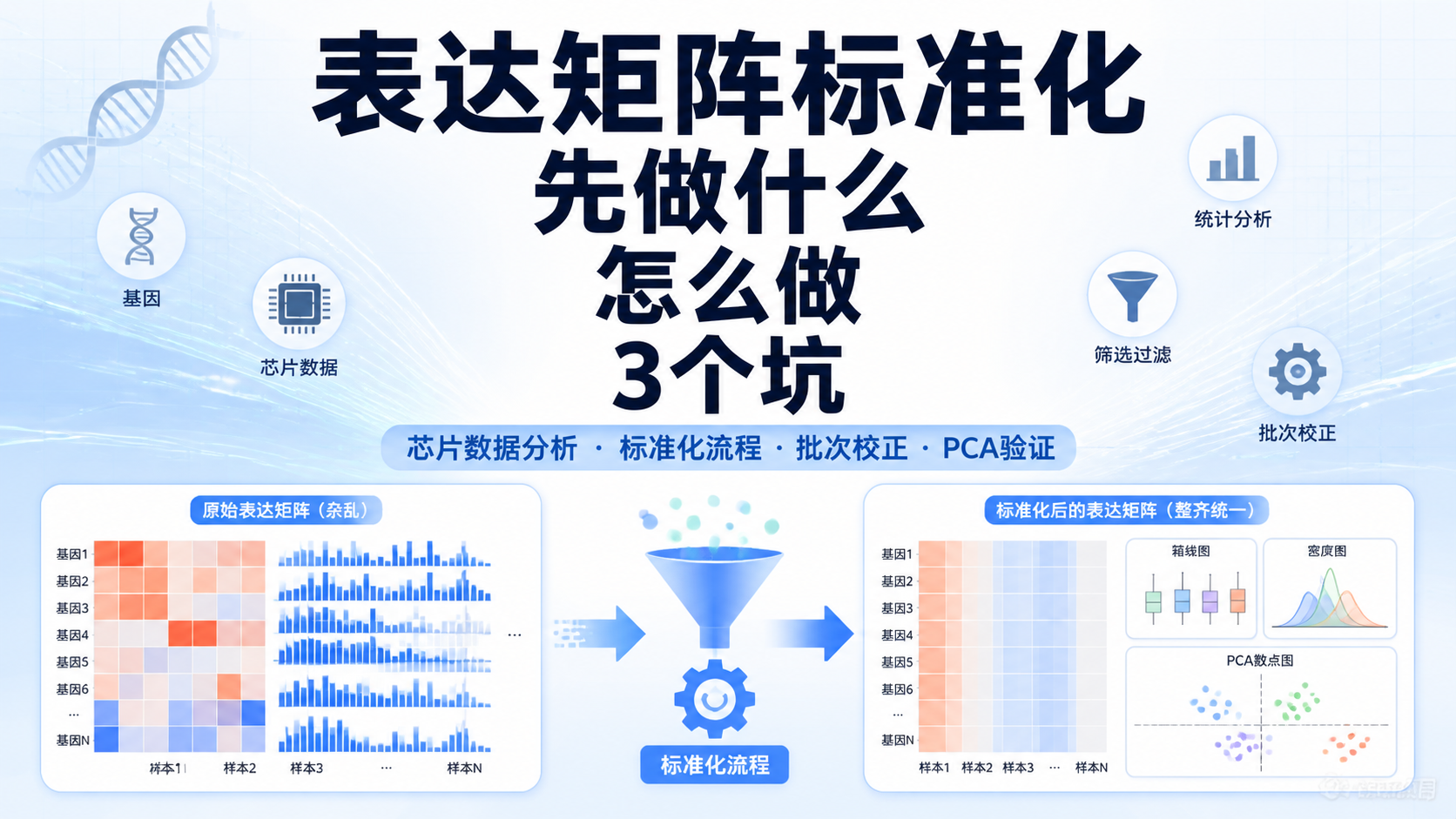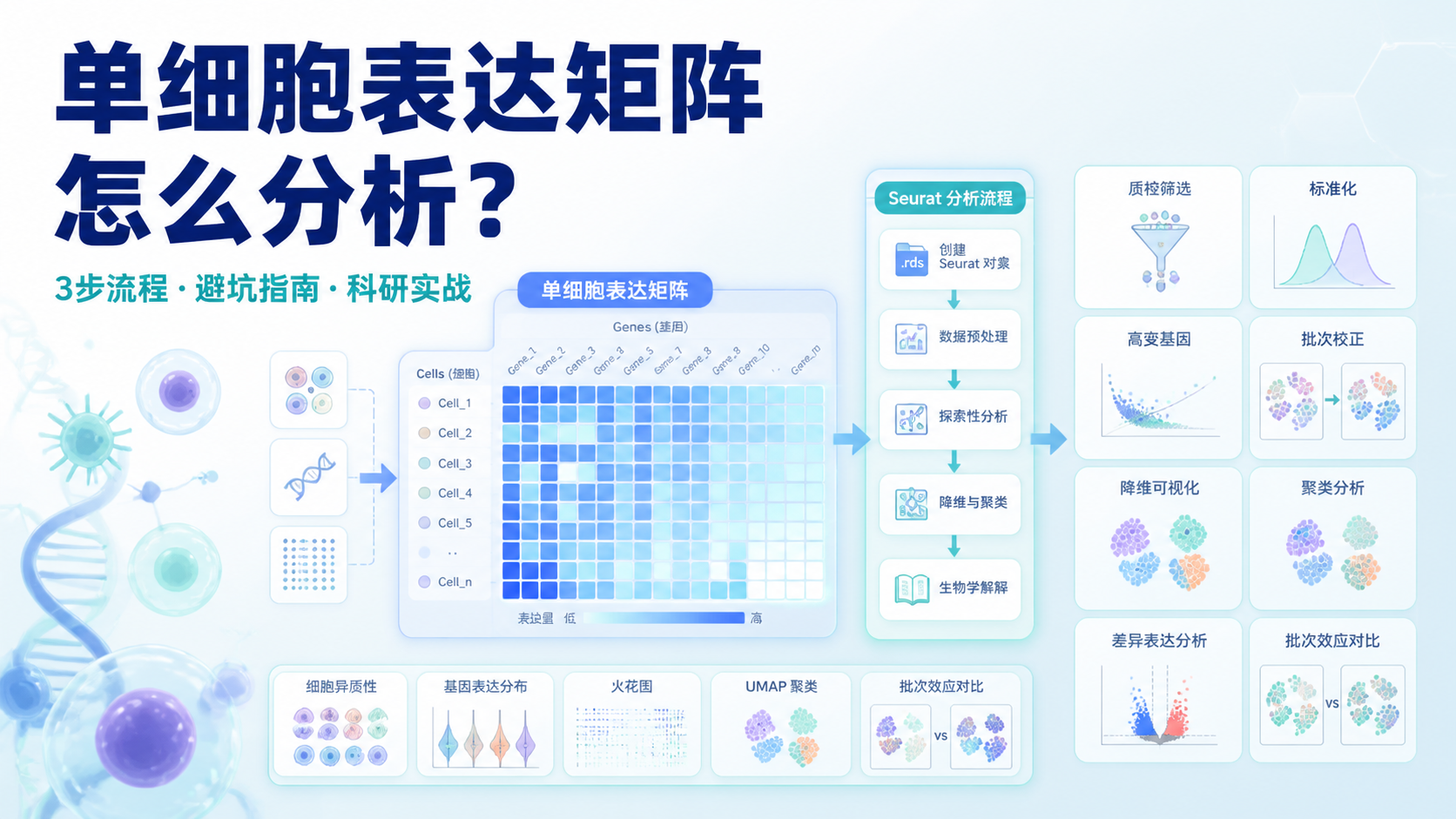
引言Introduction
单细胞表达矩阵是单细胞分析的起点,也是最容易出错的一步。很多人拿到数据后,不清楚该先做质控、归一化,还是直接聚类。如果前处理不规范,后面的细胞注释、差异分析和轨迹分析都会受影响。 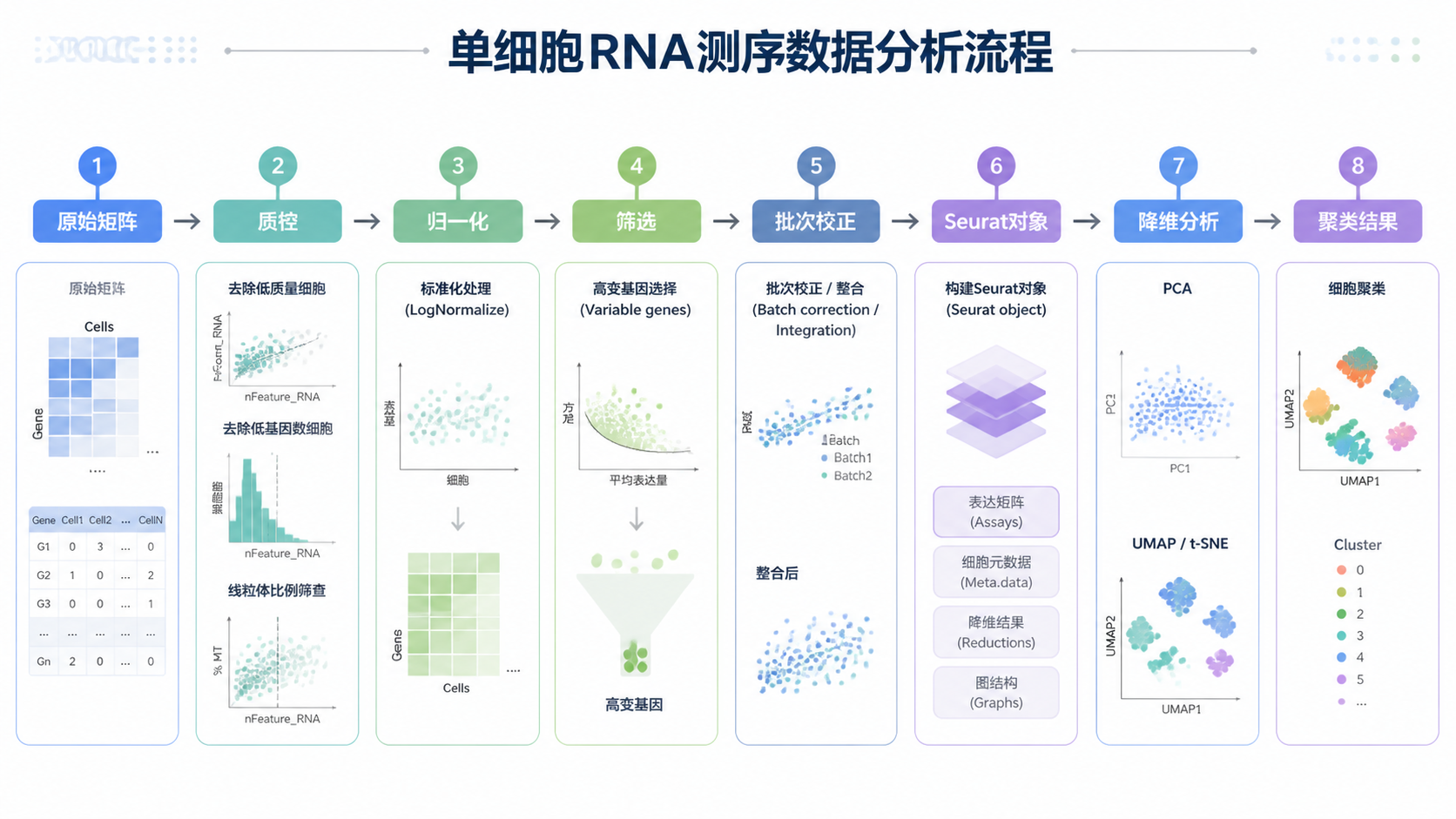
1. 先读懂单细胞表达矩阵的组成
1.1 表达矩阵、基因信息和细胞信息缺一不可
在实际分析中,单细胞表达矩阵通常不是单独存在的。课程知识库中提到,Cell Ranger 完成后,常见输入包括三类数据。第一类是表达矩阵 ,行是基因名,列是细胞 barcode。第二类是基因信息,通常记录基因在背景基因组中的注释。第三类是细胞信息,核心内容是 barcode。
这三类数据共同构成了单细胞分析的基础。 如果只保留表达矩阵,而缺少基因和细胞注释,后续对象构建、名称映射和结果解释都会变得困难。
1.2 为什么表达矩阵不是“直接分析就行”
单细胞表达矩阵的稀疏性很高。原因很简单,单细胞测序中大量基因在单个细胞里并不表达,或者表达量极低。再加上环境 RNA、双细胞捕获、低质量细胞等问题,原始矩阵往往噪音较大。
