引言Introduction
多因素cox是临床随访研究里最常用的多变量生存分析方法。很多人会做单因素分析,却卡在变量筛选、PH假定和HR解释上。如果模型步骤不规范,结果很容易失真。 
1. 为什么要做多因素cox
1.1 单因素分析不够回答真实问题
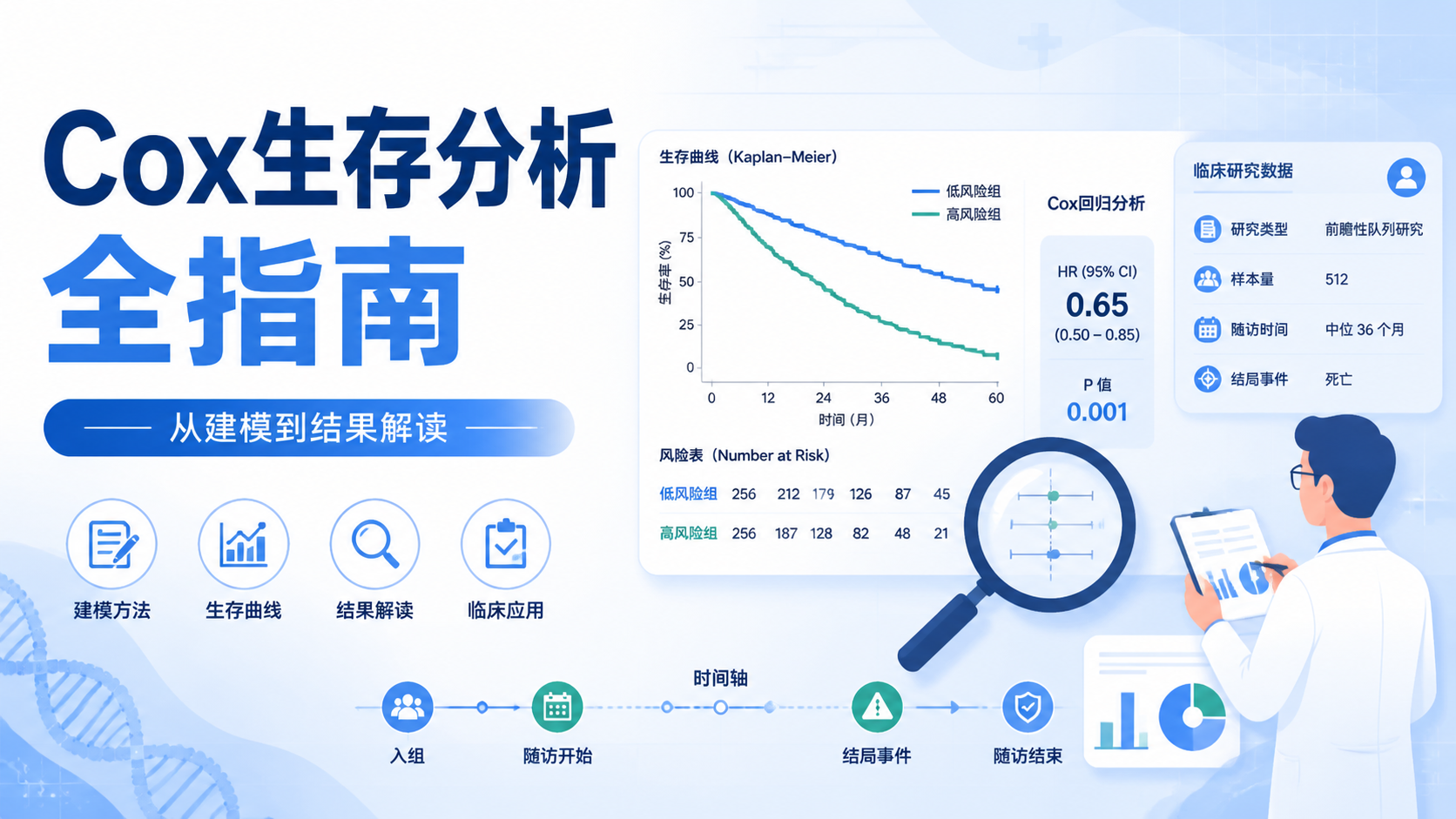
生存结局通常受多个因素共同影响。比如肿瘤患者的生存时间,可能同时受治疗方式、年龄、病情分期、体能状态影响。单个KM曲线或log-rank检验,只能比较组间差异,不能同时控制多个混杂因素。
这就是多因素cox的价值。它把生存时间和结局作为因变量,把多个协变量一起纳入模型,评估每个因素在其他变量不变时,对风险的独立影响。
1.2 Cox回归适合随访数据
Cox模型的优势很明确。第一,它允许删失数据。第二,它不要求生存时间服从正态分布。第三,它重点分析的是风险函数,而不是直接拟合生存时间。
从知识库中的定义看,Cox回归是生存分析中最重要的多因素分析方法之一 。这也是它在临床研究、预后研究和疗效评价中被广泛使用的原因。
2. 多因素cox模型的基本原理
2.1 先理解风险函数
Cox模型核心是风险函数 h(t)。它表示某个个体在时刻 t 的瞬时死亡风险。模型写成:
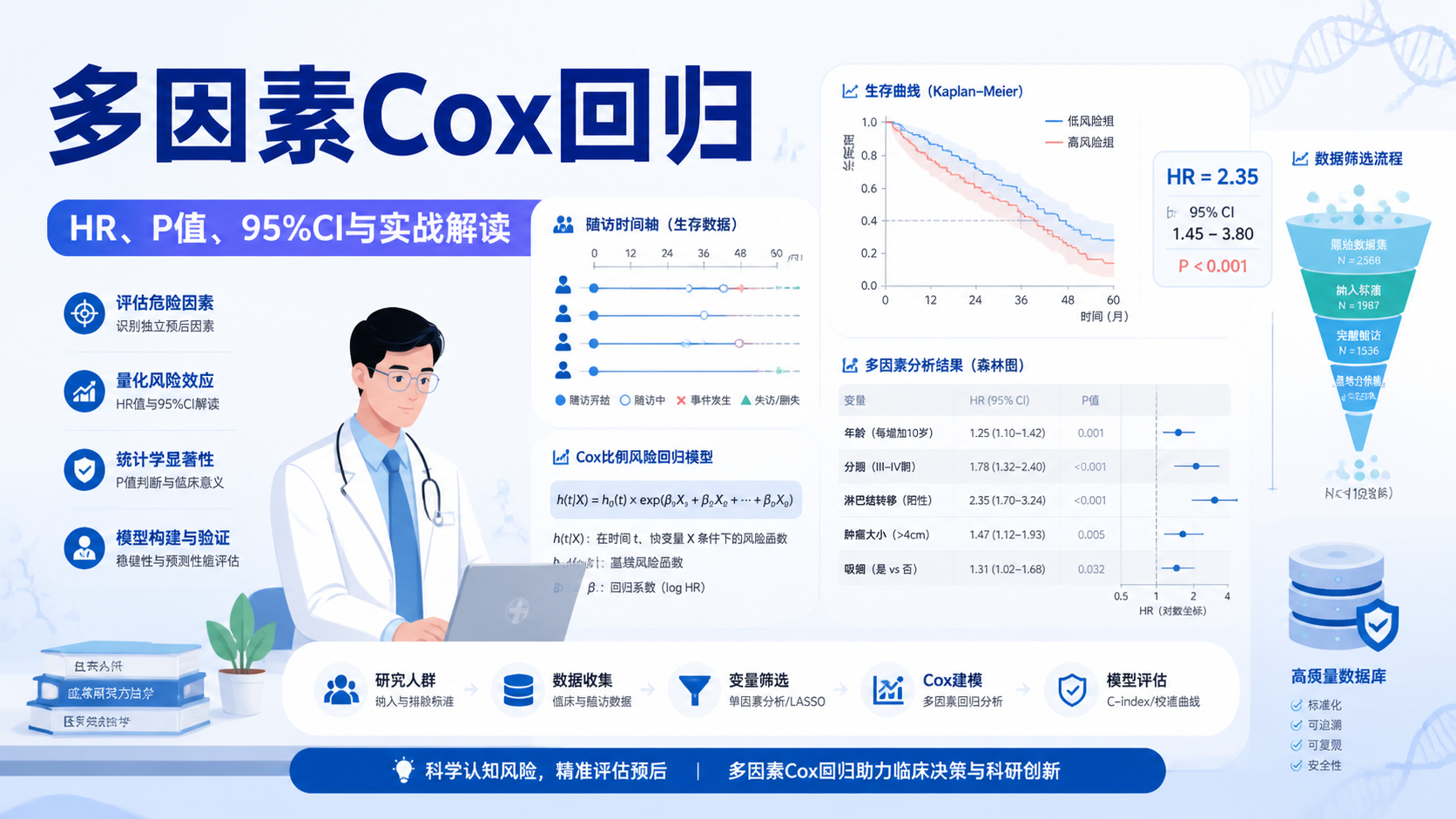
