引言Introduction
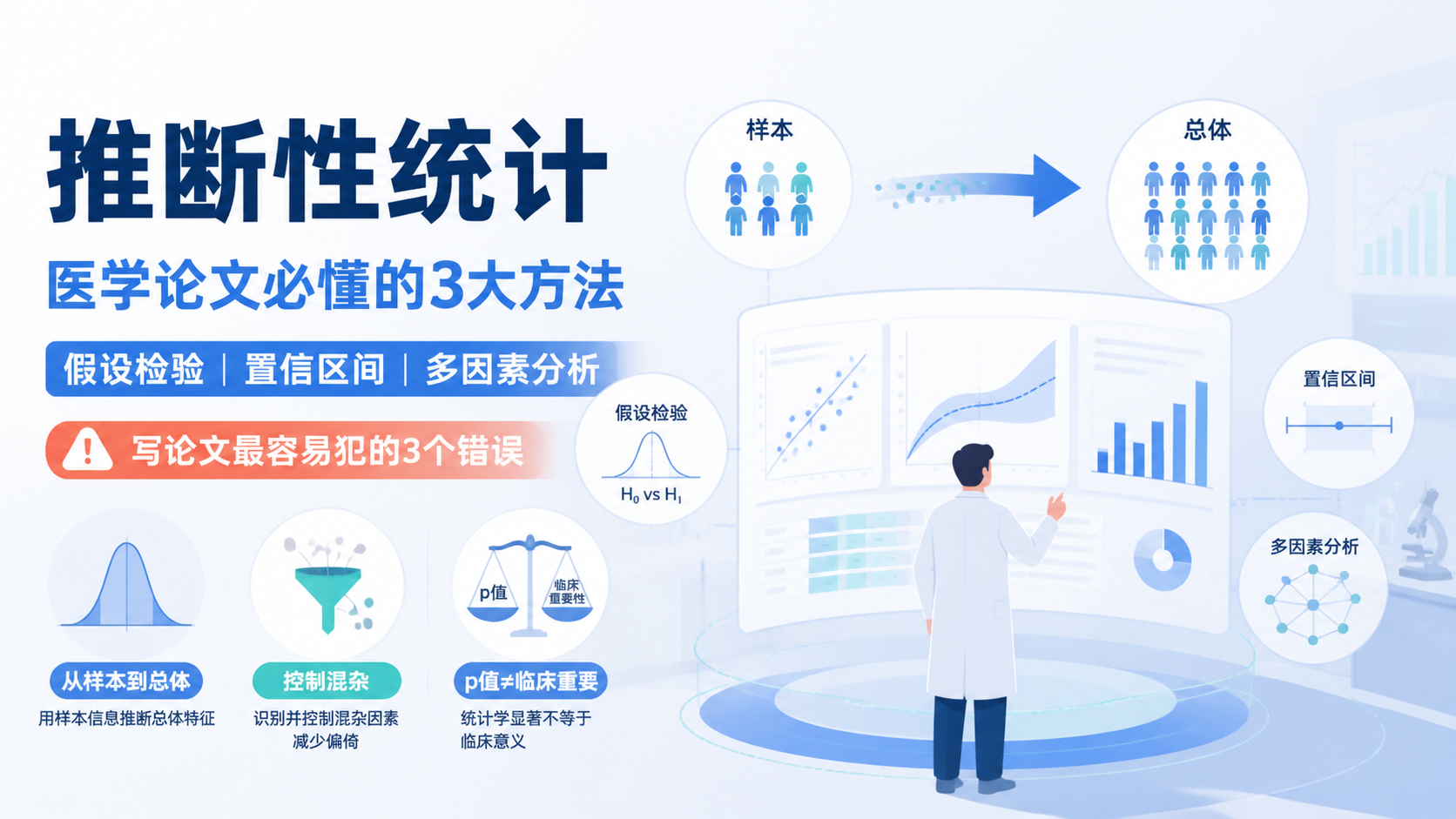
推断性统计 是医学研究中最常被误用,也最容易决定论文质量的部分。很多医学生和科研人员会卡在一个问题上, 如何从样本结果推到总体结论, 并判断这个结论是否可信。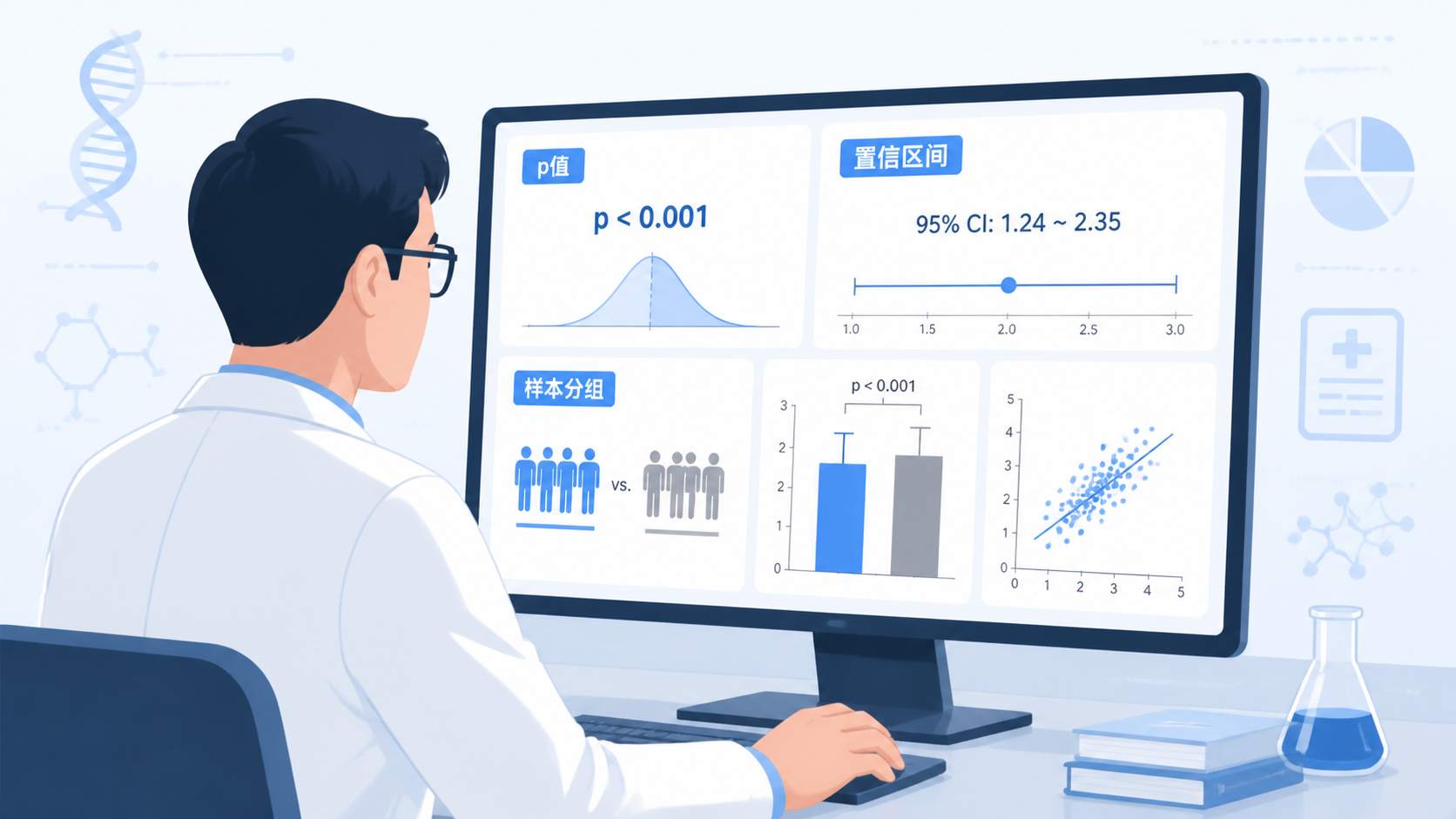
1. 推断性统计是什么
1.1 从样本到总体的核心逻辑
推断性统计 的任务,不是只描述样本,而是利用样本信息去估计总体,或检验总体间是否存在差异。
在临床研究里,这一步非常关键。因为我们通常无法观察全部患者,只能从抽样数据作判断。
它常见于两类研究场景。
第一类是组间比较,比如病例组和对照组。第二类是关联研究,比如暴露因素X与结局Y的关系。
前者关注差异是否存在,后者关注关系是否成立。
1.2 为什么医学论文离不开它
推断性统计 的核心价值在于处理“不确定性”。
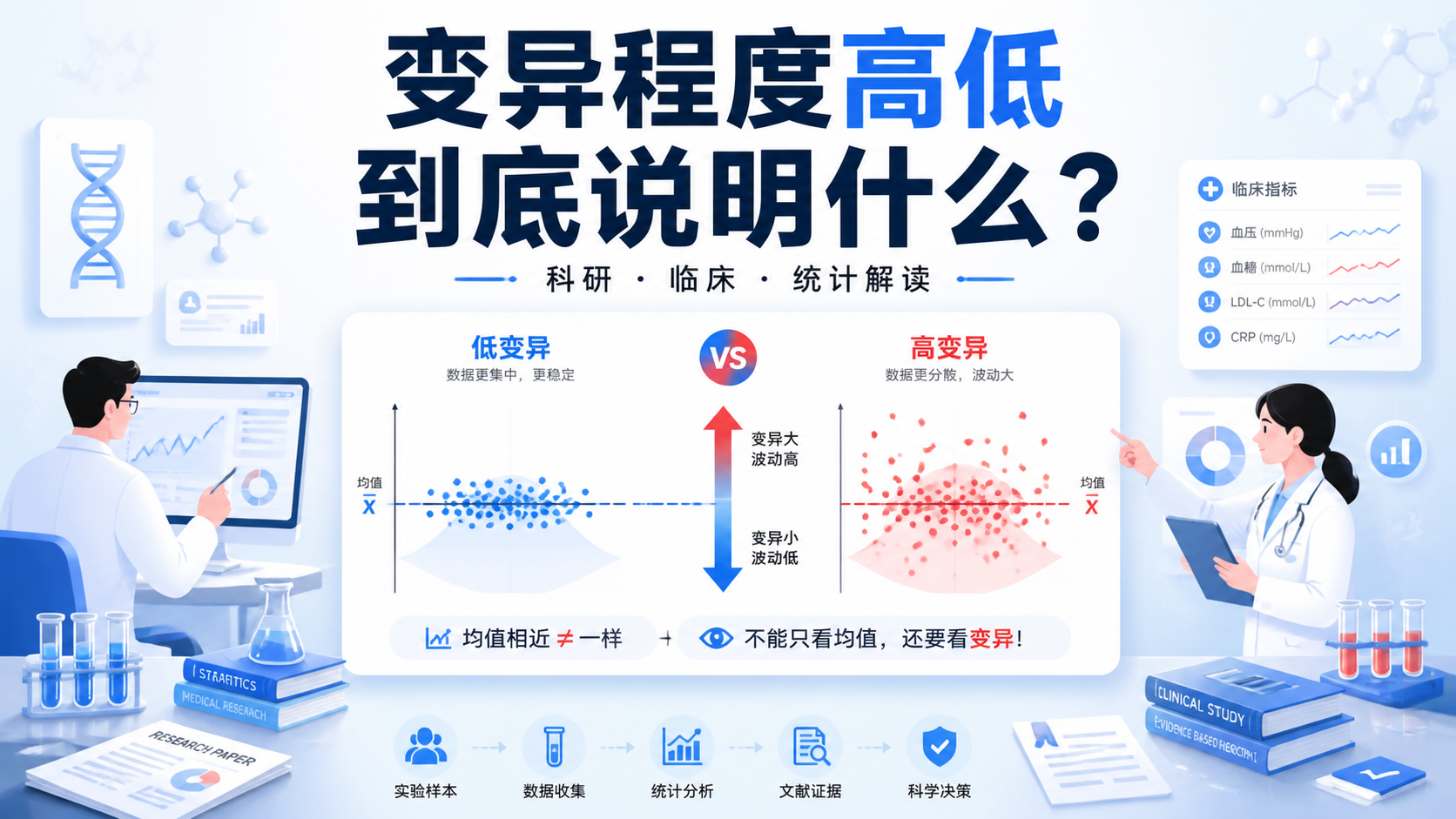
样本里看到的差异,不一定代表总体也有差异。
因此需要借助假设检验、置信区间和模型分析,判断结果是否具有统计学意义。
在表一分析中,组间差异常常是第一道关口。
