引言Introduction
count表达矩阵是单细胞与转录组分析的起点,但很多人拿到数据后,常卡在“看不懂列、行、下标和合并结果”。如果你想快速判断矩阵是否正确、如何提取样本信息、如何完成后续分析,先学会读懂count表达矩阵。
1. 先理解count表达矩阵是什么
1.1 它本质上是二维数据结构
在R语言中,向量是一维数据 ,矩阵是二维数据 。count表达矩阵就是典型的二维结构。它通常包含行和列,适合承载基因与样本的对应关系。对于转录组或单细胞数据,这类矩阵是后续统计和可视化的基础。
理解这一点很重要。 因为很多错误都来自于把矩阵当成向量处理,或者没有区分行列含义。矩阵提取元素时,逗号前是行,逗号后是列。这个规则决定了你后续能否准确读取数据。
1.2 count表达矩阵常见来源
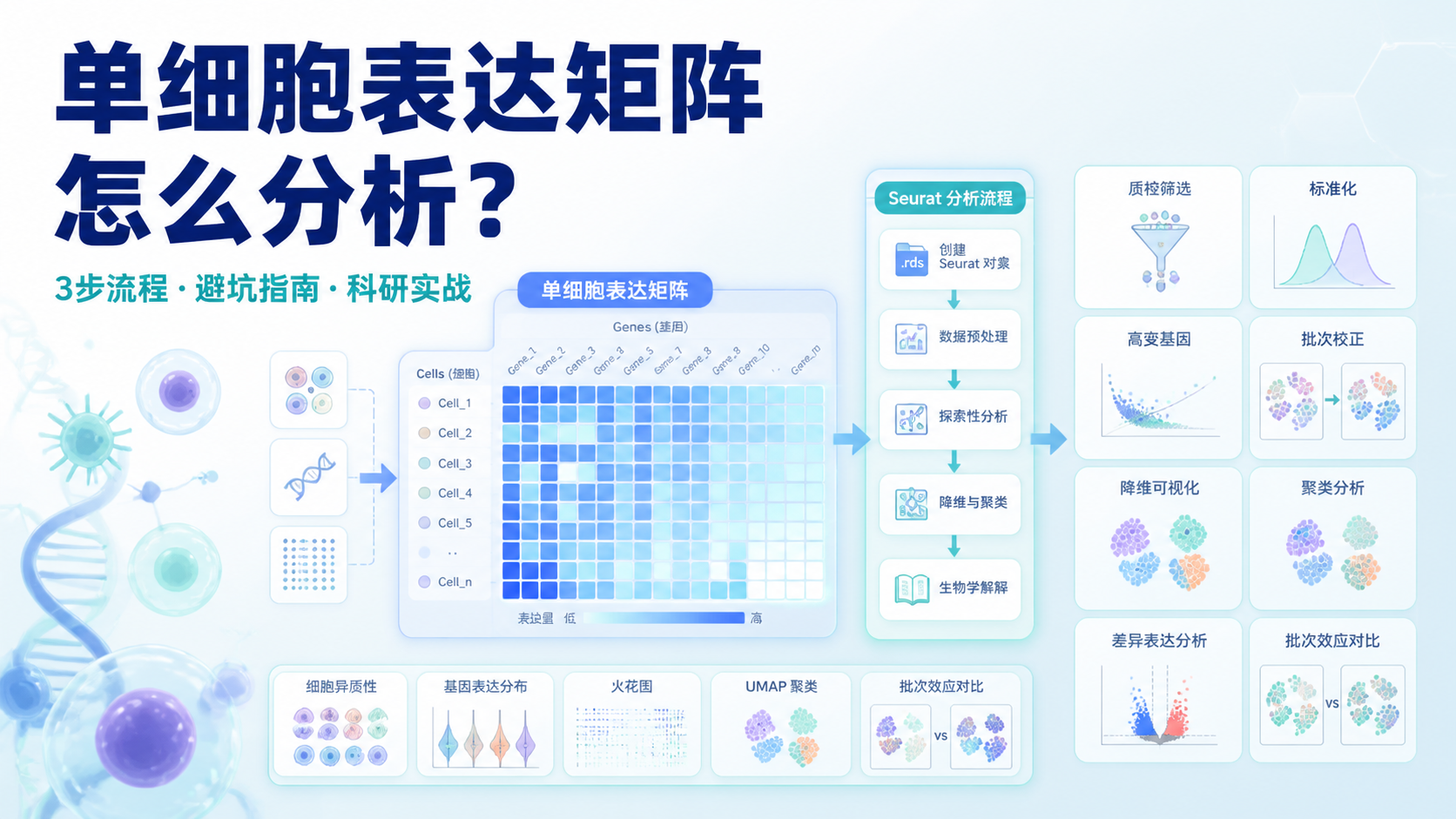
在单细胞分析流程中,多个样本先经过count,再合并为一个矩阵。上游知识库里提到,6个样本可以通过合并命令整合成一个矩阵,并生成对应的HDF5文件,再进一步转成CSV格式。
这说明count表达矩阵不是孤立存在的,它往往来自多个样本的整合结果。
你在分析时,首先要确认矩阵来源。 是单样本count结果,还是多个样本合并后的矩阵。来源不同,解释方式也不同。
1.3 看懂矩阵的核心信息
count表达矩阵通常需要关注以下几点:
- 行数和列数是否合理。
- 行列是否对应预期的基因和样本。
- 是否存在缺失值NA。
- 文件是否已完成合并。
- 是否需要转换成CSV便于查看。
如果这些基础信息没确认,后续分析容易偏离真实数据结构。
2. 方法一:先用维度和长度判断数据是否完整
2.1 先确认对象到底是不是矩阵
在R中,向量可以用length查看长度,但矩阵需要看行列结构。知识库里强调了length用于向量长度,而矩阵是按行列组织的数据。
因此,面对count表达矩阵时,第一步不是直接计算,而是先确认它的结构类型。