因此,分析的第一目标不是“找差异”,而是先把可信信号从噪音里筛出来。 这也是为什么单细胞分析流程通常先走数据清洗与基础分析,再进入高级分析。
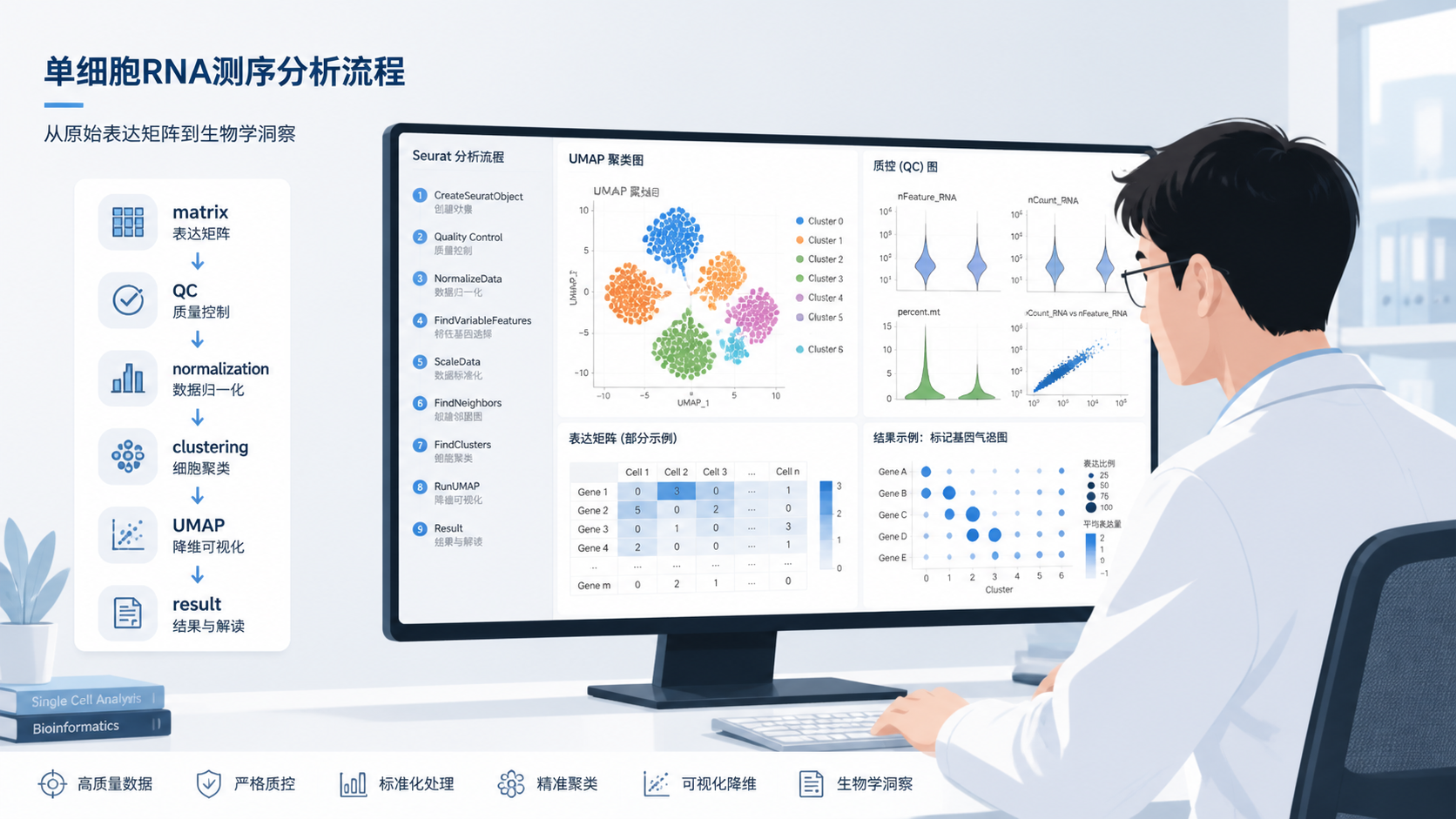
1.3 最常见的分析入口是Seurat对象
课程中给出的标准做法,是把表达矩阵、基因信息和细胞信息整理成 Seurat 格式对象。这个步骤看起来简单,但它决定了后续所有分析能否顺利执行。
对于医学生、医生和科研人员来说,可以把它理解为:
- 把原始表格整理成统一结构。
- 把样本、细胞和基因信息对齐。
- 让后续质控、降维、聚类、注释都在同一对象中完成。
2. 用3步完成单细胞表达矩阵的核心分析
2.1 第一步,质控与过滤先把低质量信号剔除
课程明确提到,单细胞分析要过滤掉不包含细胞的油滴,也要过滤包含多个细胞的油滴。前者对应空滴,后者对应双细胞或多细胞污染。除此之外,还要关注线粒体基因比例。因为受损细胞可能只测到线粒体相关转录本。
质控的本质,是减少技术噪音对单细胞表达矩阵的干扰。
常见的过滤思路包括:
- 去除空滴。
- 去除疑似双细胞。
- 过滤线粒体比例过高的细胞。
