引言Introduction
GO富集分析是生信中最常见的功能解释步骤,但很多人会卡在基因ID转换、背景集选择和结果解读上。如果流程不严谨,结论就容易失真。 本文按科研写作标准,拆解 go富集分析 的5个关键步骤,帮助医学生、医生和科研人员快速建立可复现流程。
1. 先明确GO富集分析的输入和目标
1.1 先问清楚:你要回答什么生物学问题
go富集分析不是“把基因丢进去出图”这么简单。它的核心,是判断一组基因是否在某些生物过程、分子功能或细胞组分中显著过度代表 。常见输入包括差异基因、RRA整合后的候选基因,或单细胞某个cluster的marker基因。
如果研究对象是肿瘤、免疫、代谢或单细胞亚群,提问方式要先定清楚。比如:
- 这批上调基因主要参与什么过程。
- 某个细胞亚群为何具有特定功能。
- 处理前后差异基因是否集中在某条生物通路。
问题定义越清楚,go富集分析越有解释力。
1.2 GO三大类别要分开看
GO通常分为三类:
- BP,Biological Process,生物过程。
- CC,Cellular Component,细胞组分。
- MF,Molecular Function,分子功能。
在实际论文中,BP最常用,因为它最贴近“功能变化”。但严谨写法不能只看BP。至少要说明你分析的是哪一类GO term。 如果结果需要横向比较,可按BP、CC、MF分别展示。
1.3 富集分析前先保证数据质量
在进入 go富集分析 前,先检查输入基因表是否规范。知识库中的实操建议很明确:每做一步新操作前,都先看数据。 因为R里很多报错不是算法问题,而是数据列名、重复值或ID类型不一致导致的。
建议先确认:
- 是否只有显著基因进入分析。
- 是否存在重复基因。
- 物种注释是否匹配。
- 基因名是否统一为Symbol或EntrezID。
2. 做好基因ID转换,避免“输入不兼容”
2.1 Symbol不能直接替代EntrezID
在 clusterProfiler 体系里,很多函数更偏向使用 EntrezID。知识库案例中,流程是先将 Gene Symbol 转换为 EntrezID ,再进入富集分析。这个步骤不是形式主义,而是为了保证后续 GO 和 KEGG 分析能顺利衔接。
如果ID类型不一致,富集结果可能为空或偏差明显。
常见做法是用 bitr 或同类转换函数,把 Symbol 映射到 EntrezID。转换完成后,通常只保留可映射成功的基因,并去除重复项。
2.2 物种数据库要选对
人和小鼠不能混用背景库。知识库中提到,人类常用 org.Hs.eg.db,小鼠则需要对应的小鼠数据库。这个细节非常关键。背景文件一旦选错,整个 go富集分析 的统计基础就错了。
你需要确认:
- 数据来源是人还是鼠。
- 物种注释包是否匹配。
- 结果中的基因ID是否成功映射到目标数据库。
2.3 先导出转换结果,再继续分析
严谨流程里,建议把转换后的 ID 表单独保存。这样既方便复查,也方便论文附录整理。知识库中也强调,转换后可将结果写出为 txt 或保存为 Rda 格式,后面可直接加载复用。
