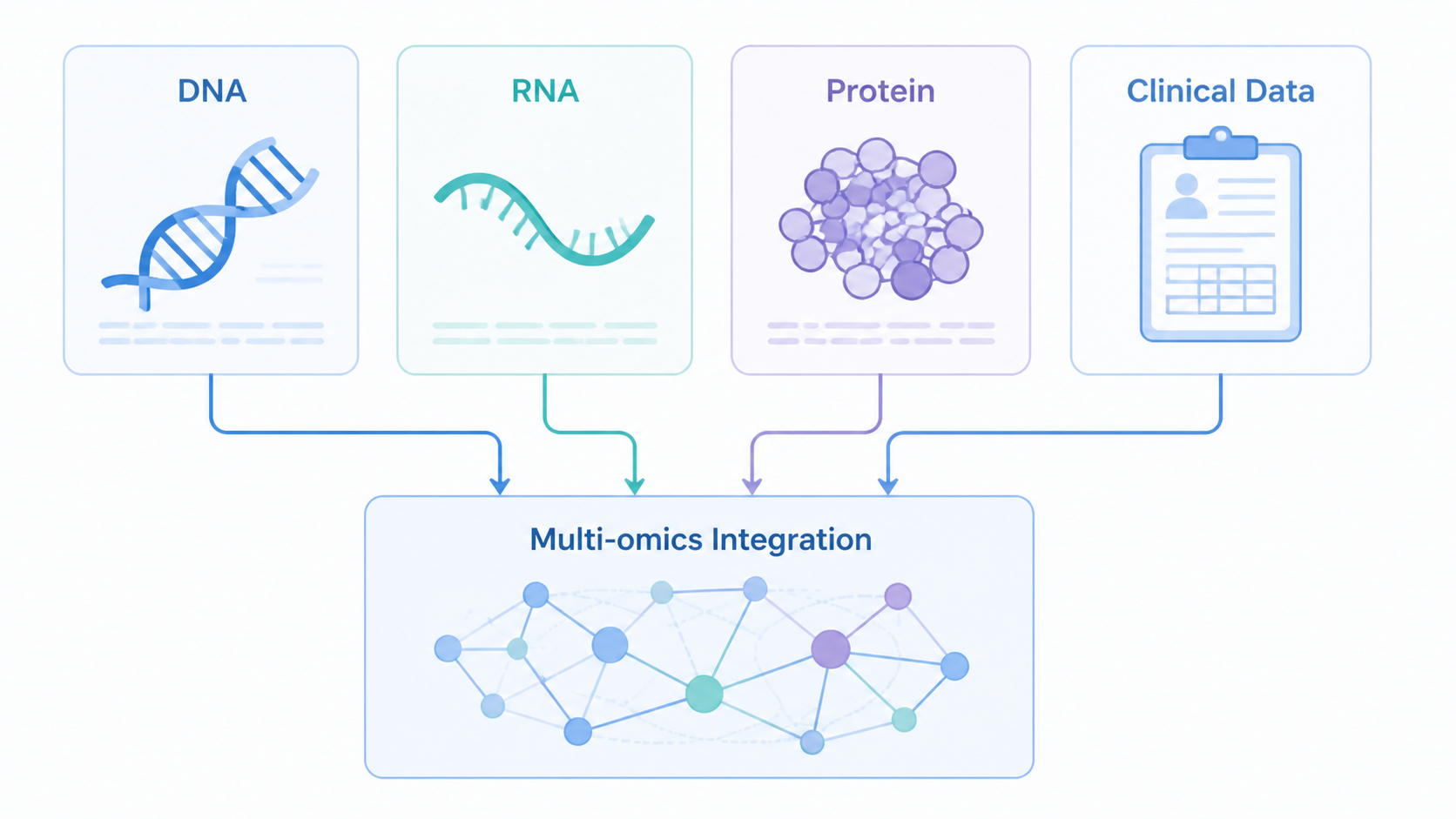
2.5 多组学整合数据
第五类可以理解为多组学整合数据。它不是单一数据源,而是把DNA、RNA、蛋白,甚至临床数据放在一起分析。
知识库中的观点很明确:生信研究擅长处理多数据层次、多靶点、多表型的复合问题。 这正是多组学的优势所在。
常见用途包括:
- 找到更稳定的候选靶点
- 提升模型预测能力
- 从多个层面验证同一结论
- 构建更完整的疾病机制链条
对科研写作来说,多组学整合往往更容易形成“模块叠加”的文章结构,也更符合高质量论文的逻辑。
3. 不同生信数据类型,对应什么分析模块?