- 排除异常低 UMI 或异常低基因数的细胞。
课程没有给出统一阈值,这一点很重要。阈值不能机械照搬,应该结合组织类型、测序深度和样本质量来定。
2.2 第二步,标准化和高变基因筛选决定分析效率
在完成质控后,下一步是对 Count 值进行标准化。这样做的目的,是提高不同细胞之间的可比性。因为不同细胞的测序深度不同,原始计数不能直接横向比较。
标准化之后,还要进行特征筛选。课程中提到的核心做法,是筛选高变基因用于后续分析。高变基因指的是变异较大或方差较大的基因 。推荐保留 1000 到 5000 个高变基因。
这一步的意义在于:
- 降低维度。
- 提高降维速度。
- 聚焦最能反映细胞状态差异的信号。
如果把所有基因都丢进后续分析,计算成本会明显增加,结果也更容易被背景噪音稀释。
2.3 第三步,批次效应和协变量处理让结果更可靠
在真实项目里,单细胞表达矩阵很少只来自一个样本。课程中提到,多样本设计中必须警惕批次效应。不同批次、不同上机时间、不同建库条件,都可能让同一类细胞看起来像不同群体。
解决方法主要有两类。
第一类是使用 Seurat 进行批次效应去除。
第二类是做协变量回归,去除细胞周期、UMI 数目等因素的影响。
这一步的目标不是“美化图”,而是减少非生物学差异。
