引言Introduction
做Cox生存分析时,很多人卡在三件事:数据格式不对、变量筛选混乱、结果解释不到位。cox生存分析的核心,不只是跑出HR,更是判断哪些因素真正影响生存结局。 本文结合临床研究常见流程,帮你把模型思路、变量解读和实操步骤理清。
1. 先理解Cox生存分析到底解决什么问题
1.1 为什么不能直接用普通回归
随访研究里,结局通常不只有“发生或未发生”,还有生存时间 。这意味着同样是未发生事件的人,有的人随访了3个月,有的人随访了3年,信息量完全不同。普通多元回归很难处理这种时间维度。
另外,临床数据常有删失。比如失访、研究终止、死于其他原因。如果把删失简单当成死亡或存活,都会引入偏倚。 这也是cox生存分析被广泛使用的原因。
1.2 Cox模型的基本思想
Cox比例风险模型把风险分成两部分。
一部分是基线风险,记作 (h_0(t))。
另一部分是协变量带来的相对影响,记作 (exp(\beta X))。
换句话说,模型关注的是:在任意时间点,某个因素会让风险增加还是降低,以及增加或降低多少。
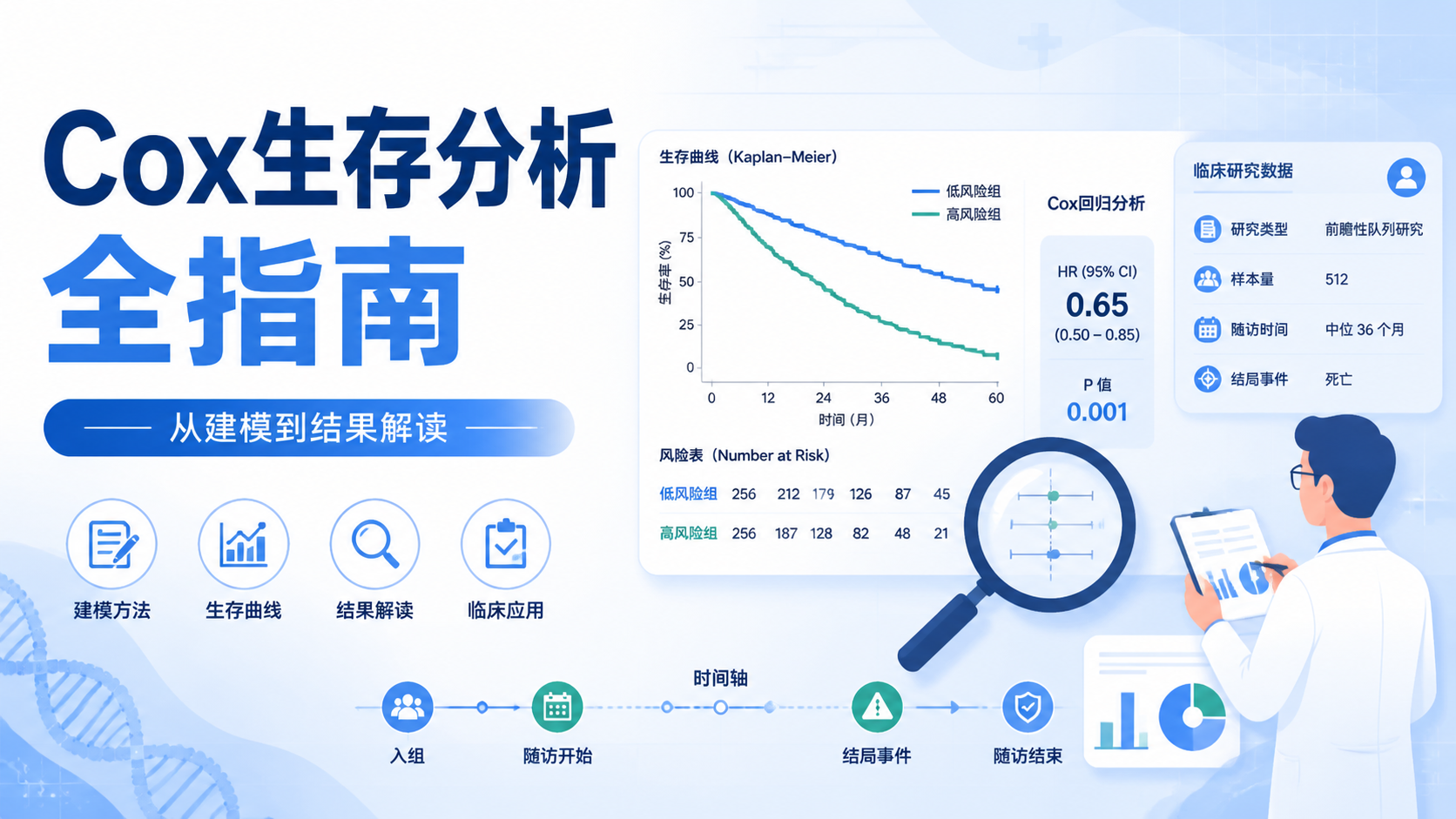
这里的HR,就是风险比。
- HR > 1,提示危险因素
- HR < 1,提示保护因素
- HR = 1,提示无明显关联
2. 做好Cox生存分析前,数据必须先整理对
2.1 明确三类核心变量
在cox生存分析里,最少要准备三类变量:
- 生存时间 ,如time。
- 结局状态 ,如status。
- 协变量 ,如年龄、性别、分期、治疗方式、评分等。
其中,状态变量最容易出错。以常见生存数据为例,需明确哪个编码代表事件发生,哪个编码代表删失。编码方向一旦错,结果会完全反。
2.2 先做缺失值和变量筛查
建模前建议先做三步:
- 检查缺失值。
- 统一分类变量编码。
- 删除明显不合理值。