如果一个对象只有单一长度信息,往往说明它更接近向量。
如果有明确的行和列,则更符合矩阵特征。
2.2 检查行列是否超范围
矩阵提取时,超出范围会报错。知识库中提到,向量超出范围可能返回NA,但矩阵不支持越界提取。比如提取不存在的第8行或第8列,会直接报错。
这对count表达矩阵尤其重要,因为真实数据中很容易出现行列索引写错的问题。
建议你在读矩阵前先做两件事:
- 确认行数与列数。
- 确认下标范围是否落在有效区间内。
这是最基础,也最容易避免低级错误的一步。
2.3 用范围检查避免误删和误取
在向量中,负号可用于删除元素,矩阵中同样可以通过负号删除行或列。比如myMatrix[-1, ]表示删除第一行。
对于count表达矩阵,这意味着你在清洗数据时必须非常谨慎。一个错误的下标,可能会删掉整行基因或整列样本。
建议保留原始文件副本,再做筛选。
不要在未备份的情况下直接修改原始count表达矩阵。
3. 方法二:按行列提取,快速读懂基因和样本
3.1 行列分开看,效率最高
矩阵切片时,myMatrix[1, ]表示第一行,myMatrix[, 2]表示第二列。这个规则非常适合解读count表达矩阵。
因为在表达矩阵里,行通常代表基因,列通常代表样本或细胞。你只要明确行列含义,就能快速锁定目标信息。
例如你想看某个基因在所有样本中的表达情况,就提取对应行。
如果你想比较某个样本的整体表达分布,就提取对应列。
3.2 批量提取更适合科研场景
知识库中提到,myMatrix[1:3, ]可提取前3行,myMatrix[, 1:3]可提取前3列。
这类批量提取在count表达矩阵中非常常用,尤其适合:
- 快速查看前几个基因。
- 检查前几个样本。
- 做初步质量控制。
- 验证导入后的数据是否正确。
批量提取的价值,在于能快速发现异常。
比如某一列全是0,或者某几行数值明显不合理,都能在前期及时发现。
3.3 按条件提取更适合筛选分析