3.1 表达差异分析是第一步
不管是哪类数据,很多生信文章都会先做表达差异分析。知识库把它称为“挑”,也就是筛出差异分子。
常见结果包括:
- 上调分子
- 下调分子
- 无显著变化分子
差异分析的意义不是出图,而是缩小研究范围。
只有先找到差异分子,后面的聚类、网络、临床分析才有对象。
3.2 聚类、网络和临床分析是延伸模块
在模块化思路里,生信研究常见四类分析模块:
- 表达差异
- 聚类分析
- 交互网络
- 临床意义
不同的数据类型,决定你能做哪些模块。
例如RNA数据适合做ceRNA网络,蛋白数据更适合互作网络,临床数据则用于预后模型和风险分层。
3.3 数据来源和平台也属于数据类型的一部分
知识库还特别强调,数据特征不仅看分子类型,还要看:
- 数据来源,是内部数据还是外部数据库
- 检测分子类型,是蛋白、miRNA、lncRNA还是circRNA
- 实验方法,是芯片、测序还是质谱
这意味着,生信数据类型不是单独看“是什么”,还要看“怎么来” 。
同样是RNA数据,测序和芯片就不是完全一样的研究入口。
4. 选生信数据类型时,最常见的3个判断标准
4.1 先看研究问题
如果研究问题是机制,优先考虑分子层数据。
如果研究问题是预后,优先考虑表达数据加临床数据。
如果研究问题是遗传背景,DNA类数据更合适。
4.2 再看数据是否充足
知识库明确提到,数据是生信的水源 。
有些疾病样本少,取材难,公开数据也少,这会直接限制可分析范围。相反,肿瘤方向数据更丰富,分析模块也更成熟。
4.3 最后看分析策略是否匹配
生信是“工具驱动”的研究。
你不是为了数据而做数据,而是为了结论选择数据。
如果目标是构建ceRNA网络,那就需要mRNA、miRNA、lncRNA这类RNA数据。
如果目标是突变分析,那就需要DNA层数据。
5. 写作和检索时,如何快速识别生信数据类型?
5.1 看题目中的两个恒量和两个变量
知识库指出,生信类研究常用“两恒量两变量”理解。
两恒量是疾病和问题。
两变量是数据特征和分析策略。
所以读题时,先判断:
- 研究什么疾病
- 解决什么问题
- 用什么数据
- 采用什么策略
这一步决定你能否快速看懂一篇生信文章。
5.2 看摘要里的关键名词
摘要里如果出现这些词,往往就能判断数据类型:
- mutation, methylation, SNP
- mRNA, miRNA, lncRNA, circRNA
- proteomics, mass spectrometry
- clinical prognosis, survival analysis
这些词基本能锁定文章的数据入口。
对文献检索来说,这也能帮助你构建更准确的检索式。
5.3 看图表结构
如果文章先给火山图、热图,再给网络图和生存曲线,通常说明它是典型RNA生信文章。
如果先做突变谱,再做通路和预后,通常说明它依赖DNA层数据。
图表顺序,本身就是数据类型的线索。
结尾Conclusion
总结来看,生信数据类型 至少可以从DNA、RNA、蛋白、临床表型和多组学整合五个层面去理解。不同类型对应不同问题、不同平台和不同分析模块。对医学生、医生和科研人员来说,真正重要的不是背分类,而是学会根据研究目的选数据。
如果你希望更快掌握生信数据类型 的选题、检索和文章拆解逻辑,可以进一步借助解螺旋的体系化课程与工具,把“会看数据”变成“会做课题”。
掌握数据类型,就是掌握生信文章的第一入口。

- 引言Introduction
- 1. 先弄清楚,生信数据类型为什么重要
- 2. 生信数据类型有哪5类?
- 3. 不同生信数据类型,对应什么分析模块?
- 4. 选生信数据类型时,最常见的3个判断标准
- 5. 写作和检索时,如何快速识别生信数据类型?
- 结尾Conclusion