引言Introduction
描述性统计是临床研究的起点。 很多医学生和年轻医生做数据分析时,常卡在“该用均值还是中位数”“分类变量怎么写”这些基础问题上。其实,只要先分清数据类型,再选对描述方式,报告就会更规范,也更接近论文发表要求。

1. 什么是描述性统计
1.1 先回答“数据长什么样”
描述性统计的核心任务,是把一组数据的基本特征讲清楚。 它不负责推断因果,也不直接回答“有没有差异”,而是先把样本的年龄、性别、病史、检验值等信息整理出来。
在临床研究里,这一步非常关键。因为后续的统计推断,必须建立在清晰的样本描述基础上。若连数据分布都没搞清楚,后面的检验方法就可能选错。
1.2 描述性统计在临床研究中的作用
临床研究通常先做三件事。
- 描述样本特征。
- 比较组间差异。
- 进一步进行效应量估计。
其中,描述性统计是第一步。它能帮助读者快速判断研究对象是否具有代表性,也能帮助审稿人判断分组是否均衡。
对医学生来说,描述性统计的价值不只是“写表1”,而是建立统计思维。 你需要先知道样本是什么,再谈研究结论。
2. 先分清数据类型,再决定怎么描述
2.1 定量数据与定性数据
描述性统计最重要的前提,是区分数据类型。上游知识库提示,临床数据大致分为两类。
- 定量数据 :如年龄、BMI、住院天数、实验室指标。
- 定性数据 :如性别、有无高血压、病理分型、分级资料。
定量数据还可分为连续型和离散型。定性数据则常见于二分类、无序多分类和有序多分类。
数据类型选错,描述方式就会错。 这是临床统计最常见的入门错误。
2.2 连续变量怎么描述
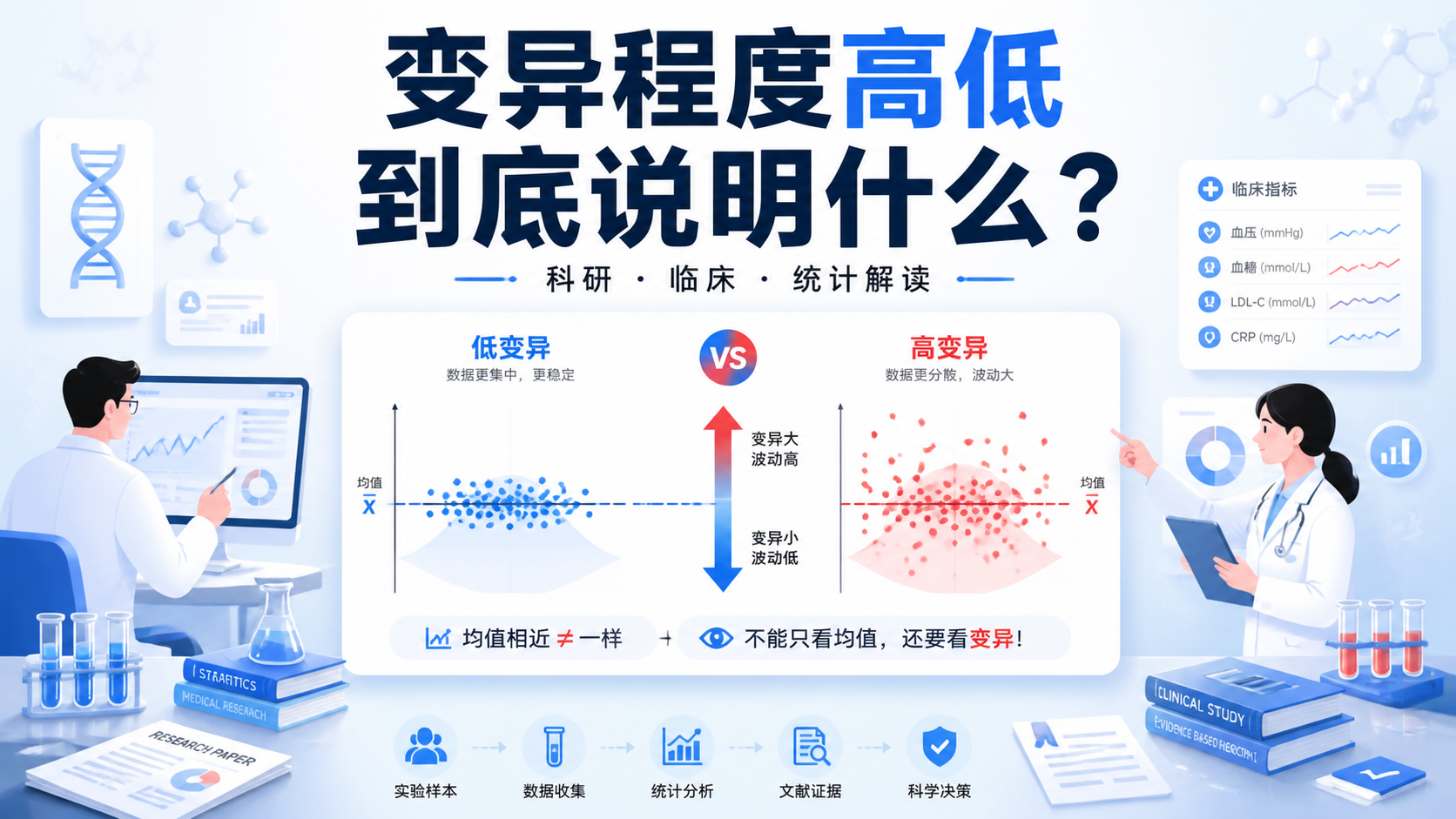
对于连续型变量,最常见的判断标准是分布。
- 正态分布 :用均值 ± 标准差表示。
- 非正态分布 :用中位数和四分位间距表示。
例如,BMI如果近似正态分布,可以写成“21.3 ± 3.5”。如果住院费用明显偏态,就更适合写“中位数(四分位间距)”。
这里要记住一个原则。均值反映集中趋势,标准差反映离散程度。 中位数更适合偏态数据,因为它不容易被极端值拉偏。
2.3 分类变量怎么描述
分类变量通常用频数和构成比表示。
例如:
- 男性 58 例,女性 42 例。
- 高血压史 31 例,占 31%。
- 病理类型为腺癌、鳞癌、其他。
二分类资料看“有或无”,多分类资料看“各类别占比”。 这类数据不需要均值和标准差,因为它本身不是连续测量值。
3. 统计描述的常用写法
3.1 正态分布连续数据的写法
如果数据满足正态分布,论文中常写成“均值 ± 标准差”。这是最常见的描述方式。比如某组患者年龄为 50.2 ± 12.1 岁。
这种写法有两个信息。
- 平均水平是多少。
- 个体差异有多大。
标准差越大,说明样本离散程度越高。 这意味着患者之间差别更明显,群体更不均一。
3.2 非正态连续数据的写法
对于偏态分布数据,更适合用中位数和四分位间距。知识库中提到,文献里常见三种写法,需要特别注意注释。
常见表达包括:
- 中位数(Q1,Q3)。
- 中位数(IQR)。
- 中位数(最小值,最大值)。
写论文前,一定要看清括号里到底表示什么。 否则很容易把四分位间距和极值范围混淆。
3.3 分类变量的写法
分类变量一般写成“n(%)”。比如:
- 男性 60 例(60.0%)。
- 吸烟史 22 例(22.0%)。
- 3 级高血压 18 例(18.0%)。
这种写法最简洁,也最符合临床论文常规。