如果变量分布不均衡,后续分析就可能受到混杂因素影响。
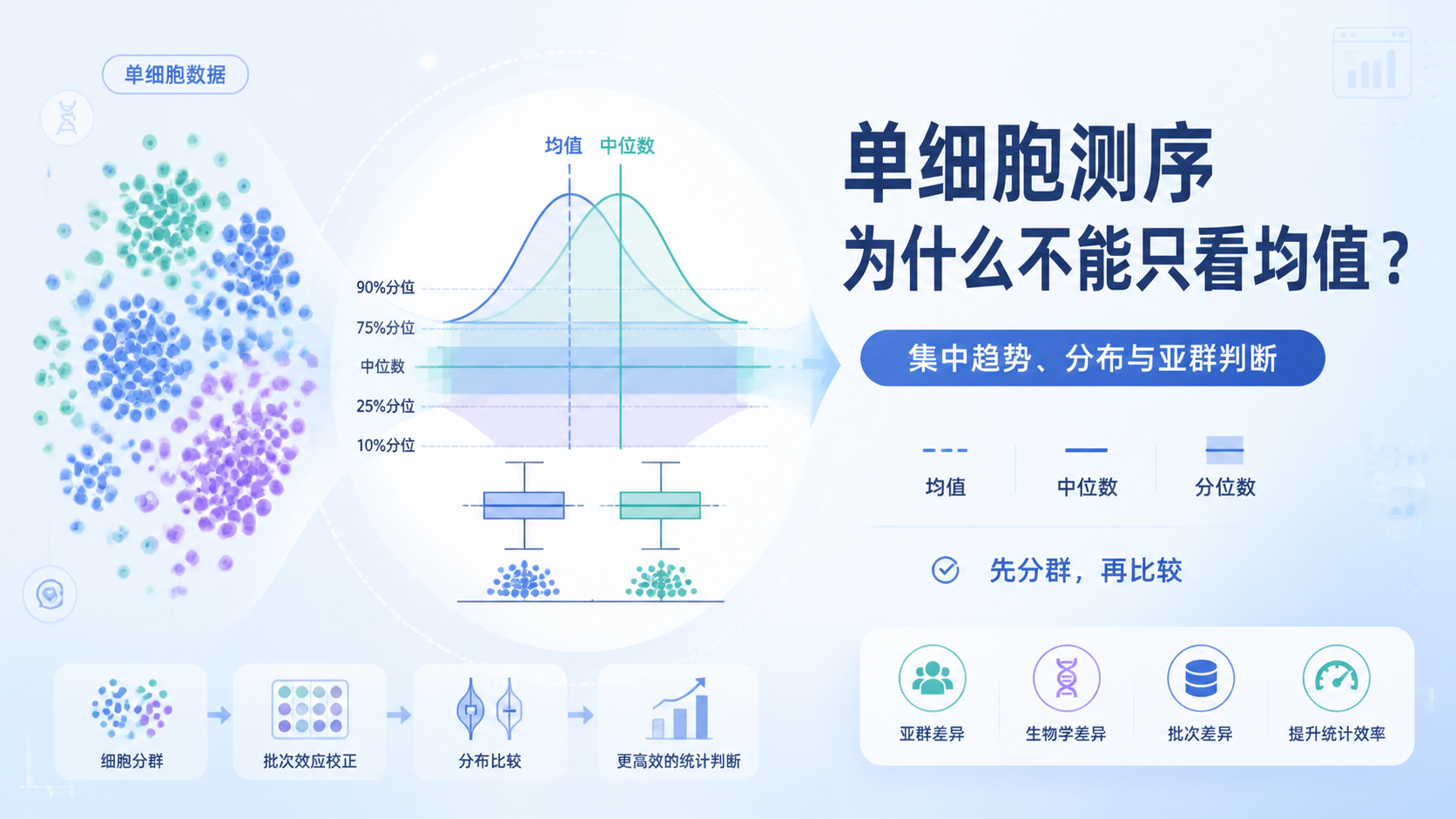
这也是为什么临床研究不能只看均值和比例,还要看统计学推断。
2. 推断性统计的3大方法
2.1 假设检验,判断差异是否显著
假设检验是最基础的推断性统计方法。
它的逻辑很简单。先提出“无差异”的原假设,再看样本数据是否足以推翻它。
在组间差异分析中,常见规则是:
- p值小于0.05,通常认为差异具有统计学意义。
- p值大于0.05,通常认为差异没有统计学意义。
不同数据类型,对应不同检验方法。
连续型变量两组比较,常用独立样本t检验。
三组及以上比较,常用方差分析。
分类资料则常用卡方检验。
2.2 置信区间,判断结果有多稳定
如果说p值回答“有没有差异”,那么置信区间回答的是差异有多大,范围有多稳 。
这对临床判断很重要,因为单看p值,容易忽略效应量的实际意义。
在临床相关性研究中,模型结果常见“HR、OR、β值”和95%置信区间。
例如,回归分析输出Exp(B)及其95%CI,就是在说明效应大小和不确定范围。
如果置信区间跨越无效值,通常提示结果不稳定。
这也是论文写作中必须重视的部分。