这一步的价值在于:
- 提高可重复性。
- 方便排查错误。
- 避免重复运行大流程。
3. 用clusterProfiler完成富集计算
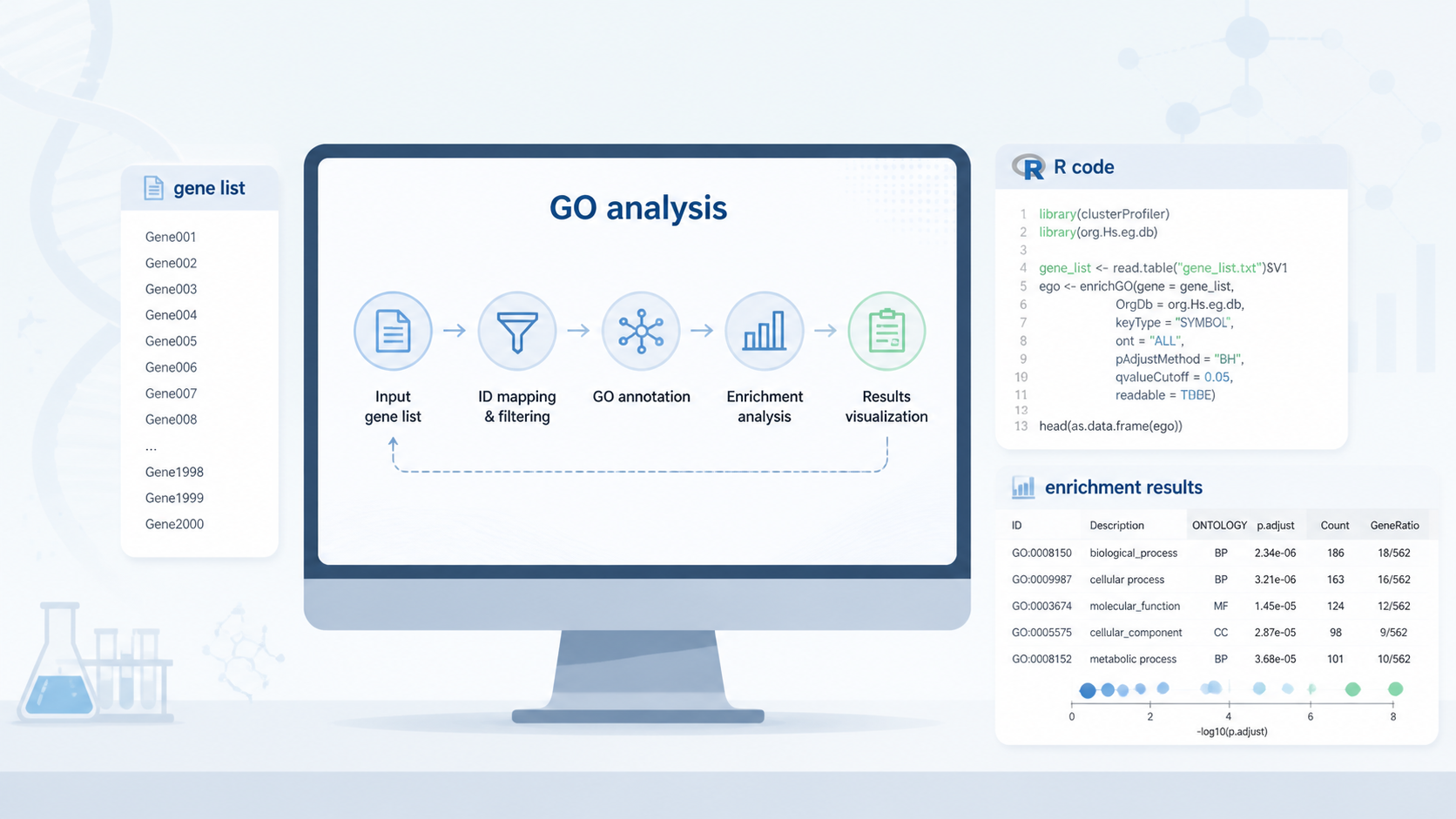
3.1 enrichGO是GO分析的核心函数
知识库给出的标准做法是使用 clusterProfiler 中的 enrichGO 完成 go富集分析。它的主要参数包括:
gene:待分析基因集。OrgDb:物种注释数据库。pvalueCutoff:P值阈值。qvalueCutoff:多重校正阈值。readable:是否映射回基因名。
这是一个标准化、可复现的分析框架。
实际操作时,通常先将候选基因整理为 EntrezID 向量,再输入函数。分析完成后,查看前几条结果,确认条目是否符合研究方向。知识库中也特别强调:富集结果少时,可以适度放宽阈值,但要在文中说明。
3.2 阈值不是越严越好
很多初学者会把阈值设得过死,结果一条都富集不到。经验上,阈值需要结合样本量和基因数量调整。知识库明确提到,当富集结果较少时,可以放宽条件。
但要注意两点:
- 不要为了出图盲目放宽。
- 文中必须说明采用的统计阈值。
通常写作时,至少交代:
- P值阈值。
- FDR或q值阈值。
- 富集基因数量。
3.3 先看结果,再决定是否继续深挖
富集分析不是结束,而是解释起点。建议重点看:
- top term 是否和实验方向一致。
- 条目是否过于泛化。
- 是否存在大量重复或语义相近条目。
如果结果分散、噪声大,可以回到上游重新筛基因。go富集分析的质量,70%取决于输入基因集。
4. 用合适的图形把结果讲清楚
4.1 柱状图适合快速概览
知识库中提到,富集结果常用三种可视化:柱状图、气泡图和网络图。柱状图最适合快速展示 top 10 条结果,阅读成本低,适合放在补充图或正文主图中。
它的优点是:
- 条目排序直观。
- 便于比较富集强度。
- 适合小规模展示。
但柱状图也有局限,尤其是在条目较多时,信息密度有限。
4.2 气泡图更适合展示统计和基因数信息
气泡图在 go富集分析 中非常常见。知识库中提到,气泡图相较柱状图“信息更多”。它通常同时展示:
- 富集条目名称。
- 富集程度。
- 命中基因数。
- P值变化。
对于论文正文,气泡图往往比单纯柱状图更有说服力。
如果你希望突出多个term的统计差异,气泡图通常是更稳妥的选择。
4.3 网络图适合展示条目之间的关系
网络图在知识库中用 cnetplot 或 emapplot 思路呈现,核心优势是能让读者看到不同条目之间的关联。对于相近功能条目较多的情况,网络图更有解释力。
它适合回答:
- 哪些term之间高度相关。
- 哪些基因同时参与多个条目。
- 功能模块是否形成聚类。
如果你的重点是机制网络,而不是单个条目排名,网络图更合适。
5. 把结果写进论文,而不是只停留在图上
5.1 结果表比图更能支撑论文结论