h(t,x)=h0(t)×exp(β1x1+β2x2+…+βpxp)
其中 h0(t) 是基准风险函数,β 是回归系数。Cox模型的特点是,基准风险函数不需要明确给出,因此它属于半参数模型。
2.2 HR值怎么解释
多因素cox最常看的指标是 HR。它表示风险比。
- HR > 1,提示该变量可能是危险因素。
- HR < 1,提示该变量可能是保护因素。
- HR = 1,提示与结局无明显关联。
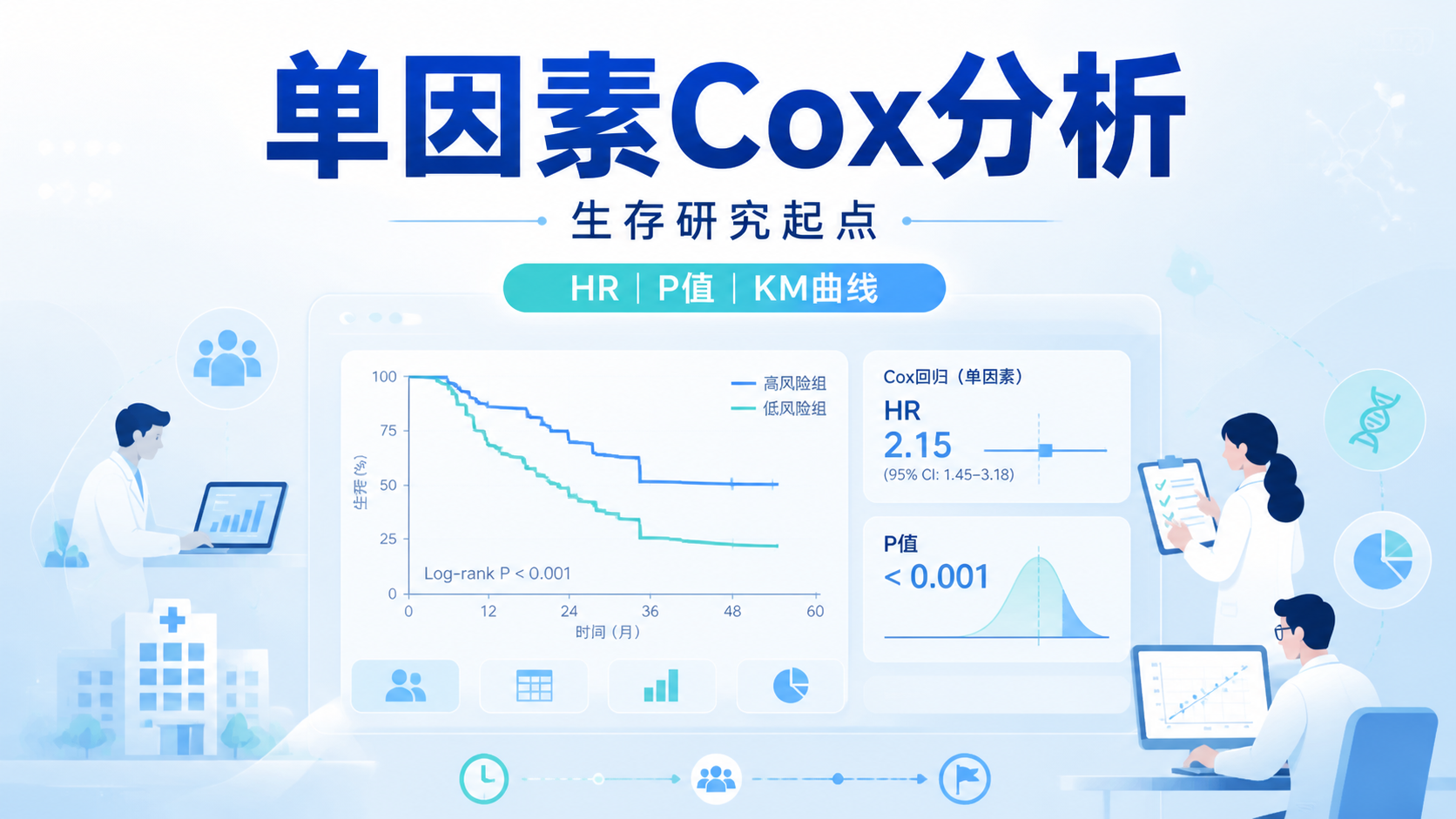
例如在知识库的 lung 数据示例里,性别在单因素分析中的 HR 为 0.5864,表示女性死亡风险低于男性。多因素模型后,性别 HR 约为 0.5643,说明在调整年龄和 ecog 评分后,这种差异仍然存在。
3. 多因素cox怎么做
3.1 第一步,先做数据准备
真正建模前,先处理变量和缺失值。常见流程包括:
- 明确结局变量。一般是生存时间和生存状态。
- 选择候选协变量。临床变量、实验室指标、分组变量都可以考虑。
- 删除或处理缺失值。
- 检查变量类型。分类变量要正确编码,连续变量要确认量纲。
数据准备是否规范,直接决定多因素cox的可信度。 如果变量编码错误,HR 的方向都可能反掉。
3.2 第二步,先做单因素筛选