知识库案例中,先从原始数据中提取需要的列,再用na.omit()删除缺失行,最终样本量变为213。这个步骤看似简单,但对cox生存分析非常关键。模型的稳定性,往往从数据清洗开始。
2.3 先单因素,再多因素
临床研究里,一般先做单因素Cox分析,再纳入多因素模型。
单因素的目的有两个:
- 初筛与结局相关的变量。
- 判断变量方向和大致效应量。
多因素的目的则是控制混杂。只有在多因素模型中仍显著的变量,才更有资格被认为是独立影响因素。
3. Cox生存分析的标准建模流程
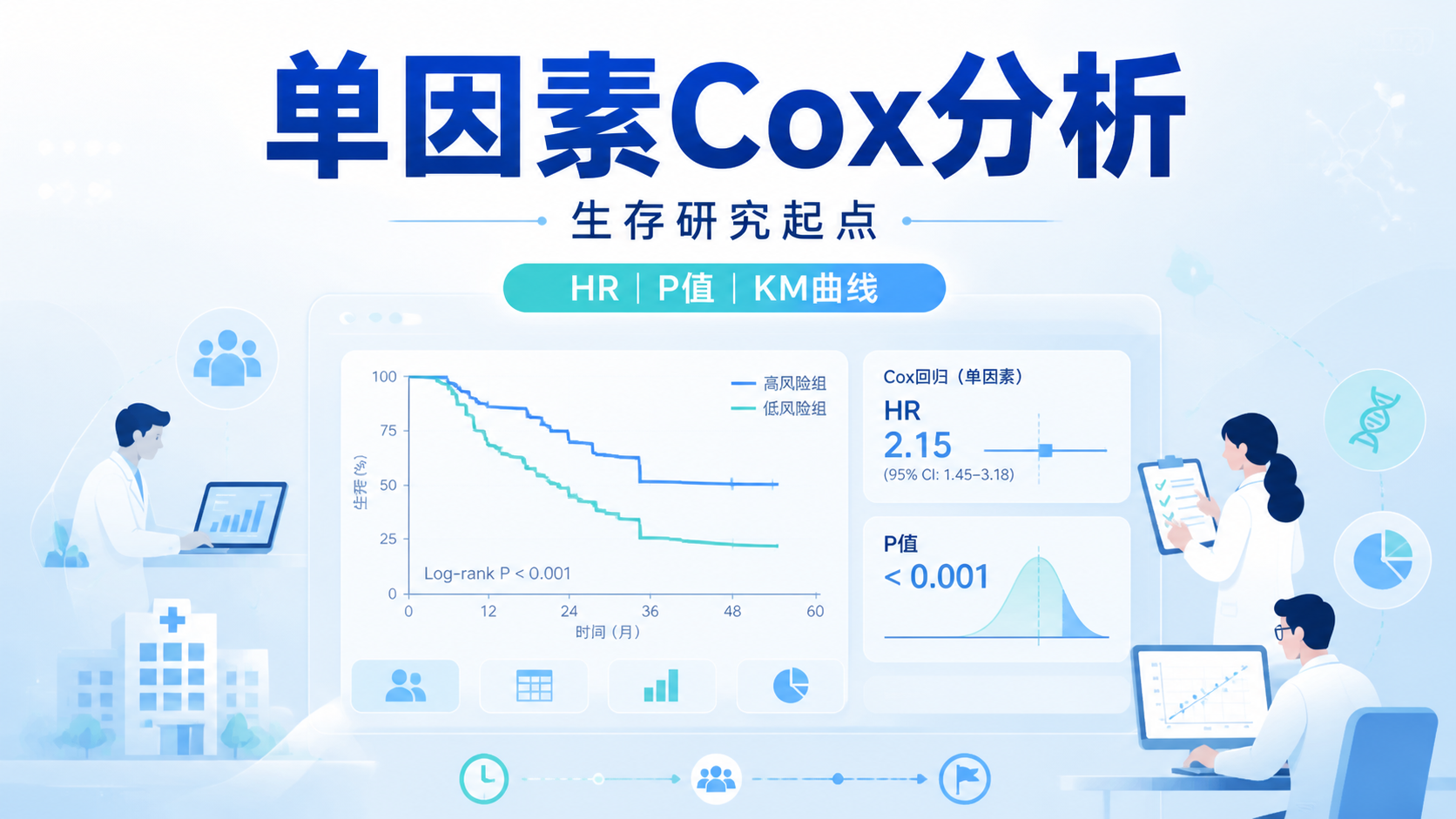
3.1 第一步,先做单因素分析
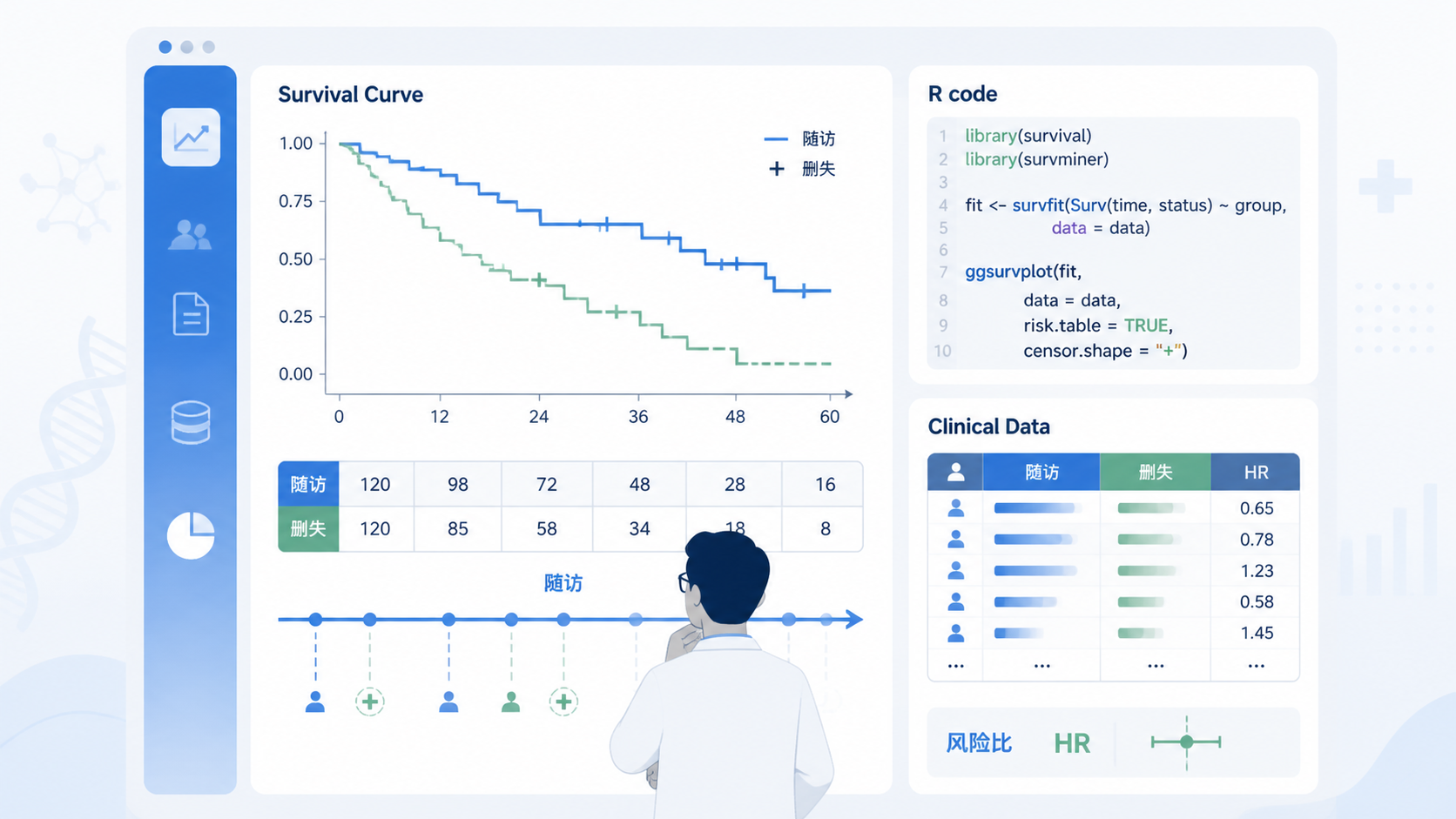
在R中,常用coxph()函数。
因变量通常写成Surv(time, status)的形式,再接自变量。
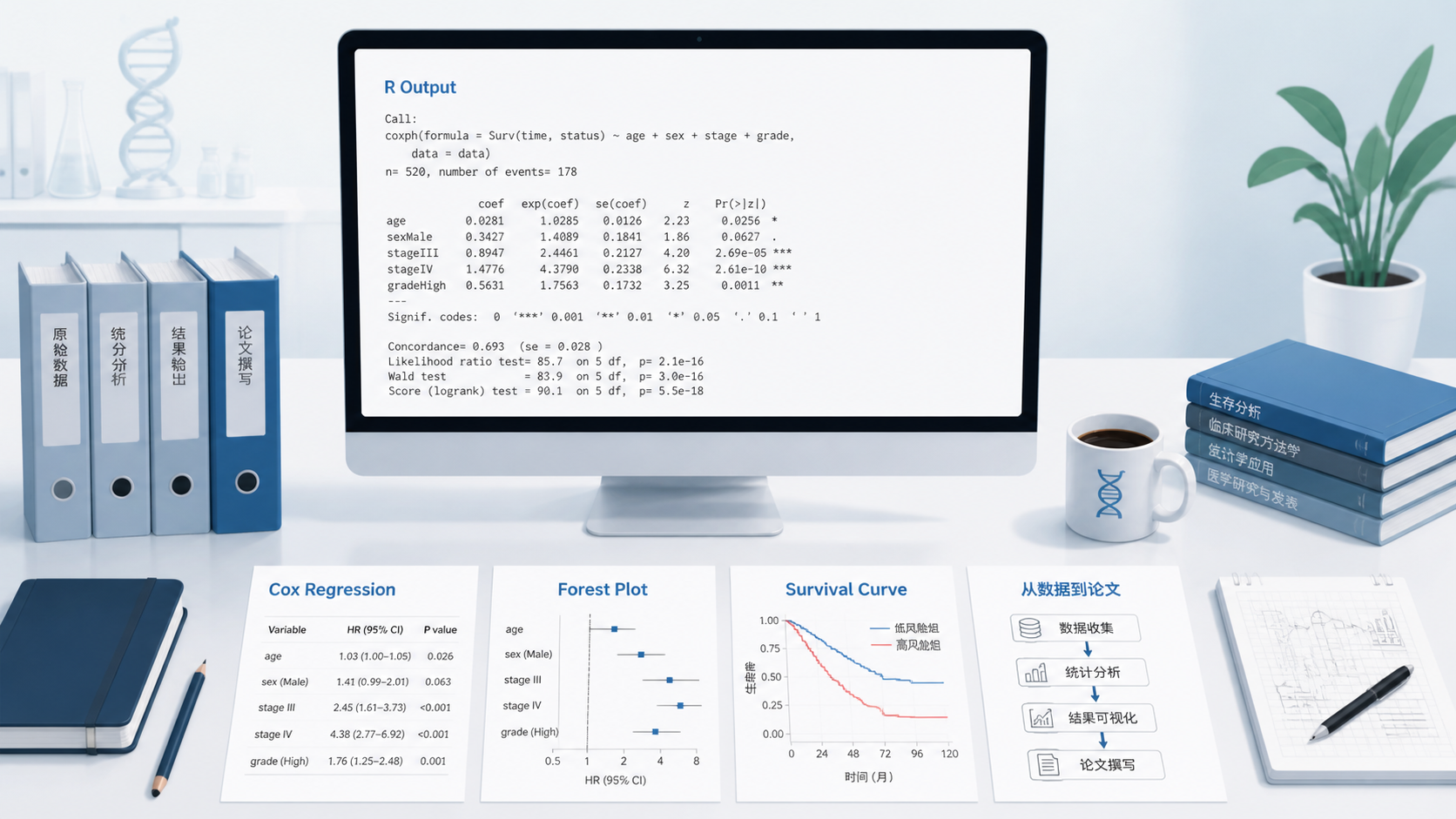
知识库案例中,分别检验了性别、年龄、ph.ecog和wt.loss。结果显示:
