引言Introduction
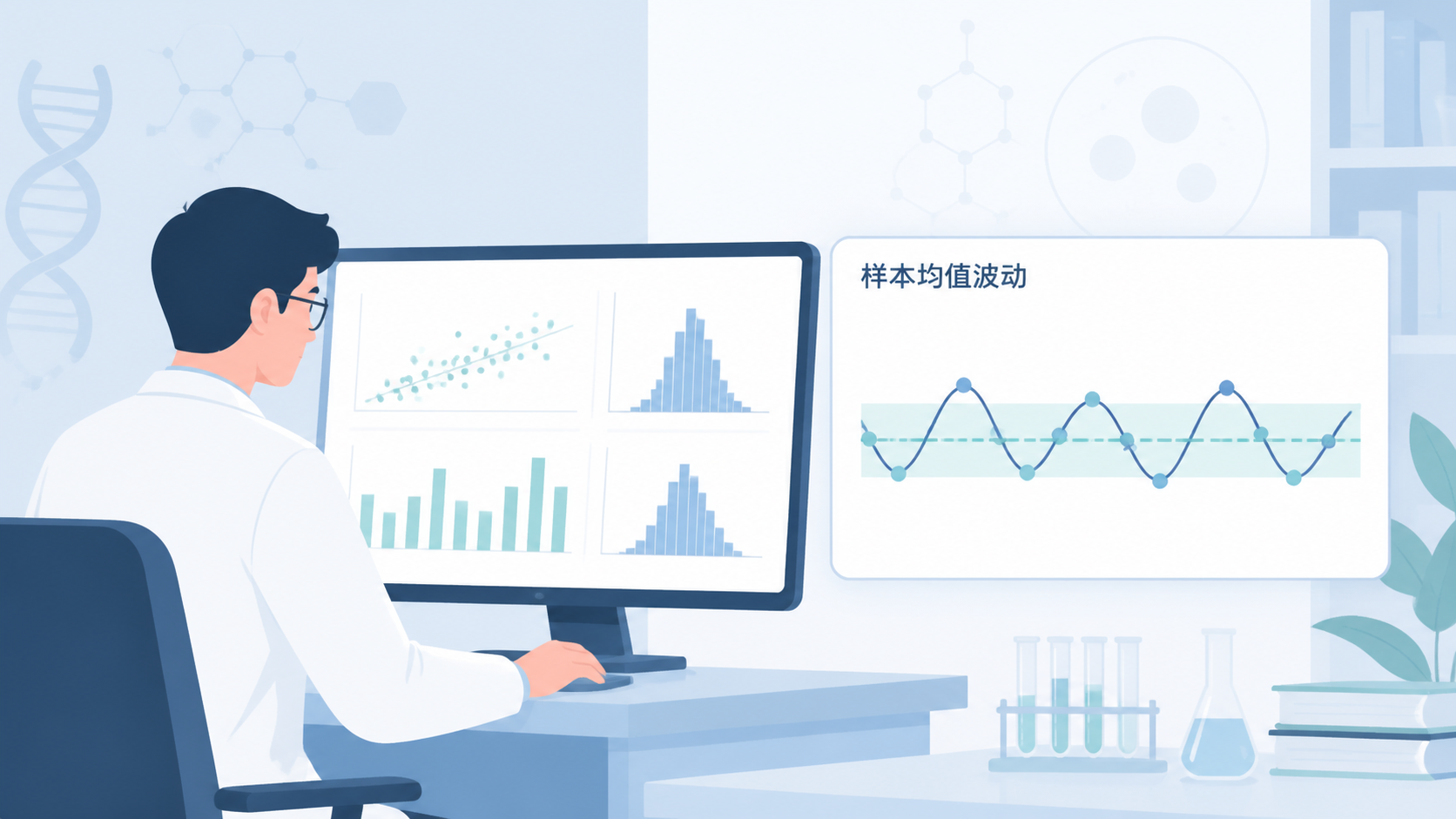
在临床研究、论文阅读和统计分析中,很多人把“样本结果不稳定”误以为是分析出错。其实,抽样误差 才是更常见的原因。它决定了你用样本推断总体时,结论会偏离多少。对医学生、医生和科研人员来说,先看懂抽样误差 ,才能正确理解均值、标准差、标准误和P值。
1. 抽样误差到底是什么
1.1 用一句话说明白
抽样误差 ,就是用样本统计量去估计总体参数时,样本结果与总体真实值之间的差距。它不是“数据错了”,而是“抽样天然会波动”。
比如你想估计10岁儿童的平均身高,不可能测量全部儿童,只能随机抽取100人。你今天抽到的平均身高,和明天再抽100人得到的平均身高,通常不会完全一样。这种差异,就是抽样误差 的表现。
1.2 为什么它不可避免
只要研究依赖抽样,就一定存在抽样误差 。原因很简单。样本只是总体的一部分,而且每次抽到的个体组合不同,结果就会波动。
在统计推断里,这种波动是正常现象。它不等于偏倚,也不等于分析错误。真正的问题是,研究者有没有意识到这种误差,并用合适的方法去控制和报告。
1.3 抽样误差和系统误差不是一回事
很多初学者会把两者混在一起。其实二者差别很大。
- 抽样误差 :随机产生,样本不同,结果会自然波动。
- 系统误差 :来自设计或执行问题,会让结果稳定地偏向某个方向。
抽样误差 可以通过增加样本量、优化抽样方法来减小。系统误差则要靠研究设计去避免,比如随机化、盲法、统一测量流程。
2. 抽样误差为什么会出现
2.1 随机抽样决定了波动
如果抽样完全随机,那么每个样本都可能略有不同。即使总体完全不变,抽样结果也会变。
这就是为什么同一项研究,样本量较小时结果更不稳定。因为样本少,偶然性更强。样本越大,结果越接近总体真实情况。
2.2 样本量越小,抽样误差越大
这是临床研究中最重要的经验之一。样本量越大,抽样误差通常越小。
原因在于,大样本更能抵消个体差异带来的随机波动。相反,小样本特别容易受极端值影响。比如只抽10个人,抽到几个高值或低值,就可能明显拉动均值。
2.3 数据离散程度也会影响误差
如果总体本身差异很大,样本之间的波动也会更大。换句话说,总体标准差越大,抽样误差往往越明显 。
这也是为什么在文献中,研究者常同时关注均值和标准差。均值看中心位置,标准差看离散程度。两者结合,才能更完整地理解样本特征。
3. 抽样误差、标准差、标准误的区别
3.1 标准差描述的是数据本身的离散
标准差 反映的是样本内部各个数据点围绕均值的分散程度。它回答的是:这些个体本身分散不分散。
例如一组血压数据,如果个体值差别很大,标准差就会大。它是描述性统计里最常见的离散指标之一。
3.2 标准误描述的是抽样均值的波动
标准误 和抽样误差关系更近。它反映的是“多次抽样得到的样本均值”围绕总体均值波动的程度。它本质上是在量化抽样误差。
常见公式是:
- 标准误 = 标准差 / 根号n
这说明,样本量n越大,标准误越小,抽样误差也越小 。
3.3 不能把标准误当成标准差
在统计描述中,正态分布的连续资料通常用“均值±标准差”表示,而不是“均值±标准误”。
原因是,描述样本本身时,应该用标准差;标准误主要用于统计推断。若在方法部分写清楚,也可以在图示或特定表达中使用标准误,但不能混淆二者含义。