在实际研究中,常见做法是先进行单因素 Cox 分析,再把具有统计学意义的变量纳入多因素模型。知识库中 lung 数据示例显示,性别、年龄、ph.ecog 在单因素分析中有统计学意义,而 wt.loss 不显著。
不过要注意,单因素筛选只是常见策略,不是绝对规则。 有些重要混杂因素,即使单因素不显著,也可能因为临床意义强而应保留在多因素模型中。
3.3 第三步,拟合多因素模型
多因素cox通常使用 coxph() 建模。形式上,就是把多个自变量同时放入公式中。例如:
Surv(time, status) ~ sex + age + ph.ecog
这一步的关键不是代码,而是变量进入模型的逻辑。协变量应当与结局关系明确,且避免把高度共线的变量同时纳入。
4. 结果怎么解读才不出错
4.1 先看P值,再看HR和95%CI
多因素cox输出里,通常要同时看三项:
- P值,判断统计学意义。
- HR,判断效应方向和大小。
- 95%CI,判断估计是否稳定。
如果 95%CI 跨过 1,通常提示结果不稳定或未达显著性。临床解释时,不能只看 P 值。
4.2 结合临床意义解释
在 lung 数据示例中,多因素分析后,性别和 ph.ecog 仍有统计学意义,而年龄不再显著。这个结果说明,年龄在单因素中看似有影响,但在控制其他因素后,其独立效应减弱。