- 性别:P = 0.0022,HR = 0.5864。
- 年龄:P = 0.0229,HR = 1.022。
ph.ecog:P = 6.78×10⁻⁵,HR = 1.603。wt.loss:P = 0.925,无统计学意义。
这一步告诉我们,性别、年龄和ph.ecog更值得进入多因素模型。
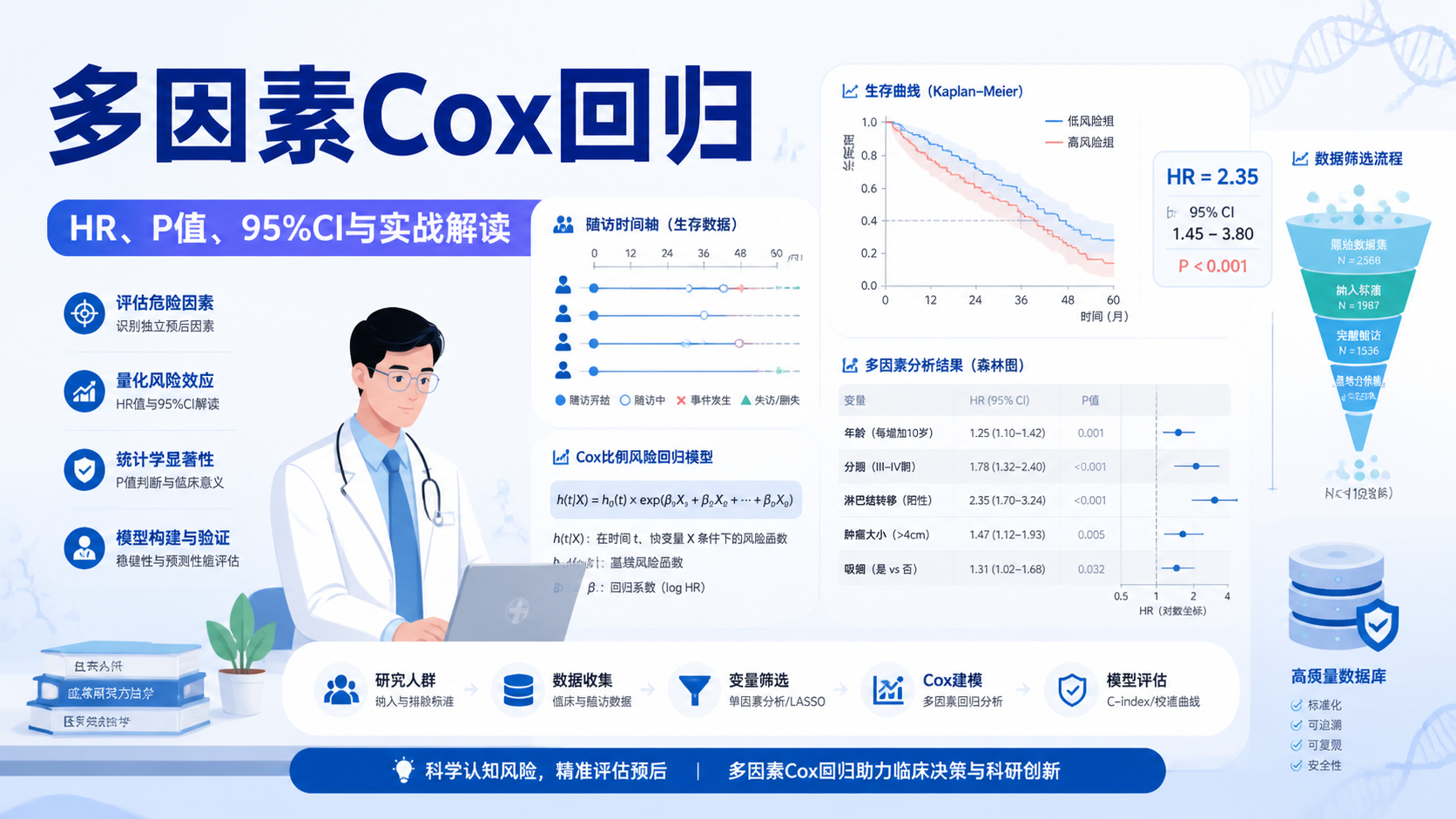
3.2 第二步,建立多因素模型
多因素模型把多个协变量一起放入同一个coxph()中。
这样可以看出某个变量在控制其他因素后,是否仍然影响生存。
知识库案例里,多因素结果显示:
- 性别仍显著,HR = 0.5643。
ph.ecog仍显著,HR = 1.5786。- 年龄不再显著,P > 0.05。
这说明年龄在单因素中看似有关,但在控制其他变量后,其独立效应减弱。这就是多因素分析的价值:区分“相关”与“独立相关”。
3.3 第三步,检查比例风险假设
