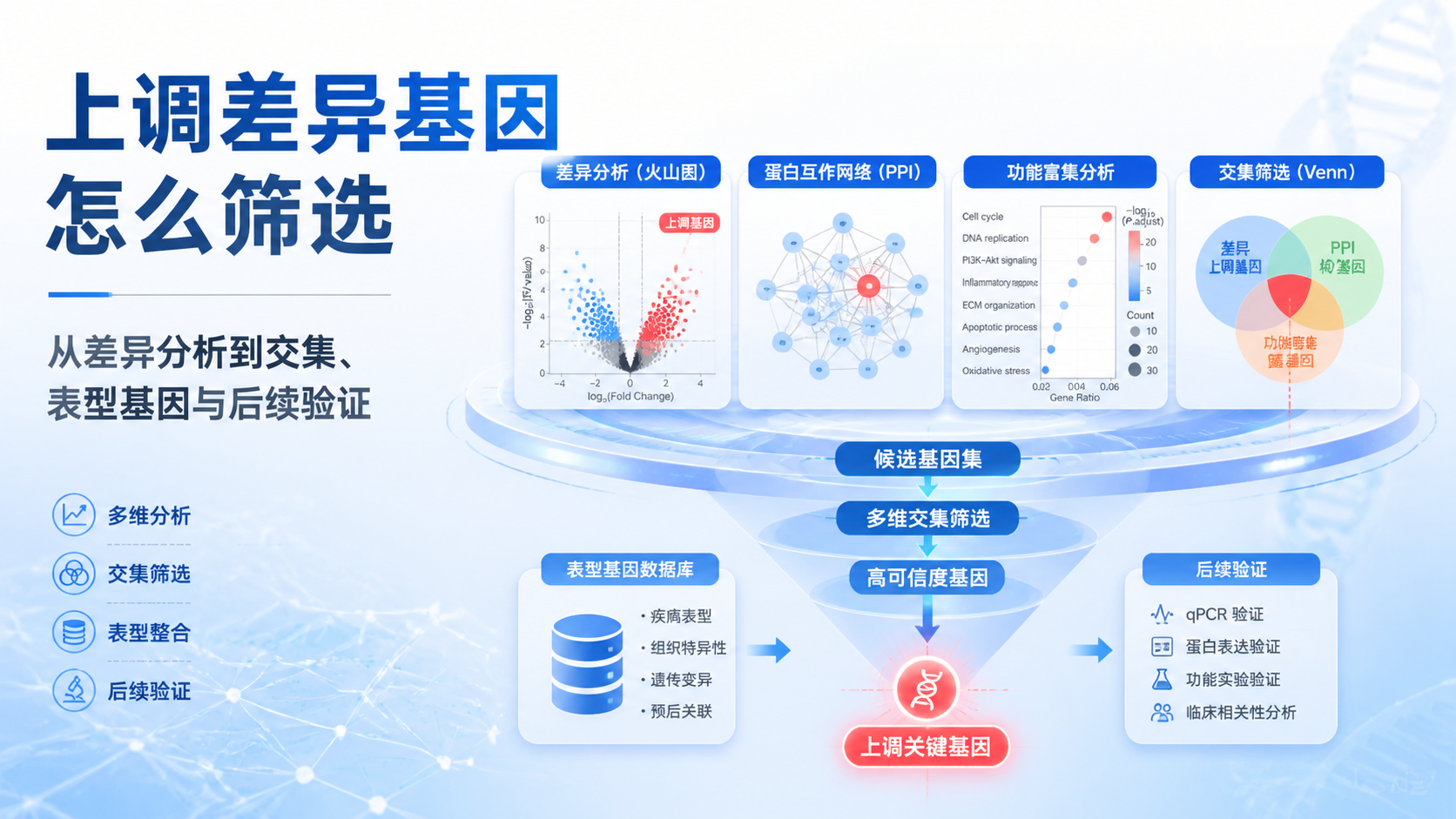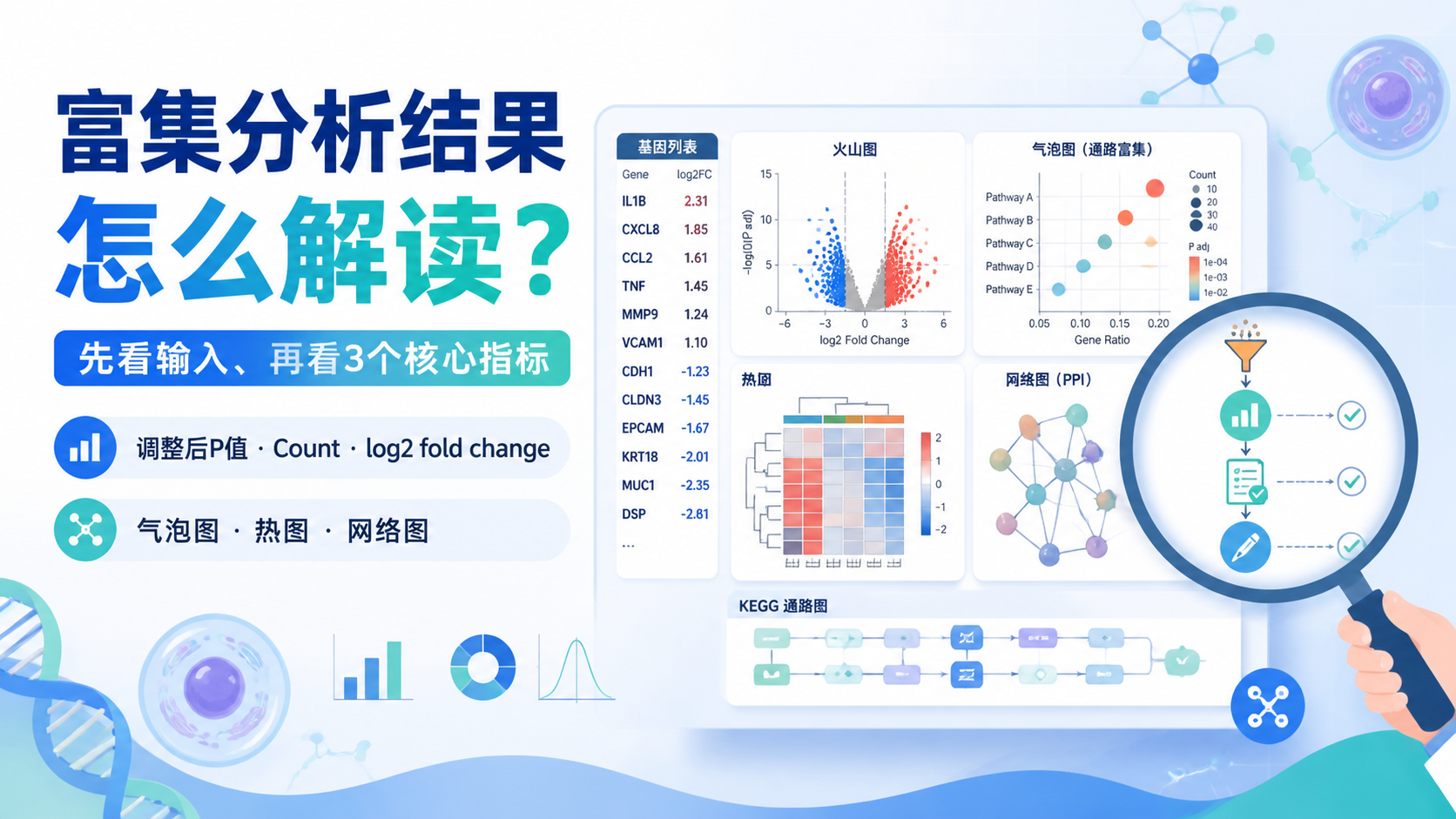
引言Introduction
富集分析结果常让人“看得懂图,却说不清结论”。尤其在差异基因很多、通路很多时,如何判断哪些结果可信、哪些结果值得写进论文 ,是医学生、医生和科研人员最常见的痛点。本文围绕富集分析,拆解3个核心指标。
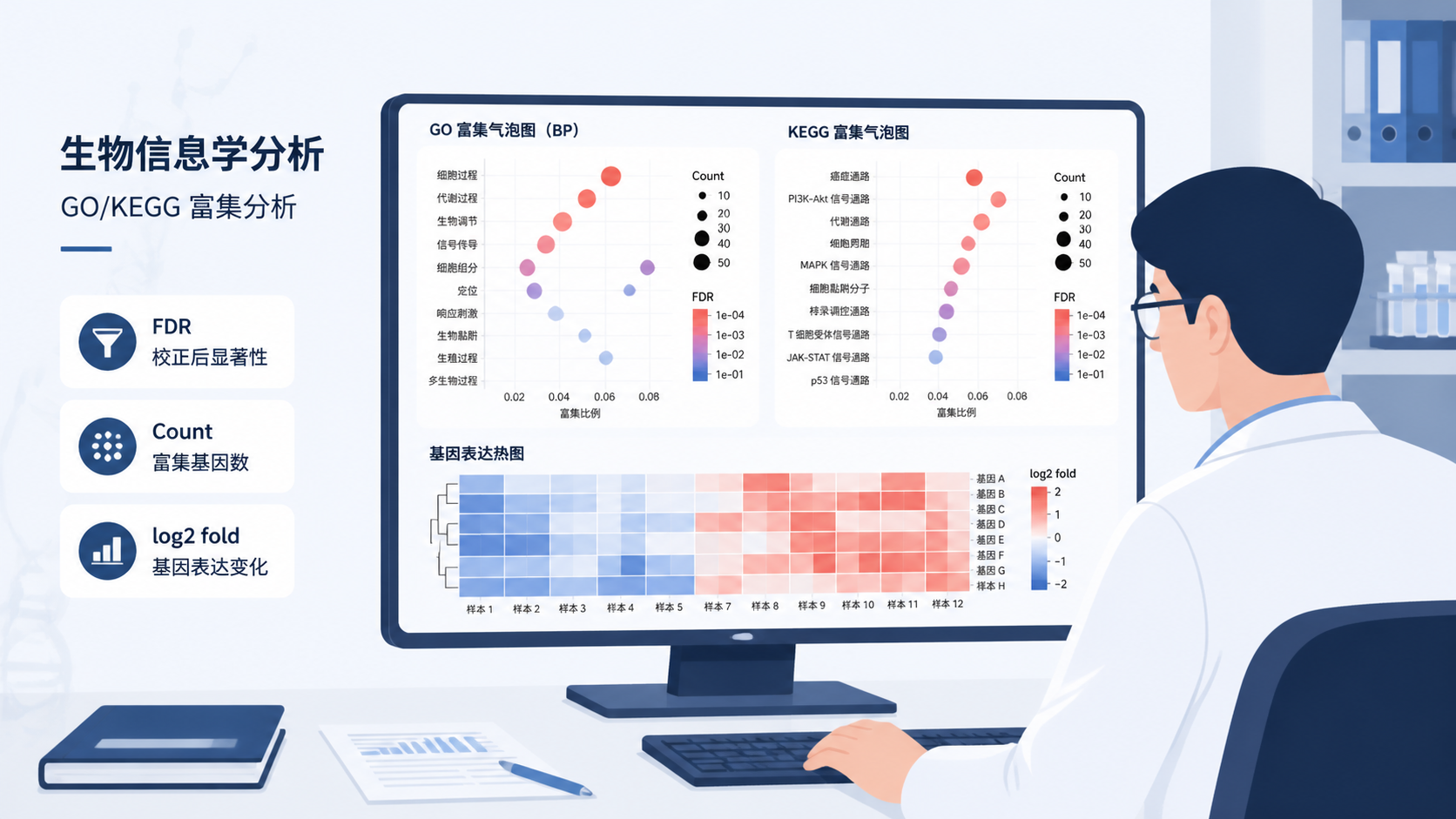
1. 富集分析前,先确认输入是否正确
1.1 差异分析结果不是所有基因都能直接用
做富集分析前,先看差异分析结果。课程中使用的是 DESeq2 结果,并且基于 FDR 小于 0.05 的差异基因进行后续分析 。这是第一道筛选。
如果输入本身不稳定,后面的富集分析再漂亮,也只是噪音放大。
同时,富集分析通常不是直接拿 SYMBOL 就结束。课程里明确提到,需要把基因 ID 转成 ENTREZID 。这是因为很多富集函数更依赖标准化的基因编号。常用做法是筛选第一列和第三列,再用 bitr 进行转换。人类样本对应 org.Hs.eg.db。
1.2 合并后的基因表决定后续结果质量