如果不处理批次效应,后续聚类可能按批次分组,而不是按真实细胞类型分组。
3. 从表达矩阵走向生物学结论
3.1 降维和聚类是表达矩阵分析的中间站
当单细胞表达矩阵经过质控、标准化和高变基因筛选后,就可以进入降维和聚类。虽然知识库中这一节重点放在前处理,但后续流程已经明确指向高级分析,包括细胞类型注释、差异基因、细胞通讯等。
常见路径是先做 PCA,再用 t-SNE 或 UMAP 展示细胞群体结构。随后根据聚类结果寻找 marker 基因,完成细胞类型注释。
降维的作用不是丢失信息,而是把高维矩阵压缩成更容易解释的结构。
3.2 注释之后,表达矩阵才能进入更深层分析
课程后续内容提到,完成细胞类型注释后,可以进一步做发育轨迹分析、差异分析、GO 富集分析,甚至 TCR 分析。这里的前提仍然是:前面的单细胞表达矩阵已经被正确清洗和组织。
例如在 Monocle 分析中,需要提取表达矩阵,并结合样本注释、聚类信息和基因名字构建对象。说明表达矩阵不仅是输入文件,更是整个下游分析链条的核心底座。
3.3 常见下游方向包括哪些
一个规范的单细胞分析流程,通常会围绕以下几个方向展开:
- 细胞类型注释与标志基因识别。
- 差异表达分析。
- 发育轨迹分析。
- 细胞通讯分析。
