引言Introduction
很多人把标准误 和标准差混为一谈,导致文献解读、数据描述和统计推断都容易出错。对于医学生、医生和科研人员来说,先弄清标准误 是什么,才能正确理解样本结果能否代表总体。
1. 先分清:标准误不是标准差
1.1 两者的核心区别
标准差描述的是数据本身的离散程度。
它回答的是,样本里的每个数,离平均值有多分散。
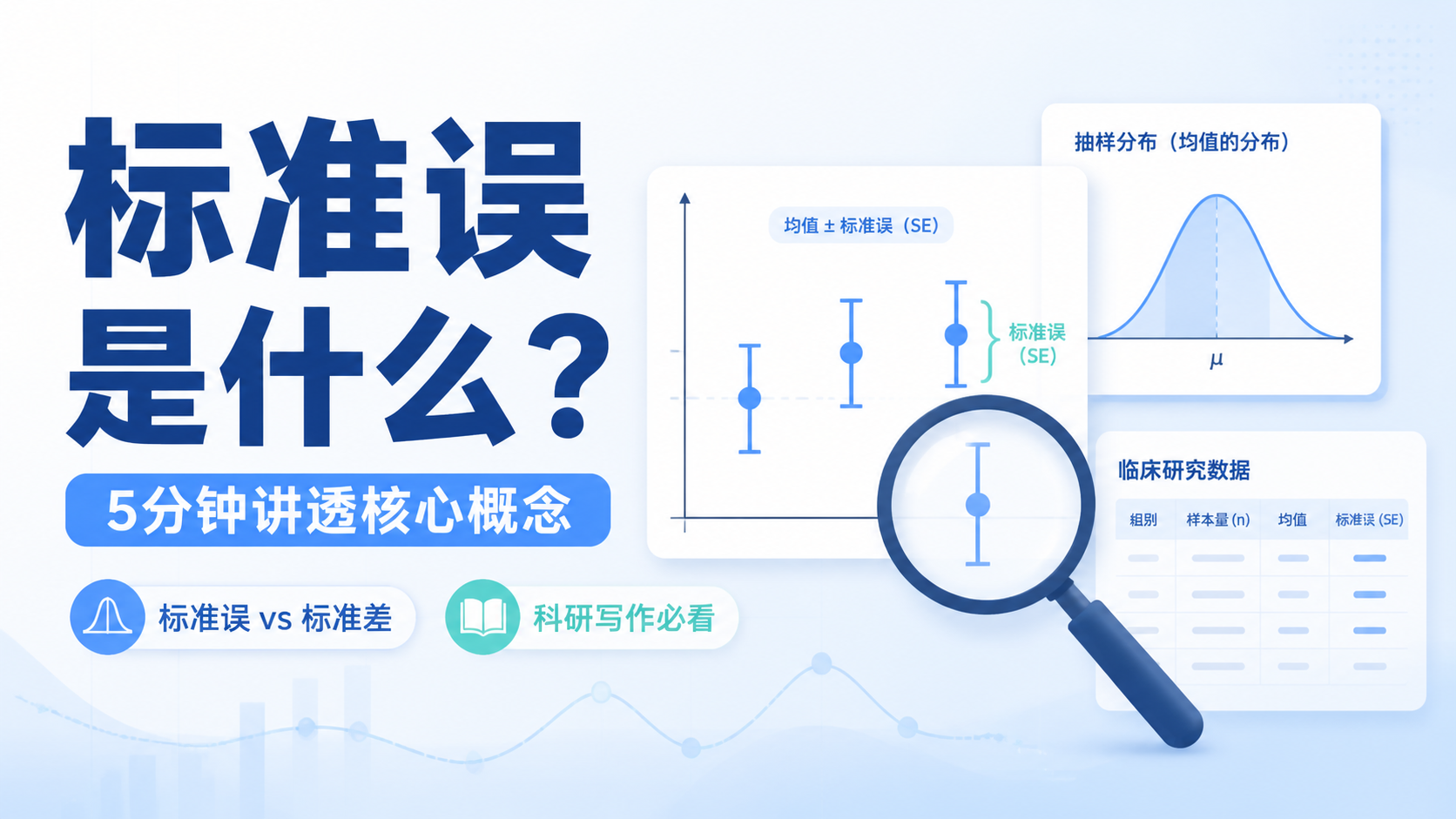
标准误描述的是样本统计量的抽样误差。
它回答的是,如果重复抽样,样本均值会围绕总体均值波动多大。
简单说,标准差看“个体差异”,标准误看“均值稳定性”。
1.2 公式上的联系
在常用统计表达中,标准差与标准误有明确关系。
- 标准差,反映离散程度。
- 标准误,通常等于标准差除以根号n 。
- n越大,标准误越小。
这意味着样本量越大,样本均值越稳定,作为总体估计也越可靠。
1.3 为什么临床研究里容易混淆
很多论文图表里会写“mean ± SE”或“mean ± SD”。
两者都常见,但含义完全不同。
如果是在做样本描述,通常应报告均值±标准差。