Cox模型有一个前提:比例风险假设成立。
也就是各组间的风险比在整个随访期间大体保持恒定。
知识库中使用cox.zph()检验。结果显示各变量及整体P值均大于0.05,说明满足PH假定。
这是必须检查的一步。如果PH假定不成立,就不能直接解释Cox结果。
4. 结果该怎么读,才符合临床研究写作规范
4.1 重点看三项:HR、95%CI、P值
论文和报告中,Cox结果通常要同时给出:
- 回归系数β
- HR值
- 95%置信区间
- P值
其中,HR最直观,但不能单独看。
如果95%CI跨过1,通常提示统计学意义不足。
如果P < 0.05,且CI不跨1,结果更稳妥。
4.2 解释要结合临床语境
例如知识库中的性别结果,HR = 0.5864。
可以解释为:女性的死亡风险约为男性的0.5864倍,提示女性风险更低。
年龄HR = 1.022,表示年龄每增加1岁,死亡风险增加约2.2%。
ph.ecogHR = 1.603,表示评分每增加1分,死亡风险增加约60.3%。
解释时不要只说“有意义”,要说清楚方向、幅度和临床含义。
4.3 不要忽略“无效变量”
很多人只盯着显著结果。其实不显著变量同样重要。
比如知识库里的wt.loss,P = 0.925,说明在该数据集中没有观察到明确关联。
这有助于你避免过度解读。严谨的Cox生存分析,不只是找显著,更是避免伪显著。
5. 高效完成Cox生存分析的实用建议
5.1 建模前先定好研究问题
先明确你要回答的是:
- 哪些因素影响生存?
- 哪个治疗方式更优?
- 某个标志物是否是独立预后因素?
问题不同,变量纳入策略不同。
不要一上来就把所有变量塞进模型。
5.2 分类变量要处理好
性别、分期、病理类型、治疗方案,这些往往是分类变量。
在建模前要确认编码方式。
如果是多分类变量,还要设定参照组。
参照组不同,HR解释也不同。
5.3 先做探索,再做模型
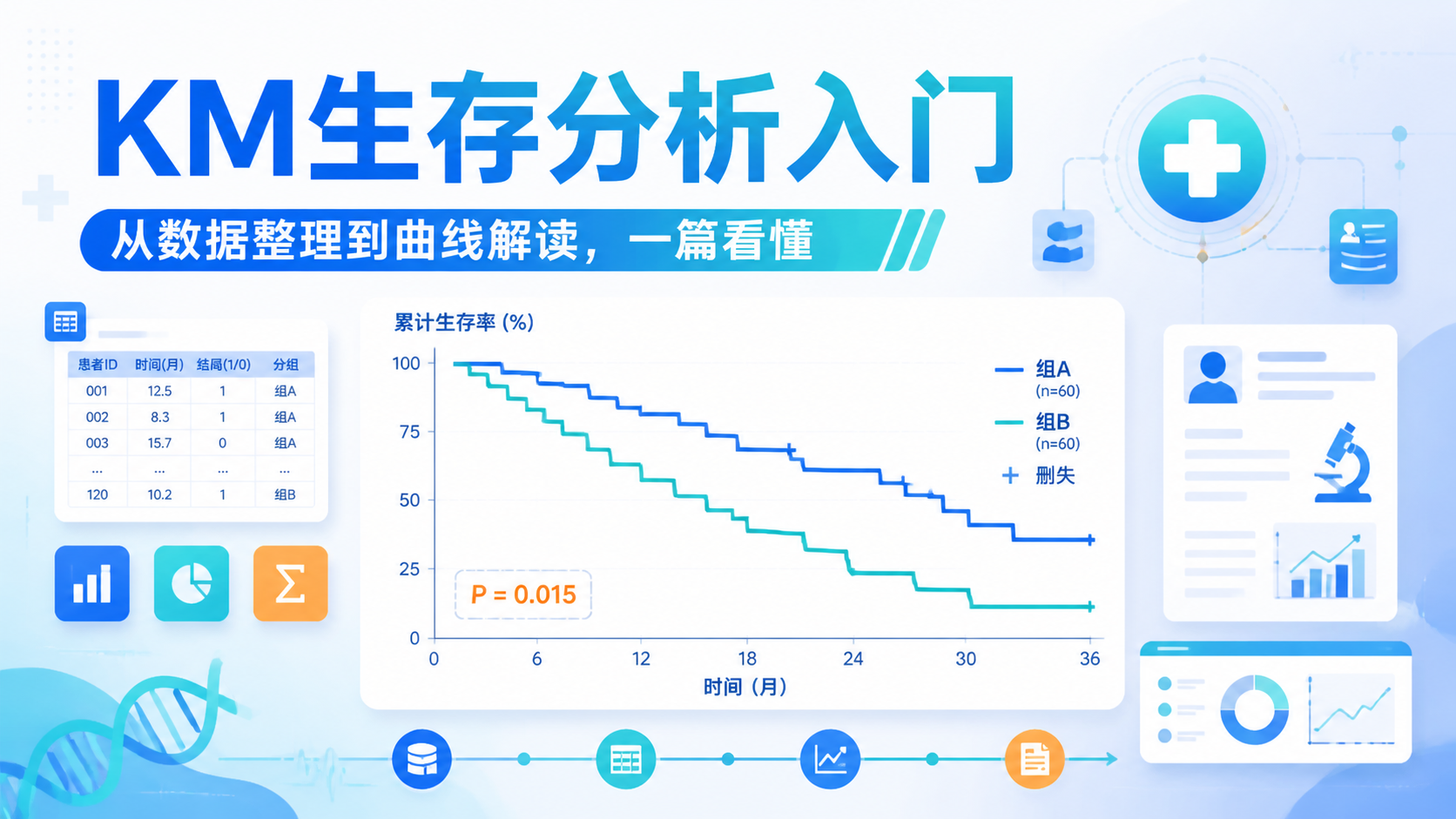