这类现象很常见。多因素cox的目的,就是把“表面相关”筛成“独立相关”。 对医生和科研人员来说,这比单因素结论更接近真实临床机制。
4.3 连续变量的解释要量化
连续变量不要只写“升高”或“降低”。要明确单位。
例如年龄每增加 1 岁,风险如何变化。ph.ecog 每增加 1 分,风险如何变化。这样的表达更符合科研写作规范,也更利于论文结果部分呈现。
5. 必须检查的两个前提
5.1 比例风险假定
这是 Cox 模型最重要的前提之一。比例风险假定要求,不同协变量的风险比在随访期间保持相对恒定。
最简单的初筛方法,是看分组后的 Kaplan-Meier 曲线。如果曲线明显交叉,通常提示不满足比例风险假定。如果曲线大致平行,则可初步认为成立。
知识库中还提到,可以用 cox.zph() 做统计学检验。若 P 值大于 0.05,通常说明该变量满足 PH 假定。
5.2 对数线性假定
另一个前提是协变量与对数风险比之间应呈线性关系。如果连续变量和风险之间关系明显非线性,直接做多因素cox可能会低估或高估真实效应。
因此,建模前最好先做基础图形检查,必要时考虑分层、变换或加入交互项。对于不满足假定的变量,不能直接套用标准 Cox 模型。
6. 常见错误与实战建议
6.1 不要把相关当因果