知识库还提到,向量可以按条件提取,如提取小于8的元素。虽然这部分示例来自向量,但思路可以迁移到矩阵筛选。
在count表达矩阵分析中,按条件筛选常用于:
- 去除低表达基因。
- 保留高质量样本。
- 按阈值筛选表达量。
- 排除异常值。
条件筛选是count表达矩阵进入统计分析前的关键步骤。
如果不做筛选,后续聚类和差异分析的稳定性会下降。
4. 方法三:利用标签、合并和追加,理清数据来源
4.1 给元素命名,便于后续追踪
知识库提到,可以用names函数给向量打标签。对于长向量,标签能帮助识别每个元素含义。
这个思路同样适用于count表达矩阵的管理。虽然矩阵本身不是用names来做行列标注,但科研中常通过行名、列名来标识基因和样本。
标签的作用不是装饰,而是追踪。
一旦数据量变大,没有标签,矩阵就会变成一串难以解释的数字。
4.2 合并多个样本前,先确认配置文件
在单细胞流程里,多个样本的count结果可以通过合并命令整合成一个矩阵。知识库明确提到,合并前需要一个配置文件,关键是前两列:
- 第一列是样本名。
- 第二列是H5文件信息。
- 第三列分类可选。
这一步非常重要。
count表达矩阵能否正确合并,取决于样本信息是否完整。
如果样本名写错,或文件路径不对,合并结果就会偏离预期。
4.3 追加和合并的区别要分清
知识库中提到,向量可以通过追加组合成新向量。
在表达矩阵处理中,追加和合并不是同一个概念。追加更像把元素接在一起,而合并是按照样本和基因规则重组为完整矩阵。
对于count表达矩阵,真正重要的是合并逻辑,而不是简单拼接。
科研人员需要特别关注样本间是否保持一致的基因顺序和维度对应关系。
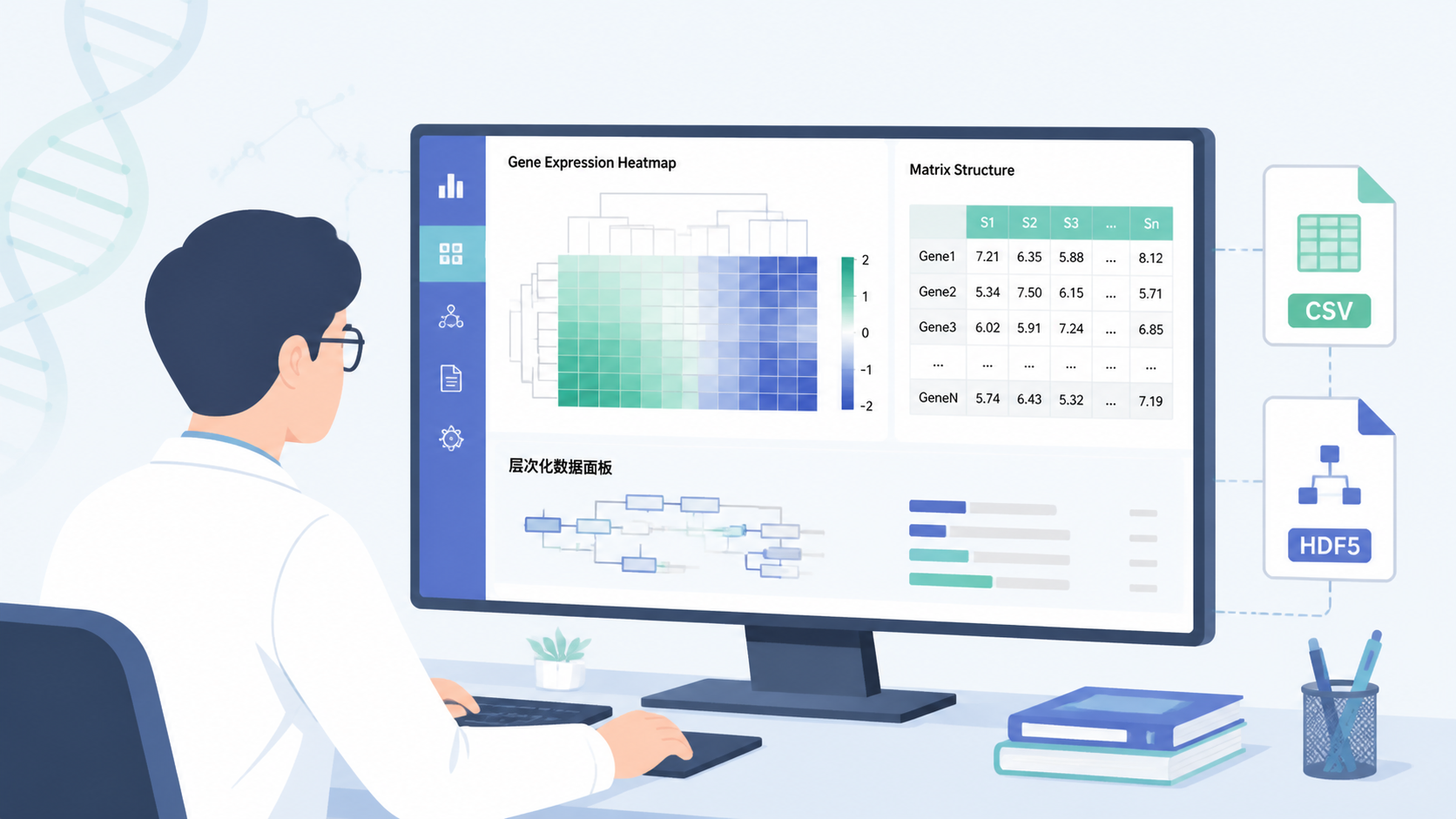
5. 方法四:把矩阵转成CSV,提升可读性和复核效率
5.1 CSV适合人工查看和审稿复核
知识库提到,合并后的矩阵可以通过mat to CSV转成CSV格式文件,并生成GSE117988.CSV这类结果文件。
