引言Introduction
RPKM表达矩阵常被用于RNA-seq结果展示,但很多人会把它和counts、FPKM、TPM混用,导致下游差异分析出错。如果你想知道RPKM表达矩阵到底该怎么构建、何时能用、何时不该用,这篇文章会给你一个清晰答案。

1. 先弄清RPKM表达矩阵的定位
1.1 RPKM不是差异分析的输入格式
主流差异分析工具如 limma、DESeq2、edgeR,输入都应是原始 counts。 这点非常重要。上游知识库明确指出,这些包都不需要基因长度校正,也不需要先做 log 转换。
也就是说,RPKM表达矩阵更适合做展示、聚类、相关性分析,或者作为某些可视化输入,而不是差异分析的首选数据。
1.2 为什么要做标准化
原始 read 数受两类因素影响。第一是测序深度,第二是基因长度。
测序越深,counts 越高,不代表真实表达一定更高。基因越长,被读到的概率也越大。
所以,构建RPKM表达矩阵的核心,就是先校正测序深度,再校正基因长度。
2. 明确RPKM的计算逻辑
2.1 先看公式思路
RPKM 的本质是把某个基因在某个样本中的 reads,按“每千碱基、每百万映射 reads”进行标准化。
你可以把它理解为两步:
- 按测序深度做归一化。
- 按基因长度做归一化。
这就是RPKM表达矩阵与原始counts矩阵的最大区别。
2.2 RPKM和TPM、FPKM的关系
知识库里强调,RPKM和FPKM的校正变量相同,区别在顺序。
- RPKM/FPKM:先校正测序深度,再校正基因长度。
- TPM:先校正基因长度,再校正测序深度。
因此,RPKM表达矩阵不具备像 TPM 那样严格的样本间总和一致性。
这也是为什么很多分析场景更推荐 TPM,而不是 RPKM。
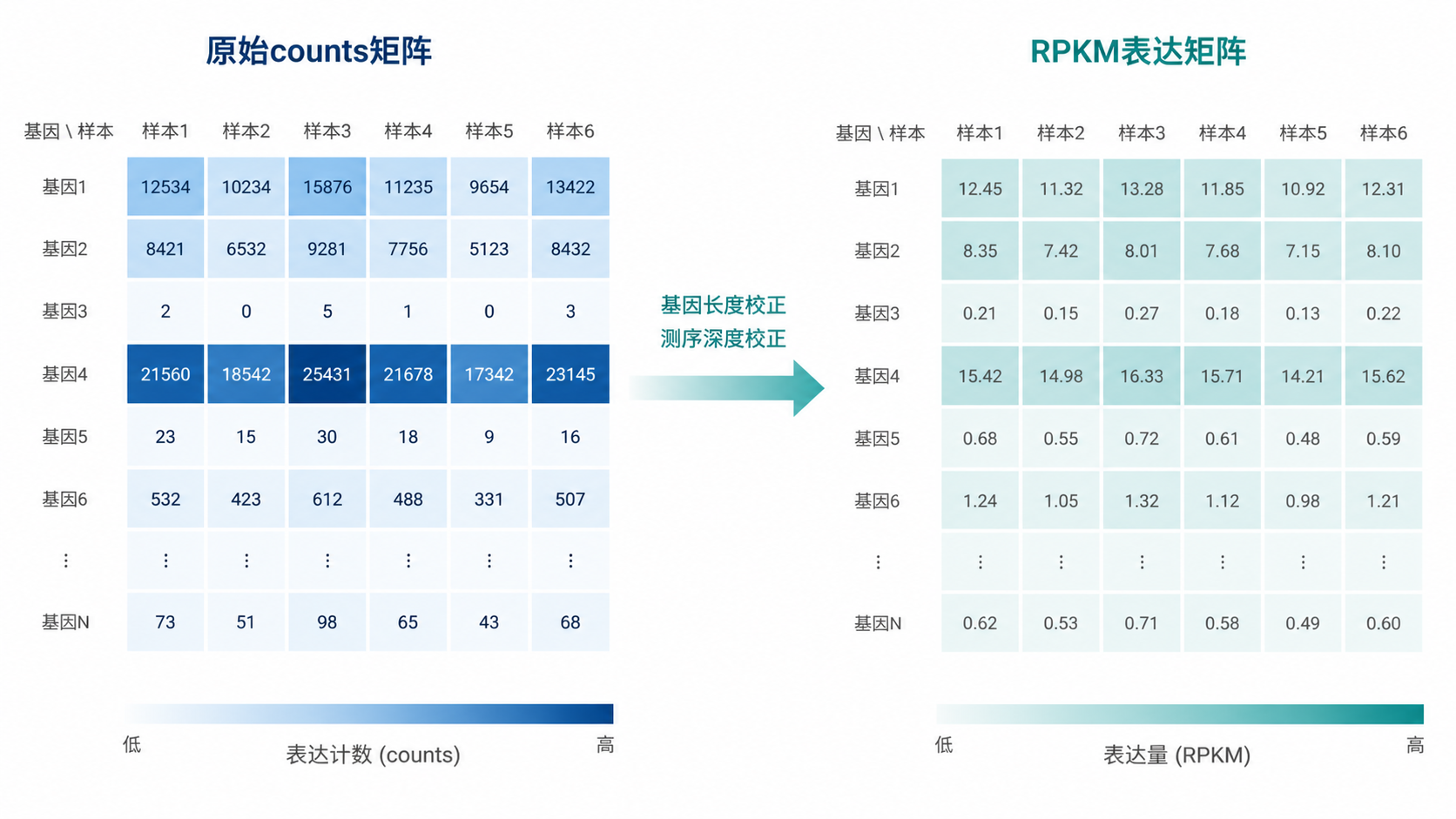
3. 构建RPKM表达矩阵的第1步:准备原始counts
3.1 输入必须是counts
上游知识库反复强调一点:limma、DESeq2、edgeR 的输入都是原始 counts 文件,不能先转化。
虽然本文讲的是RPKM表达矩阵,但构建之前的底层数据仍然应该来自原始counts。
常见输入形式包括:
- 基因ID
- 样本1 counts
- 样本2 counts
- 样本3 counts
如果有重复基因名,需要先合并。
3.2 处理重复基因名
在实际数据里,同一个 symbol 可能对应多条记录。知识库中提到,可以用平均值或分组汇总处理。