多因素cox能控制混杂,但不能自动证明因果关系。它回答的是“在当前数据和模型下,哪些因素独立相关”,不是因果终点。
6.2 不要忽视删失与事件数
事件数太少时,多因素模型容易不稳定。临床研究中,如果自变量很多而事件数有限,HR 会飘,置信区间也会变宽。变量数要和事件数匹配。
6.3 不要省略模型诊断
很多结果问题不是出在公式,而是出在诊断。至少要检查:
- PH 假定
- 变量编码
- 缺失值处理
- 共线性风险
- 模型是否过度拟合
总结Conclusion
多因素cox不是简单把变量一起放进模型。它的关键在于,先明确研究问题,再规范筛选变量,随后检查 PH 假定和对数线性关系,最后结合 HR、P 值和 95%CI 做临床解释。
对医学生、医生和科研人员来说,真正高质量的多因素cox分析,应该同时满足统计学正确和临床解释合理。如果你希望更高效地完成生存分析建模、结果解读和论文写作,可以使用解螺旋的相关课程与工具,按标准流程减少建模误差,提高研究效率。 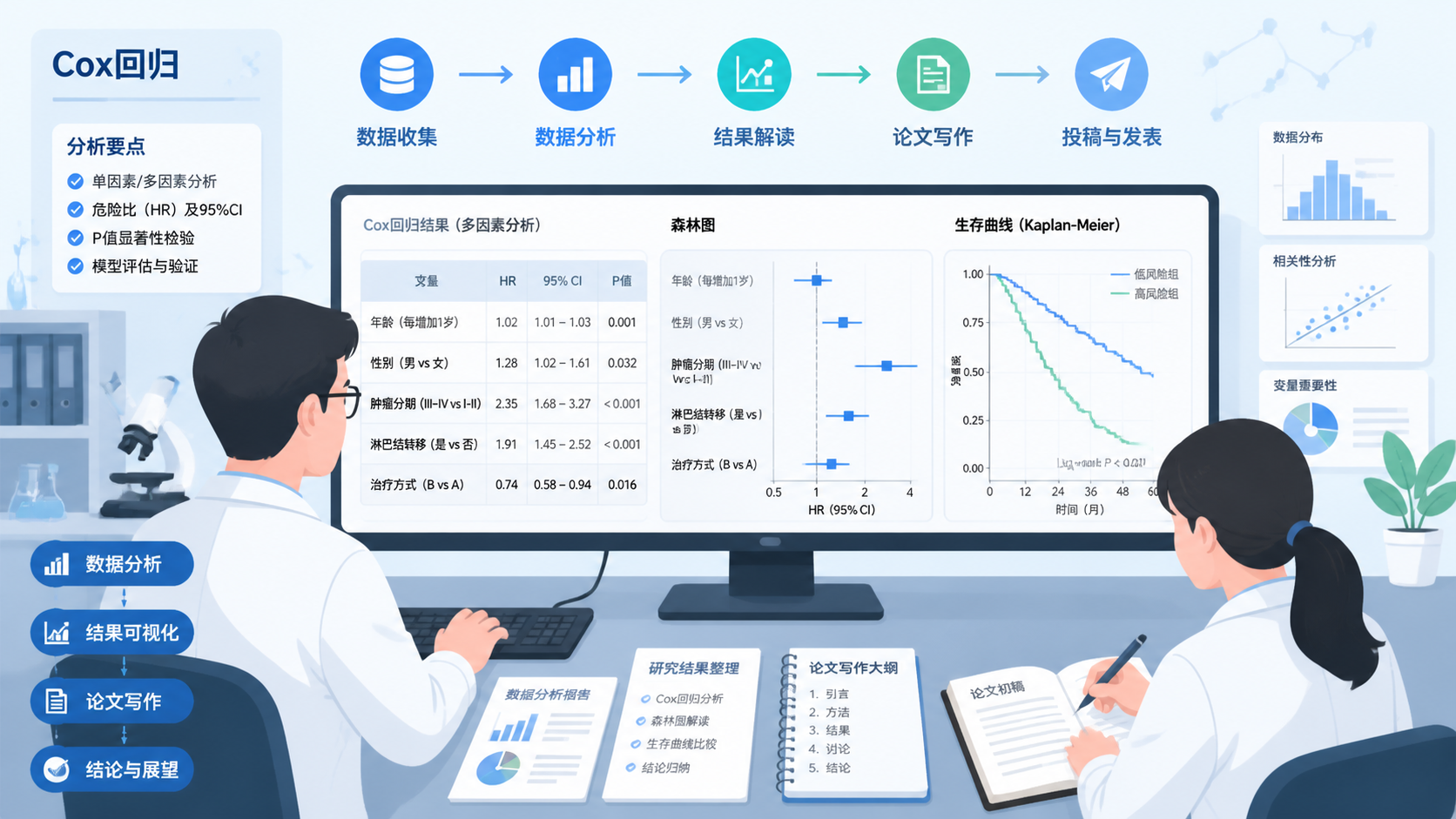
- 引言Introduction
- 1. 为什么要做多因素cox
- 2. 多因素cox模型的基本原理
- 3. 多因素cox怎么做
- 4. 结果怎么解读才不出错
- 5. 必须检查的两个前提
- 6. 常见错误与实战建议
- 总结Conclusion