如果是有序分类变量,还可以按等级逐层列出。这样更利于展示疾病严重程度、功能分级或疗效分层。
4. 做描述性统计时最容易犯的错
4.1 不看分布就直接上均值
这是最常见的问题。很多人一看到连续变量,就默认写均值 ± 标准差。实际上,如果数据明显偏态,均值会被极端值影响,容易误导读者。
先看分布,再选指标。 这是描述性统计的基本规则。
4.2 把分类变量写成均值
分类变量不能写均值。比如“性别均值为 0.4”没有临床意义。对于这类数据,应直接报告频数和比例。
4.3 混淆统计描述和统计推断
描述性统计只负责“描述”,不负责“比较”。
如果你要比较两组年龄差异,那已经进入统计推断范畴,常常需要 t 检验或秩和检验。
不要把描述表和检验结果混为一谈。
4.4 盲目模仿文献
上游知识库强调,学习统计不能只靠照搬。别人用高级模型,不代表你的数据也适合。你需要先判断应用场景、适应症和禁忌症,再决定是否使用。
对医学生而言,模仿文献的重点不是“抄方法”,而是“学判断”。
5. 临床研究里怎么快速上手
5.1 第一步,看变量类型
拿到一份数据后,先把变量分成三类。
- 连续变量。
- 二分类变量。
- 多分类变量。
这一步看似简单,却决定了后续所有描述方式。
5.2 第二步,看分布情况
连续变量先判断是否正态分布。常见做法是结合直方图、Q-Q图,或参考统计软件输出结果。
如果近似正态,就用均值 ± 标准差。
如果偏态明显,就用中位数和四分位间距。
5.3 第三步,统一表格格式
临床论文里最常见的是“表1 基线特征”。建议保持格式一致。
- 连续正态:均值 ± 标准差。
- 连续偏态:中位数(四分位间距)。
- 分类变量:n(%)。
统一格式不仅更规范,也更利于审稿和复现。
5.4 第四步,结合软件实操
知识库明确指出,统计学习不能停留在公式层面。对临床医生来说,真正重要的是软件操作。先会导入数据,再会生成描述表,最后学会解释结果。
文献学习 + 软件实操,才是最快的掌握路径。
6. 为什么医学生必须掌握描述性统计
6.1 它是论文写作的第一步
无论是临床回顾性研究、病例对照研究,还是队列研究,第一张表通常都是描述性统计。它帮助你建立样本全貌,也是读者理解研究的入口。
6.2 它是后续分析的基础
如果你连变量类型都没分清,就很难判断后面该用什么统计方法。描述性统计做得好,后续的统计推断和效应量估计才有基础。
6.3 它能反映你的统计思维
很多临床科研能力,不在于会不会高级模型,而在于能不能把基础数据讲明白。会描述数据,才算真正迈入临床研究门槛。
总结Conclusion
描述性统计不是简单的“列数字”,而是临床研究的基本功。 你只要记住三件事,就能快速入门。
- 先分清定量和定性数据。
- 连续变量先看分布,再决定用均值 ± 标准差,还是中位数和四分位间距。
- 分类变量用频数和构成比表示。
对于医学生、医生和科研人员来说,最重要的不是背公式,而是形成稳定的判断框架。先看变量类型,再看数据分布,最后选择正确表达方式。
如果你希望把描述性统计真正用于论文写作、数据整理和结果呈现,可以借助解螺旋 的临床科研学习与工具支持,减少方法误用,提高写作效率,让数据展示更规范、更接近发表标准。

- 引言Introduction
- 1. 什么是描述性统计
- 2. 先分清数据类型,再决定怎么描述
- 3. 统计描述的常用写法
- 4. 做描述性统计时最容易犯的错
- 5. 临床研究里怎么快速上手
- 6. 为什么医学生必须掌握描述性统计
- 总结Conclusion