- GO 和 KEGG 富集分析。
- 免疫相关分析,如 TCR 相关结果整合。
这些结论都依赖于前面处理好的单细胞表达矩阵。
矩阵质量越高,后续结果越稳定,文章也越容易通过审稿人的方法学审查。
4. 实战中最容易踩的坑
4.1 只看聚类图,不看质控指标
很多初学者会直接关注 UMAP 或 t-SNE 图,但忽略基础质控。这样得到的簇,可能只是低质量细胞、双细胞或批次效应的结果。单细胞表达矩阵的分析,不应该从“图好不好看”出发,而应该从“数据是否可信”出发。
4.2 高变基因筛选过少或过多
课程建议保留 1000 到 5000 个高变基因。这个范围不是绝对值,但很实用。过少会丢掉重要异质性,过多会引入噪音。选择高变基因时,要兼顾稳定性和分辨率。
4.3 忽略协变量会让生物学解释偏移
细胞周期、UMI 数目都可能影响表达矩阵结构。如果不做处理,某些“差异”其实只是技术因素或状态差异。对科研写作来说,这会直接影响结论可信度。
5. 面向科研写作的高效流程建议
5.1 建议按这个顺序推进
针对单细胞表达矩阵,推荐的实操顺序是:
- 整理表达矩阵、基因信息和细胞信息。
- 构建 Seurat 对象。
- 做质控与过滤。
- 标准化。
- 筛选高变基因。
- 校正批次效应和协变量。