ID 转换后,不是直接进入富集分析,而是要把结果和 log2 fold change 合并。课程中使用的是 inner join 。这样能把 SYMBOL、log2 fold change、ENTREZID 合并到同一张表里。
转化失败的基因会出现 NA,需要去掉。最后得到的表至少应保证三列清晰可用。
这一步很关键。因为后续不仅看“富集到了什么”,还要看这些基因是上调还是下调 。如果这一层没处理好,后面图再多,也解释不出方向性。
2. 富集分析结果解读,先看3个核心指标
2.1 调整后 P 值,决定“可信度”
富集分析最常见的误区,是只盯着 P 值。实际上,更应该看调整后的 P 值,也就是 FDR 。
课程中的气泡图右侧展示的就是 FDR。FDR 越小,说明该条目在多重检验校正后越可靠 。这比单纯看原始 P 值更适合高通量分析。
在实际解读中,可以这样判断:
- FDR 较小的条目,优先保留
- FDR 较大的条目,只适合探索性参考
- 论文写作时,优先报告显著且生物学上合理的条目
如果结果里 FDR 都接近阈值,说明信号可能偏弱,需要回头检查差异分析阈值、基因集范围和物种注释是否匹配。
2.2 Count,表示富集到多少差异基因
第二个核心指标是 Count 。它表示某个功能条目中富集到的差异基因数量。
课程里明确指出,气泡图中 圈子越大,代表 Count 越高 。这通常意味着该条目覆盖的差异基因更多。