因为统计学显著,不等于临床上有意义。
真正有价值的结论,往往同时满足“显著”和“有解释力”。
2.3 多因素分析,控制混杂后再判断
观察性研究最常见的问题,是混杂因素。
混杂因素可能同时与X和Y相关,从而歪曲真实关系。
比如研究吸烟与血压时,年龄就可能是混杂因素。
这时,推断性统计 不能停留在单纯的组间比较。
还要进一步做多因素分析。
常见做法包括把混杂因素纳入模型,或进行分层分析。
在关联研究中,表一的作用就是帮助识别潜在混杂因素。
我们希望除主要暴露因素外,其余变量尽量均衡可比。
如果不均衡,也可以通过模型调整,尽量接近真实效应。
3. 实战中如何选择方法
3.1 两组比较看什么
当你面对两组数据时,先看变量类型,再看分布。
如果是连续型变量且满足正态分布,优先考虑t检验。
如果不满足正态,通常需要考虑非参数方法。
如果是分类变量,则通常考虑卡方检验。
在SPSS中,独立样本t检验是最常见的操作之一。
结果里要重点看两部分。
一是Levene检验,用于判断方差齐性。
二是t值和p值,用于判断组间差异是否显著。
若方差不齐,不能直接读取“假设方差相等”的结果,要看“假设方差不相等”那一行。
这类细节,直接影响结果是否写对。
3.2 三组及以上比较怎么做