严谨的 go富集分析 必须有表格支撑。知识库中明确提到,GO富集结果可以写出为 txt 文件,再整理成表格放入文章。正文图负责展示趋势,表格负责给出证据。
建议表格至少包含:
- GO term名称。
- GO类别。
- 富集基因数。
- P值或校正后P值。
- 涉及基因列表。
5.2 解释结果时要避免过度推断
GO结果只能说明“关联”,不能直接等同因果。比如看到免疫相关条目富集,最多说明这批基因与免疫过程相关,不能直接推出某条通路就是病因。
写作时建议遵守三点:
- 用“提示”“表明”“可能参与”等谨慎表述。
- 结合上游差异分析、PPI或实验验证。
- 不要把单一term当成唯一机制。
go富集分析的价值在于缩小机制范围,而不是替代实验。
5.3 单细胞和分组分析要特别注意
知识库中还提到,单细胞场景下可以对不同cluster分别做富集,甚至按BP、CC、MF分别比较。对于治疗前后、A组和B组这类分组分析,也可以用 compareCluster 思路比较不同样本的功能差异。
这类分析特别适合:
- 细胞亚群功能注释。
- 新亚型命名。
- 干预前后功能变化对比。
如果你研究的是单细胞数据,go富集分析不只是“功能注释”,还是亚群定义工具。
6. 一个更稳妥的实操流程
6.1 推荐的5步流程
结合知识库内容,一个相对稳妥的 go富集分析 流程可以概括为:
- 先筛选显著基因,明确研究问题。
- 将 Symbol 转为 EntrezID,并去重。
- 选择正确的物种注释库。
- 用 clusterProfiler 的
enrichGO计算富集。 - 用柱状图、气泡图或网络图展示结果,并输出表格。
这套流程适合论文、课题汇报和课题复现。
6.2 最容易出错的三个地方
实际项目中,最常见的问题通常是:
- 输入基因ID不统一。
- 物种数据库选择错误。
- 只看图,不看原始富集表。
只要这三点处理好,go富集分析的稳定性会明显提高。
6.3 如果结果太少,优先回看上游
当你发现几乎没有条目富集出来时,不要先怀疑软件。先检查:
- 基因数量是否过少。
- 阈值是否过严。
- 是否用了错误ID。
- 是否背景集不匹配。
这也是知识库反复强调“先查看数据”的原因。做富集分析,细节往往比算法更重要。
总结Conclusion
GO富集分析的核心,不是做图,而是建立一条可复现、可解释、可发表 的分析链条。只要把基因筛选、ID转换、物种背景、统计阈值和可视化这5步做对,结果通常就会更稳、更严谨。

如果你希望把 go富集分析 做得更快、更规范,可以直接使用解螺旋的生信课程与实战模板,减少重复试错,把时间留给结果解释和论文写作。
- 引言Introduction
- 1. 先明确GO富集分析的输入和目标
- 2. 做好基因ID转换,避免“输入不兼容”
- 3. 用clusterProfiler完成富集计算
- 4. 用合适的图形把结果讲清楚
- 5. 把结果写进论文,而不是只停留在图上
- 6. 一个更稳妥的实操流程
- 总结Conclusion