常见做法有两种:
- 取均值。
- 以 gene symbol 分组后汇总。
关键原则是先保证每个基因只保留一行,再进入矩阵构建。
4. 构建RPKM表达矩阵的第2步:整理基因长度信息
4.1 基因长度为什么必须有
RPKM 的长度校正依赖基因长度。
同样的表达水平,10 kb 基因天然比 1 kb 基因更容易被测到更多 reads。
如果不校正长度,长基因会被高估。
4.2 基因长度的来源
常见做法是从 GTF 文件中提取外显子信息,再计算有效长度。
知识库中也提到,实际处理时要注意:
- 去掉重叠外显子。
- 保证基因ID与表达矩阵一致。
- 不一致时要先做ID转换。
这一步很关键。因为基因长度文件和表达矩阵必须一一对应 ,否则后面算出来的RPKM表达矩阵会出错。
5. 构建RPKM表达矩阵的第3步:按测序深度标准化
5.1 先对每个样本求总reads
RPKM表达矩阵的第一层标准化,是按样本测序深度进行。
也就是先统计每个样本总 counts。知识库中的示例里,三个样本的总 reads 分别为 35、45、106,说明不同样本的测序深度并不一致。
5.2 为什么要除以百万
“每百万”是为了把不同样本拉到同一尺度上。
样本总reads通常在百万量级,用百万作为标准化因子更直观,也能避免结果太小,不方便展示。
实际操作时,通常是先将样本总 counts 换算成百万级别,再用每个基因的 counts 去除这个值。
6. 构建RPKM表达矩阵的第4步:按基因长度校正
6.1 长基因和短基因不能直接比较
知识库给出了一个很清晰的解释。
如果 A 基因是 2 kb,B 基因是 4 kb,B 基因会更容易获得更多 reads。
所以在做 RPKM 表达矩阵时,必须再除以基因长度。
6.2 校正后的结果怎么理解
校正后得到的数值,就更接近“真实表达强度”。
它的意义不是原始读段数,而是单位长度、单位测序深度下的标准化表达。
这类矩阵更适合做:
- 样本表达热图
- 基因表达分布图
- 相关性分析
- 某些可视化比较
但再次强调,它不应替代原始counts进入差异分析流程。
7. 构建RPKM表达矩阵的第5步:整理输出格式
7.1 输出成标准矩阵
最后一步,是把结果整理成标准的表达矩阵。通常格式如下:
- 第一列:gene symbol 或 gene ID
- 第二列开始:各样本的 RPKM 值
这时你得到的就是 RPKM表达矩阵。
7.2 输出前要检查三件事
建议在写出文件前检查:
- 行名是否正确。