因为这是在描述已观察到的数据,不是在推断总体。
如果是在做统计推断,才会更常看到标准误。
这也是为什么很多初学者在看图时会觉得误差线“很短”或“很长”,其实可能只是作者用的是标准误,不是标准差。
2. 标准误到底是什么
2.1 它反映的是抽样误差
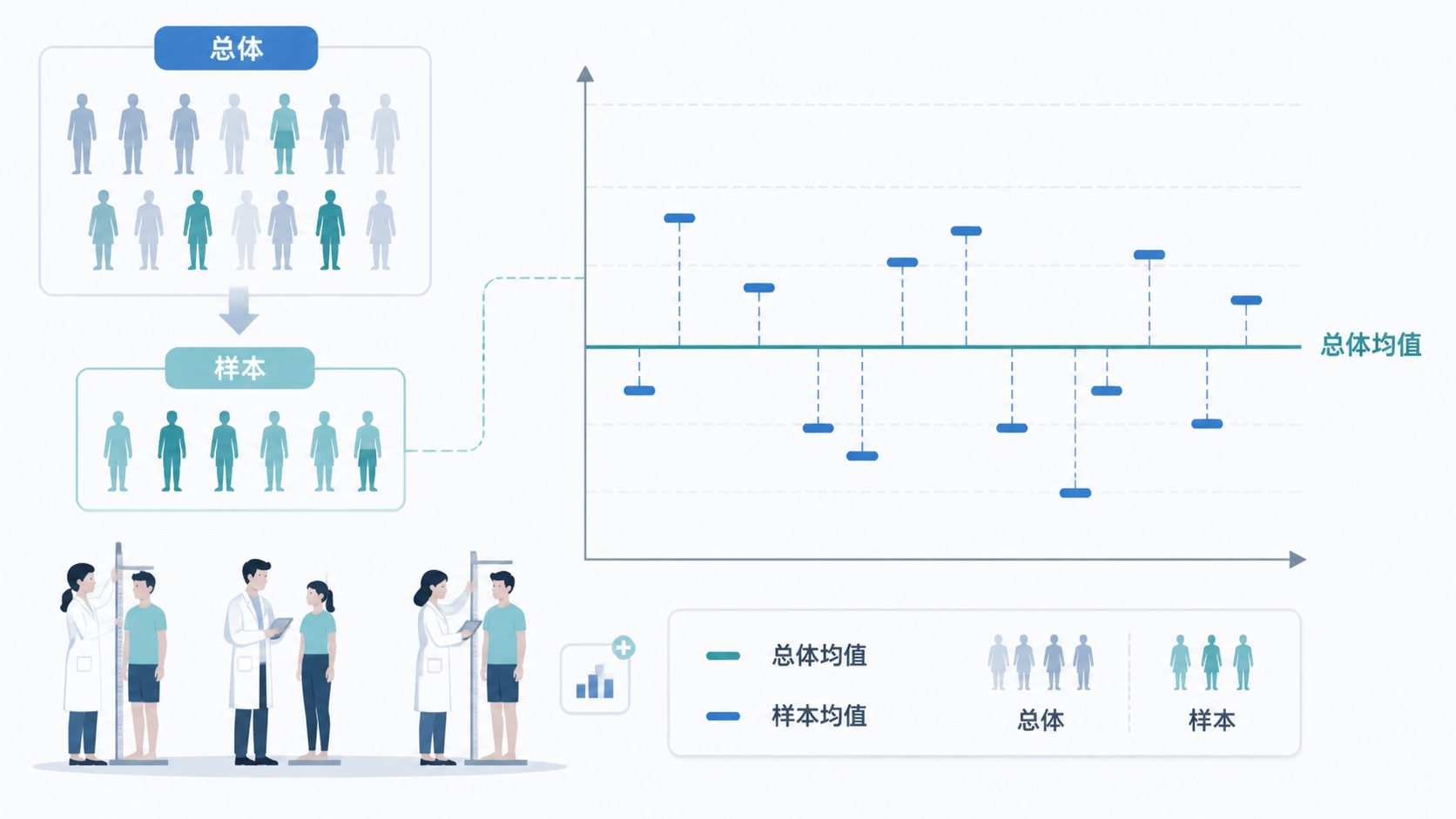
在临床研究中,我们几乎从不观察“全部总体”,而是抽取样本。
比如研究某地区10岁儿童身高,不可能测遍所有儿童,只能抽样。
样本均值不是总体均值本身。
它只是总体均值的估计值。
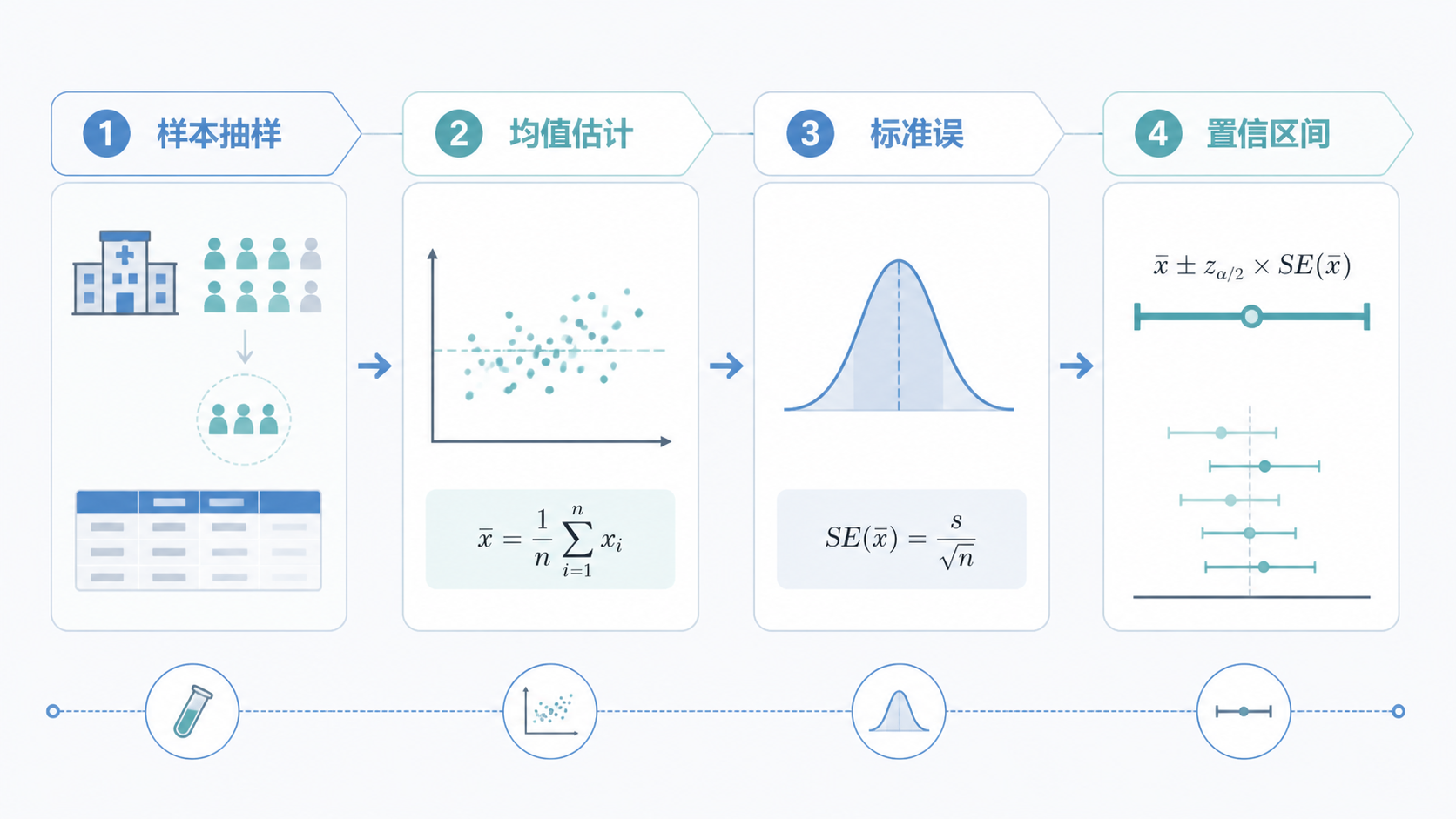
标准误就是用来衡量这个估计有多不稳定。
它越小,说明不同样本算出来的均值越接近,推断越稳。
2.2 它和总体推断直接相关
标准误的本质,是帮助我们从样本走向总体。
这也是它在统计推断中的核心地位。
在回归分析、均值比较、置信区间计算中,标准误都很重要。
因为它直接参与了参数估计的精确度评估。
2.3 一个直观理解
可以把它理解成“均值的波动范围”。