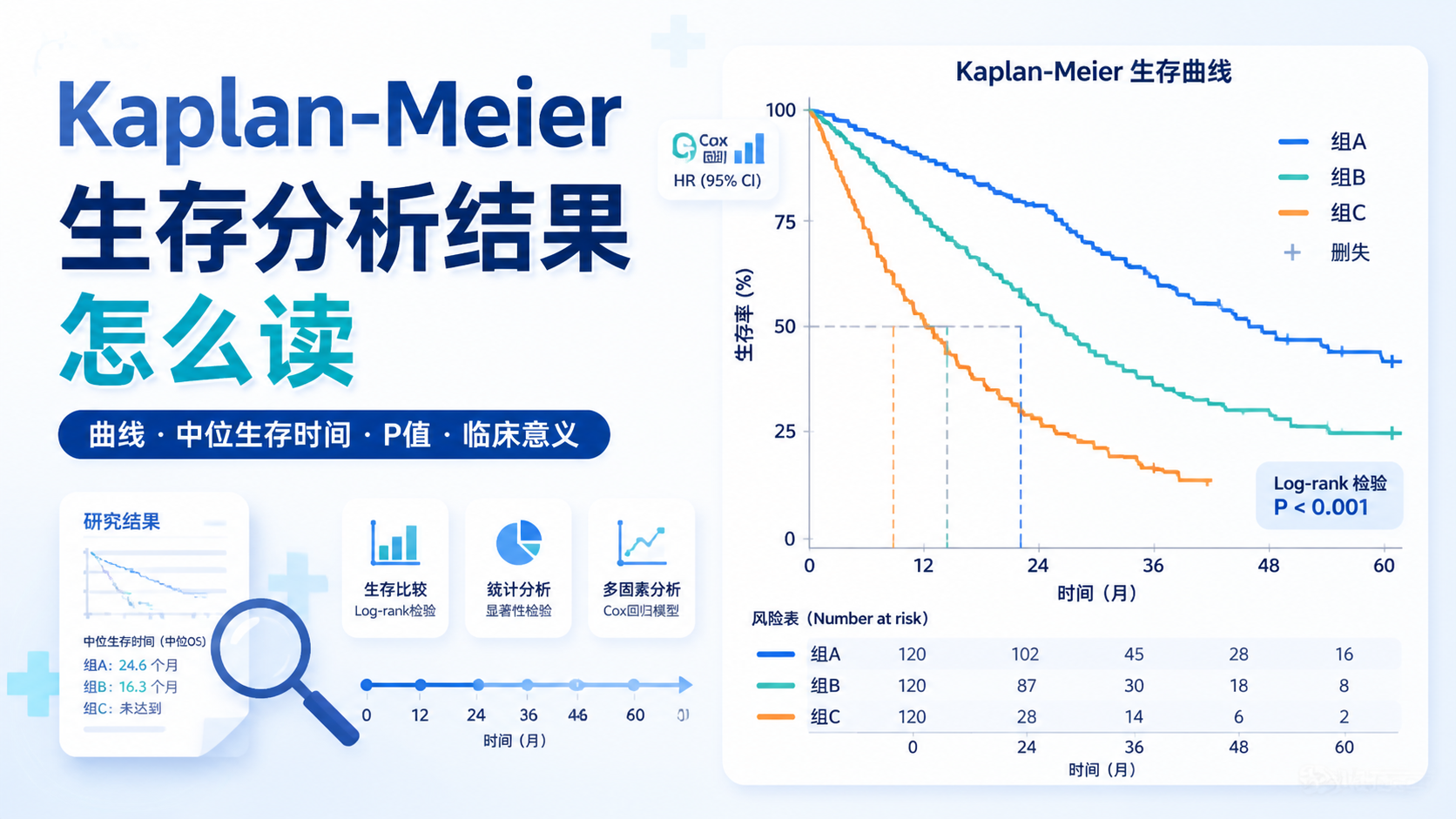
推荐顺序是:
- 描述基线特征。
- 画Kaplan-Meier曲线。
- 做log-rank检验。
- 做单因素Cox。
- 做多因素Cox。
- 检验PH假定。
这样逻辑更完整,也更符合论文写作习惯。cox生存分析不是单一步骤,而是一套链式流程。
5.4 结果展示要规范
临床文章中,建议把单因素和多因素结果放在同一张表中。
表格中至少包含:
- 变量名
- HR
- 95%CI
- P值
如果是预后研究,还可以补充校准、分层分析或列线图,增强论文完整性。
6. 常见错误与规避方法
6.1 状态变量编码弄错
这是最常见错误。
一定要在建模前确认:哪个值代表事件,哪个值代表删失。
编码错误会让整个cox生存分析失去意义。
6.2 只看单因素,不看多因素
单因素显著,不代表独立显著。
多因素才是控制混杂后的核心结果。
写论文时,最好同时呈现两者。
6.3 忽略PH假定
这是方法学上最容易被审稿人质疑的点之一。
如果PH假定不成立,需要考虑分层Cox、时间依赖协变量或其他替代方法。
总结Conclusion
cox生存分析的高效完成,关键在于数据清洗、模型选择、假设检验和结果解释四步同步推进。 对医学生、医生和科研人员来说,真正有价值的不是跑出一个P值,而是把生存时间、删失、HR和临床意义讲清楚。
如果你希望更快掌握规范的Cox建模流程、R实现方法和论文结果写法,可以借助解螺旋的系统课程与实战内容,减少试错成本,直接提升研究效率。
- 引言Introduction
- 1. 先理解Cox生存分析到底解决什么问题
- 2. 做好Cox生存分析前,数据必须先整理对
- 3. Cox生存分析的标准建模流程
- 4. 结果该怎么读,才符合临床研究写作规范
- 5. 高效完成Cox生存分析的实用建议
- 6. 常见错误与规避方法
- 总结Conclusion