对于count表达矩阵来说,这一步很实用。因为CSV更容易被Excel、R、Python或文本工具读取,也更方便人工核对。
当你需要快速检查矩阵内容时,CSV通常比原始格式更直观。
5.2 大矩阵先局部检查,再整体处理
知识库中也提醒,矩阵可能很大,建议先用较小数据集测试流程。
这是非常合理的科研习惯。面对count表达矩阵,先检查小样本或前几列,能显著减少计算错误。
建议顺序如下:
- 先看目录结构。
- 再确认count结果文件。
- 读取前几行和前几列。
- 最后再做全量转换和分析。
先验证流程,再放大处理,是处理大矩阵最稳妥的方式。
5.3 结合表达矩阵输出,避免后续返工
count表达矩阵一旦生成,后面的差异分析、聚类、细胞注释都会依赖它。
所以最值得投入时间的,不是“跑得多快”,而是“结果是否可信”。把矩阵转成CSV后做抽查,能有效发现:
- 行列是否对齐。
- 是否存在异常空值。
- 合并是否成功。
- 样本数是否符合预期。
这一步看似简单,却能节省很多返工时间。
总结Conclusion
count表达矩阵是转录组和单细胞分析的基础。掌握它,至少要做到四件事:先判断数据结构,再按行列提取,接着核对标签和来源,最后转成CSV复核。只要把这四步做扎实,后续分析会更稳,也更快。
对于医学生、医生和科研人员来说,真正的难点往往不是“有没有数据”,而是“能不能高效读懂数据”。如果你希望把count表达矩阵处理得更规范、更省时,可以借助解螺旋品牌 的流程化工具和内容支持,减少重复劳动,提升数据整理与分析效率。

- 引言Introduction
- 1. 先理解count表达矩阵是什么
- 2. 方法一:先用维度和长度判断数据是否完整
- 3. 方法二:按行列提取,快速读懂基因和样本
- 4. 方法三:利用标签、合并和追加,理清数据来源
- 5. 方法四:把矩阵转成CSV,提升可读性和复核效率
- 总结Conclusion