当比较对象超过两组时,常用方差分析。
前提仍然是:数据尽量满足正态分布,并且要先判断方差齐性。
如果整体p值大于0.05,通常认为各组均数没有显著差异。
如果p值小于0.05,说明至少有两组不同。
这时不能停在整体结论上。
还要继续做两两比较,找出到底是哪两组不同。
常见方法包括LSD、Bonferroni、SNK等。
整体检验解决“有没有”,两两比较解决“谁和谁不同”。
3.3 关联研究如何处理混杂
在推断性统计里,关联研究比单纯组间比较更复杂。
因为你不仅要看X和Y之间的关系,还要排除其他因素的干扰。
这时多因素模型非常重要。
常见思路是:
- 先做单因素分析,筛查可能相关的变量。
- 再把候选混杂因素纳入模型。
- 最后观察主要暴露因素的效应是否仍然存在。
如果调整后关联仍然稳定,结论更可信。
如果调整后消失,说明原始结果可能受混杂影响较大。
这就是推断性统计在临床研究中的真正价值。
4. 写论文时最容易犯的3个错误
4.1 只写p值,不写数据本身
很多初学者只报“P<0.05”,却不写均值、标准差、比例或效应量。
这样读者无法判断差异大小,也不利于复核。
统计结果应该同时包含描述信息和推断信息。
4.2 方法和数据类型不匹配