- 再进入降维、聚类和注释。
这个顺序的优点是清晰、可复现,也更符合下游发表需求。
5.2 如果你想提高分析效率
单细胞项目里最耗时的,往往不是计算本身,而是数据整理和流程衔接。对初学者来说,最好的方式是把标准化流程固定下来,避免每个项目都从零开始。
这里也建议使用成熟平台或课程资源辅助上手,比如解螺旋的单细胞分析体系。它更适合把单细胞表达矩阵的处理、Seurat 对象构建、质控过滤和后续分析串成完整链路,减少重复试错。
总结Conclusion
单细胞表达矩阵分析的关键,不是“先做什么图”,而是先把数据结构和质量控制做好。核心流程可以概括为三步:先读懂矩阵组成,再完成质控、标准化和高变基因筛选,最后处理批次效应并进入降维聚类。 这样做,才能让后续细胞注释、差异分析和轨迹分析更可靠。
如果你希望把单细胞表达矩阵真正用到科研产出中,建议建立标准化流程,少走弯路。也欢迎进一步结合解螺旋的单细胞课程与工具,系统提升数据处理效率与结果质量。
- 引言Introduction
- 1. 先读懂单细胞表达矩阵的组成
- 2. 用3步完成单细胞表达矩阵的核心分析
- 3. 从表达矩阵走向生物学结论
- 4. 实战中最容易踩的坑
- 5. 面向科研写作的高效流程建议
- 总结Conclusion