但要注意,Count 大不等于一定更重要。还要结合 FDR 一起看。
更稳妥的判断方式是:
- 先看 FDR 是否足够小。
- 再看 Count 是否有实际支撑。
- 最后判断这个条目是否符合研究主题。
也就是说,“大圈低 FDR”通常比“只大不显著”更有价值 。课程中也提到,希望找到圈子大且 p 值小的结果,但实际分析里未必总能出现。
2.3 log2 fold change,告诉你方向和强度
第三个核心指标是 log2 fold change 。
它本来是差异分析指标,但在富集分析里非常重要。课程中在富集前专门把 log2 fold change 取出来,并赋值给 ENTREZID,用于后续图形展示。
为什么要看它?因为富集分析只告诉你“哪些通路被命中”,log2 fold change 才告诉你这些基因是上调还是下调 。
如果某通路中大部分基因是正向变化,说明该通路可能更偏激活;如果负向基因更多,则可能偏抑制。
课程中还提到,会筛选 绝对值大于 2 的 log2 fold change 。这类基因变化幅度更大,通常更适合用于重点解读。
在实际论文里,常见写法是:优先关注高变化幅度基因所在的功能条目,再结合文献解释其生物学意义。
3. 不同图怎么看,别只停留在“图好不好看”
3.1 气泡图,最适合快速抓重点
气泡图是富集分析里最常用的结果展示。课程中提到,右侧是 FDR,颜色与 p 值相关,颜色越深,p 值越小 。
这类图最适合做第一轮筛选。
阅读气泡图时,建议按这个顺序:
- 先看右侧显著性指标
- 再看气泡大小,也就是 Count
- 最后结合通路名称判断是否符合课题背景
如果一张图上出现很多大气泡,但 FDR 并不低,那不一定值得重点解释。
反过来,小而显著、且与课题高度相关的条目,往往更值得写进结果和讨论 。
3.2 热图,适合看功能条目内部结构
课程中还提到热图,主要展示的是 activity 相关结果,并用 facet-grid 将 BP、CC、MF 分开展示。
热图的价值,不在于比气泡图更“炫”,而在于看某个功能条目内部到底有哪些基因在驱动结果 。
课程中也提到,形状可以按 Count 做区分,例如:
- Count 大于 30,显示三角形
- Count 小于 30,显示圆形
这类设计有助于快速区分高密度功能条目。
不过从信息密度上看,热图通常不如气泡图直观 ,更适合在结果整理阶段辅助查看。
3.3 网络图和 KEGG 的 upset 图,用来补充机制线索
网络图使用 cnetplot 展示,能把基因和功能条目联系起来。课程中强调,要给 gene list 赋予 log2 fold change 信息。