如果你今天抽100个样本,算出一个均值。
明天再抽100个样本,均值可能略有变化。
后天再抽一次,结果还会变。
这些均值之间的波动程度,就是标准误想表达的内容。
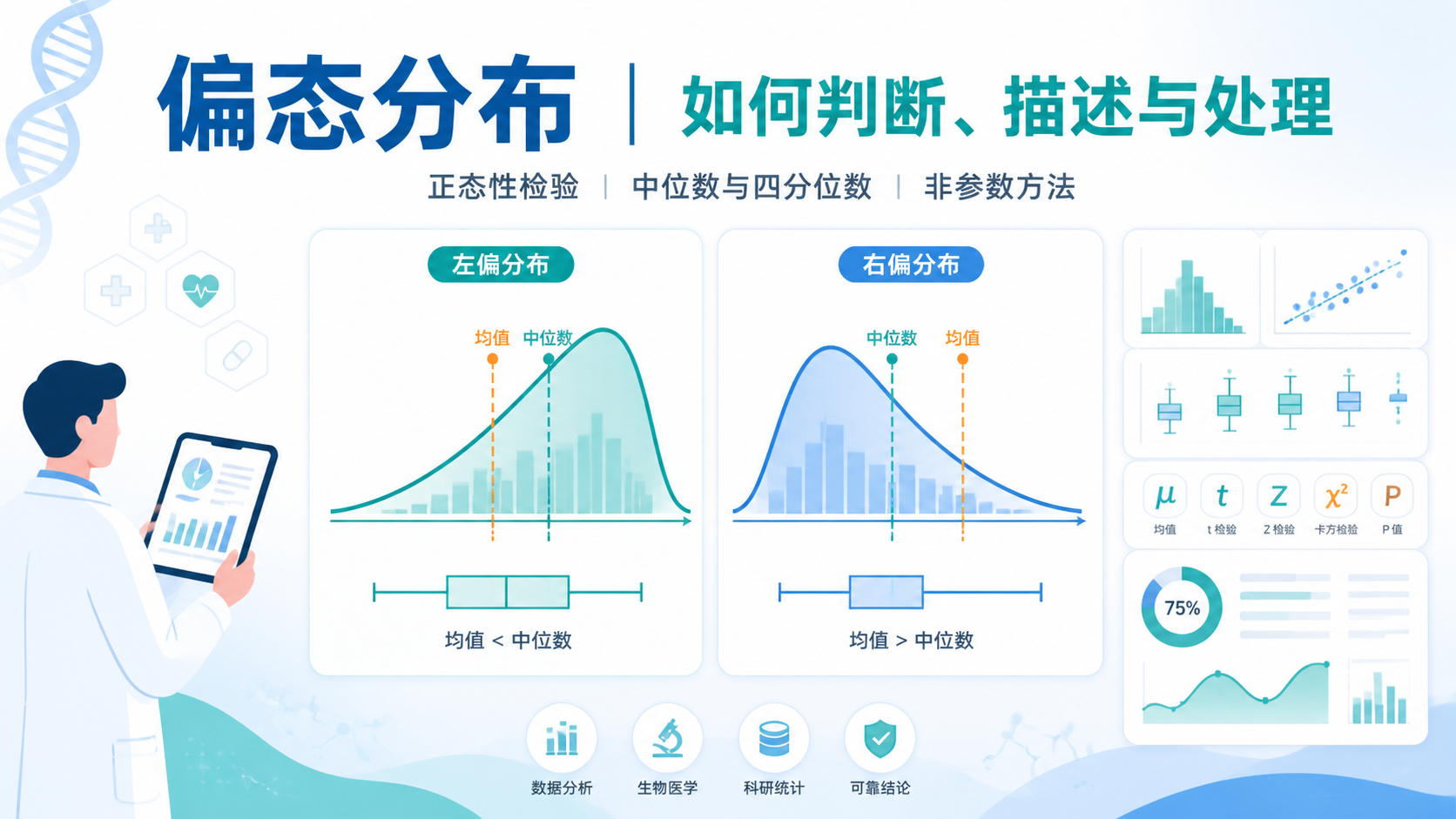
3. 正态分布连续变量为什么常用它
3.1 正态分布数据常见的描述方式
对于正态分布的连续资料,最常见的描述是:
均值 ± 标准差。
原因很简单。
正态分布数据集中在均值附近,均值能代表集中趋势,标准差能代表离散程度。
3.2 标准误不能替代标准差
这是一条非常重要的原则。
标准误不等于标准差,不能直接拿来替代数据描述。
如果你要描述样本特征,用标准差更合适。
如果你要说明均值估计精度,用标准误才更合适。
很多文章为了让图更“好看”,会用标准误画误差线。
但从统计描述角度看,这不代表数据离散程度更小,只是误差线更短而已。
3.3 标准误越小意味着什么
标准误越小,说明样本均值对总体均值的估计越稳定。
常见原因有两个:
- 样本量更大。
- 数据本身波动更小。
所以在同样的标准差下,样本量越大,标准误越小。