连续变量、分类变量、正态与非正态数据,方法都不同。
如果把t检验用在不合适的数据上,结果就不可靠。
同样,三组以上数据不能还停留在两组比较思维里。
4.3 把统计显著等同于临床重要
这是最常见的误区。
样本量足够大时,极小差异也可能显著。
但临床上未必有意义。
所以论文写作时,必须结合效应量、置信区间和实际背景综合解释。
总结Conclusion
推断性统计的核心,不是“算出一个p值”这么简单,而是用规范的方法,从样本走向可信结论。
它在医学研究中主要体现在三类任务:假设检验、置信区间和多因素分析。
前者判断差异是否显著,中者判断结果是否稳定,后者用于控制混杂、提高结论可信度。
如果你正在写论文、做课题,或者整理SPSS结果,建议先把变量类型、分组方式和研究目的理清,再选择对应方法。
这样才能避免常见统计错误,让表一、比较分析和模型结果真正服务于研究问题。
如果你希望更高效地完成统计分析、三线表整理和论文结果表达,可以结合解螺旋品牌的科研工具与课程体系,系统提升实操效率。

- 引言Introduction
- 1. 推断性统计是什么
- 2. 推断性统计的3大方法
- 3. 实战中如何选择方法
- 4. 写论文时最容易犯的3个错误
- 总结Conclusion