这一步的意义在于,不只是看功能条目,而是看哪些基因把这些条目串起来 。
KEGG 分析中还会使用 upset 图。课程里提到,upset 图能显示多个通路之间的交集,比如 cytokine-cytokine receptor interaction、cAMP、Wnt 等通路之间的共享基因。
这类图特别适合找“交叉节点”,也就是可能的关键基因或关键通路。
4. 实战解读时,3个指标要一起看
4.1 不能只看显著性
很多初学者会只问:这个通路显著吗。
更专业的问法应该是:这个通路是否同时满足低 FDR、合理 Count、明确方向性 。
举个简单逻辑:
- FDR 很低,但 Count 很小,可能是少数强信号驱动
- Count 很大,但 FDR 不理想,可能是泛化条目
- log2 fold change 明显一致,说明方向性更清晰
所以,富集分析不是单指标打分,而是三指标联合判断。
4.2 不能只看统计,要回到生物学问题
课程中的思路很明确:富集分析的目的不是堆结果,而是服务于机制解释。
例如,某些条目如果与炎症、细胞外基质、免疫调控相关,就要结合疾病背景判断它们是否有解释力。
统计显著只是入口,生物学合理才是终点。
这是富集分析结果解读中最重要的一点。
4.3 先筛结果,再写结论
推荐的实操顺序是:
- 先用 FDR 筛出可靠条目。
- 再看 Count,保留有足够基因支撑的结果。
- 最后结合 log2 fold change 判断上调或下调趋势。
- 再去看气泡图、热图、网络图和 KEGG 交集图。
这样写出来的结果更像论文,而不是图注罗列。
总结Conclusion
富集分析的核心,不是“画出了什么图”,而是“你能否从图里提炼出可信、可解释、可发表的结论 ”。
在实际解读中,最重要的3个指标是:FDR 看可信度,Count 看覆盖度,log2 fold change 看方向性 。三者结合,才能把富集分析从结果展示变成机制线索。
如果你希望把富集分析做得更规范、更适合论文写作,建议直接使用解螺旋品牌的课程与工具思路,按照标准化流程完成差异基因筛选、ID 转换、结果合并和图形解读。这能明显减少返工,让结果更容易写进文章。
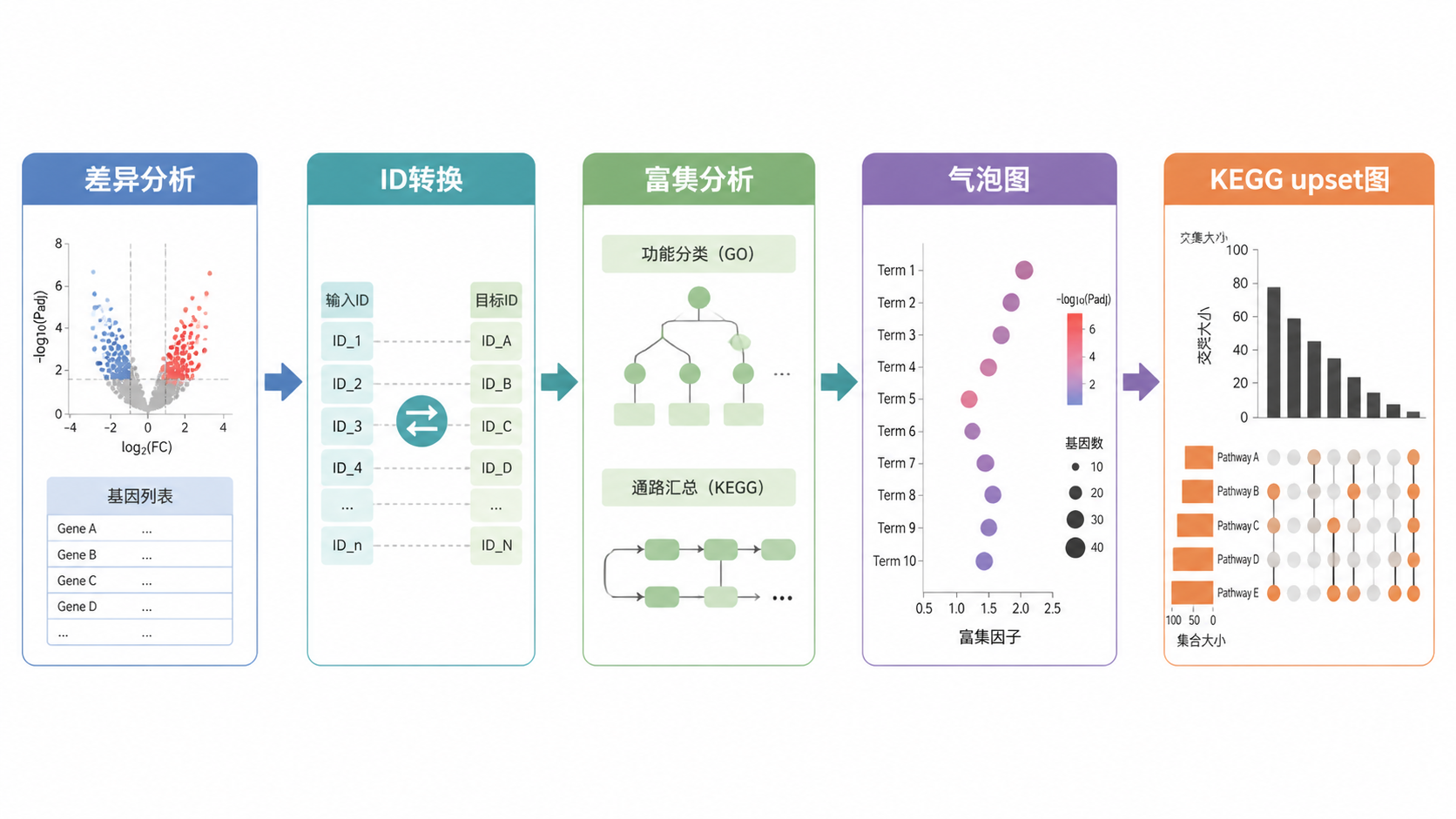
- 引言Introduction
- 1. 富集分析前,先确认输入是否正确
- 2. 富集分析结果解读,先看3个核心指标
- 3. 不同图怎么看,别只停留在“图好不好看”
- 4. 实战解读时,3个指标要一起看
- 总结Conclusion