这也是为什么扩大样本量,往往能提高研究结果的稳定性。
4. 文献里怎么看标准误
4.1 先看作者报告的是什么
读论文时,先看表格和图注。
很多时候作者会写清楚是 SD 还是 SE。
如果只写“mean ± error”,就要格外谨慎。
因为你必须判断这是不是标准误,而不是标准差。
4.2 判断时要结合研究目的
如果是横断面调查、临床基线特征、样本描述,通常更关注标准差。
如果是模型估计、回归系数、均值置信区间,更常见标准误。
不要看到误差线就默认是标准差。
也不要把标准误误读成数据波动大小。
4.3 写作时要保持规范
在方法学部分,建议明确写出:
- 描述性统计采用均值±标准差,或中位数和四分位数。
- 推断统计报告估计值、标准误和95%置信区间。
- 图中误差线代表标准差还是标准误,要写清楚。
这会显著提升论文的规范性和可重复性。
5. 标准误在SPSS和科研写作中的实际意义
5.1 在软件里它很容易算
标准误不需要手工推导。
常规统计软件都可以自动输出。
但科研人员必须知道它“为什么存在”,而不只是会点菜单。
因为只有理解概念,才知道什么时候该用,什么时候不该用。
5.2 在结果解释中常见的误区
常见误区包括:
- 把标准误当成“数据更集中”。
- 把标准误误当成“个体差异更小”。
- 把标准误误用于描述原始数据分布。
正确做法是区分“描述数据”和“推断总体”。
这是统计学里最基础,也最容易被忽视的一步。
5.3 临床研究中的一句话总结
如果你写的是样本特征,优先关注标准差。
如果你写的是估计精度,标准误才是重点。
这一区分看似简单,但会直接影响论文表述、图表解读和结果判断。
总结Conclusion
标准误的核心,是衡量样本统计量的抽样误差。
它和标准差不同,不能混用。
在临床研究中,标准误更适合用于统计推断,而不是替代样本描述。
如果你想系统掌握这类统计概念,避免在论文阅读和写作中踩坑,可以借助解螺旋 的临床研究课程和工具体系,快速建立从数据描述到统计推断的完整思维。
- 引言Introduction
- 1. 先分清:标准误不是标准差
- 2. 标准误到底是什么
- 3. 正态分布连续变量为什么常用它
- 4. 文献里怎么看标准误
- 5. 标准误在SPSS和科研写作中的实际意义
- 总结Conclusion