4. 如何判断抽样误差是否“可接受”
4.1 看样本量
样本量是控制抽样误差 最直接的因素之一。一般来说,样本越大,误差越小,估计越稳定。
这也是为什么很多研究会在正式开展前进行样本量估算。样本量设计不是形式,而是为了保证研究结果有足够精度和把握度。
4.2 看数据分布
如果数据接近正态分布,均值的代表性通常更好。如果数据明显偏态,单纯用均值描述就可能不够稳妥,常要结合中位数和四分位数。
也就是说,数据分布决定了你怎么描述,抽样误差也会随着分布特征而表现不同 。
4.3 看研究目的
如果你只是做样本描述,重点是展示样本的实际情况。如果你要从样本推断总体,就必须关注误差大小、置信区间和假设检验。
在推断研究里,抽样误差 不是附属概念,而是决定结论可靠性的核心因素。
5. 抽样误差在临床研究中的实际意义
5.1 解释“同一研究,不同结果”
很多人读文献时会困惑:为什么不同研究对同一个问题得出的结果不一样。一个重要原因就是抽样误差 。
即使研究主题相同,只要抽到的样本不同,均值、效应量和P值都可能变化。这就是为什么临床研究强调重复性和多中心设计。
5.2 影响P值和结论稳定性
当样本量太小,抽样误差变大,组间差异就更容易被偶然波动掩盖,导致P值不稳定。此时,即使真实存在差异,也可能因为统计把握度不足而检不出来。
这也是为什么在研究设计阶段要兼顾α和β,控制假阳性和假阴性风险。抽样误差越大,研究结论越不稳。
5.3 影响论文写作和审稿判断
在论文结果部分,如果研究者只报均值,不报离散指标,读者就很难判断数据稳定性。规范写法应结合数据类型,清楚报告均值、标准差或中位数、四分位数。
对于科研人员来说,理解抽样误差 ,能帮助你更准确地解释结果,也能避免过度解读单次研究发现。
6. 研究者如何减少抽样误差
6.1 增加样本量
这是最直接的方法。样本量增加,标准误下降,抽样误差通常也会减小。
对于需要推断总体的研究,这一点尤其关键。
6.2 使用随机抽样
随机抽样能减少样本选择带来的偏差,使样本更接近总体。它不能消灭抽样误差,但能让误差更符合随机波动的本质。
6.3 统一测量和入组标准
虽然这更多是控制偏倚,但也有助于减小不必要的波动。测量流程越一致,数据越稳定,结果越容易解释。
6.4 报告置信区间
置信区间能告诉读者估计值的不确定范围。它比单独报一个点估计更完整,也更符合严谨的临床研究表达。
总结Conclusion
抽样误差 不是研究失败,而是抽样研究中不可避免的随机波动。它告诉我们,样本结果和总体真实值之间总会有差距。理解它,才能正确区分标准差与标准误,理解样本量、P值和置信区间的意义。
对医学生、医生和科研人员来说,真正重要的不是“有没有误差”,而是“误差有多大,是否可接受”。如果你想把统计概念学得更快、更系统,可以借助解螺旋 的临床研究与统计课程,把抽样、描述、推断一步步吃透。
- 引言Introduction
- 1. 抽样误差到底是什么
- 2. 抽样误差为什么会出现
- 3. 抽样误差、标准差、标准误的区别
- 4. 如何判断抽样误差是否“可接受”
- 5. 抽样误差在临床研究中的实际意义
- 6. 研究者如何减少抽样误差
- 总结Conclusion