- 列名是否对应样本。
- 是否有缺失值或重复值。
如果基因ID和样本名错位,后续所有分析都会受影响。
8. 为什么很多时候更推荐TPM而不是RPKM
8.1 RPKM和TPM的可比性不同
知识库明确指出,TPM 在样本间总和一致,因此更适合做样本间比较。
而 RPKM 的样本总和并不一致,所以样本间比较能力较弱。
8.2 实际应用建议
如果你的目标是:
- 差异分析,用原始counts。
- 样本间表达比较,优先考虑TPM。
- 展示历史文章流程,可能会见到RPKM表达矩阵。
因此,RPKM表达矩阵不是不能用,而是要用在合适场景。
9. 构建RPKM表达矩阵时最常见的3个错误
9.1 直接拿FPKM或TPM当counts去做差异分析
这是最常见的错误。
DESeq2、edgeR 等工具都要求原始 counts。
9.2 基因长度没处理好
如果外显子重叠没去掉,或者基因ID没对上,RPKM会失真。
9.3 混淆RPKM和TPM
两者虽然都做了长度校正,但顺序不同,结果不同。
RPKM表达矩阵不等于TPM矩阵。
10. 一个实用的判断标准
如果你手里的是:
- 原始 counts,先保留原样做差异分析。
- 需要可视化展示,再构建RPKM表达矩阵。
- 需要样本间更稳妥比较,优先考虑TPM。
这套思路能避免大多数RNA-seq下游错误。
总结Conclusion
RPKM表达矩阵的构建,本质上就是从原始counts出发,依次完成基因整理、长度校正、深度校正和矩阵输出。它适合展示和部分比较分析,但不适合直接替代counts做差异分析。
如果你希望把RNA-seq数据处理做得更规范,建议先掌握 counts、RPKM、TPM 的边界,再进入实际分析。
如果你想进一步提升数据处理效率,可以结合解螺旋 的科研内容与工具支持,把标准化、矩阵整理和下游分析流程做得更稳、更快。
- 引言Introduction
- 1. 先弄清RPKM表达矩阵的定位
- 2. 明确RPKM的计算逻辑
- 3. 构建RPKM表达矩阵的第1步:准备原始counts
- 4. 构建RPKM表达矩阵的第2步:整理基因长度信息
- 5. 构建RPKM表达矩阵的第3步:按测序深度标准化
- 6. 构建RPKM表达矩阵的第4步:按基因长度校正
- 7. 构建RPKM表达矩阵的第5步:整理输出格式
- 8. 为什么很多时候更推荐TPM而不是RPKM
- 9. 构建RPKM表达矩阵时最常见的3个错误
- 10. 一个实用的判断标准
- 总结Conclusion