引言Introduction
偏态分布是临床研究里最容易被误判的数据类型之一。很多医学生和科研人员拿到连续变量后,第一反应是“先做t检验”,但如果数据不是正态分布,统计结论可能会偏差 。本文用5个关键点讲清偏态分布,帮助你快速判断、正确描述、避免选错方法。
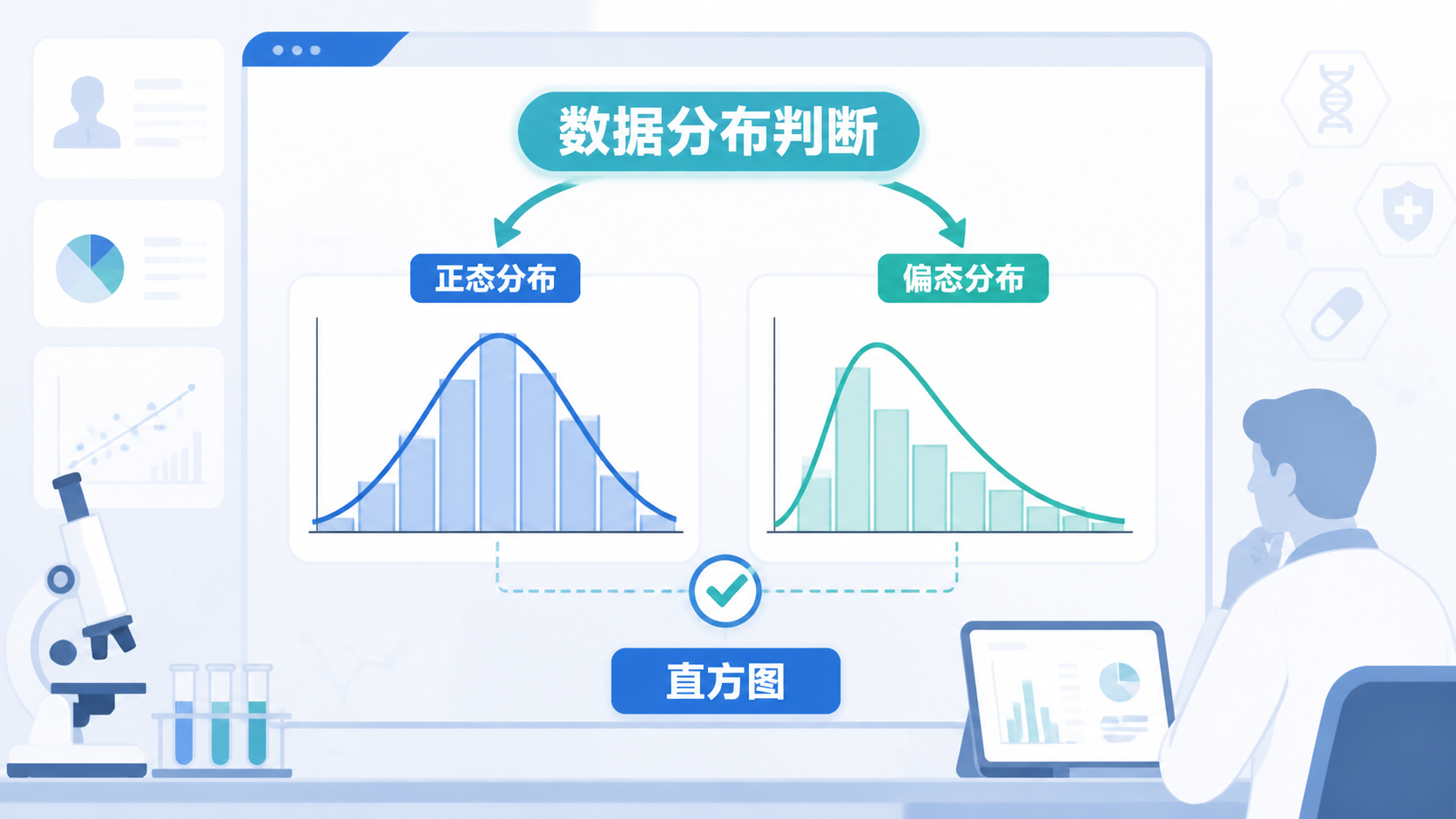
1. 偏态分布是什么
1.1 先理解正态分布,再看偏态分布
正态分布是经典的钟形曲线。它中间高、两边低,左右对称 。均值决定位置,方差决定离散程度。临床连续变量如果接近正态分布,常用均数和标准差描述。
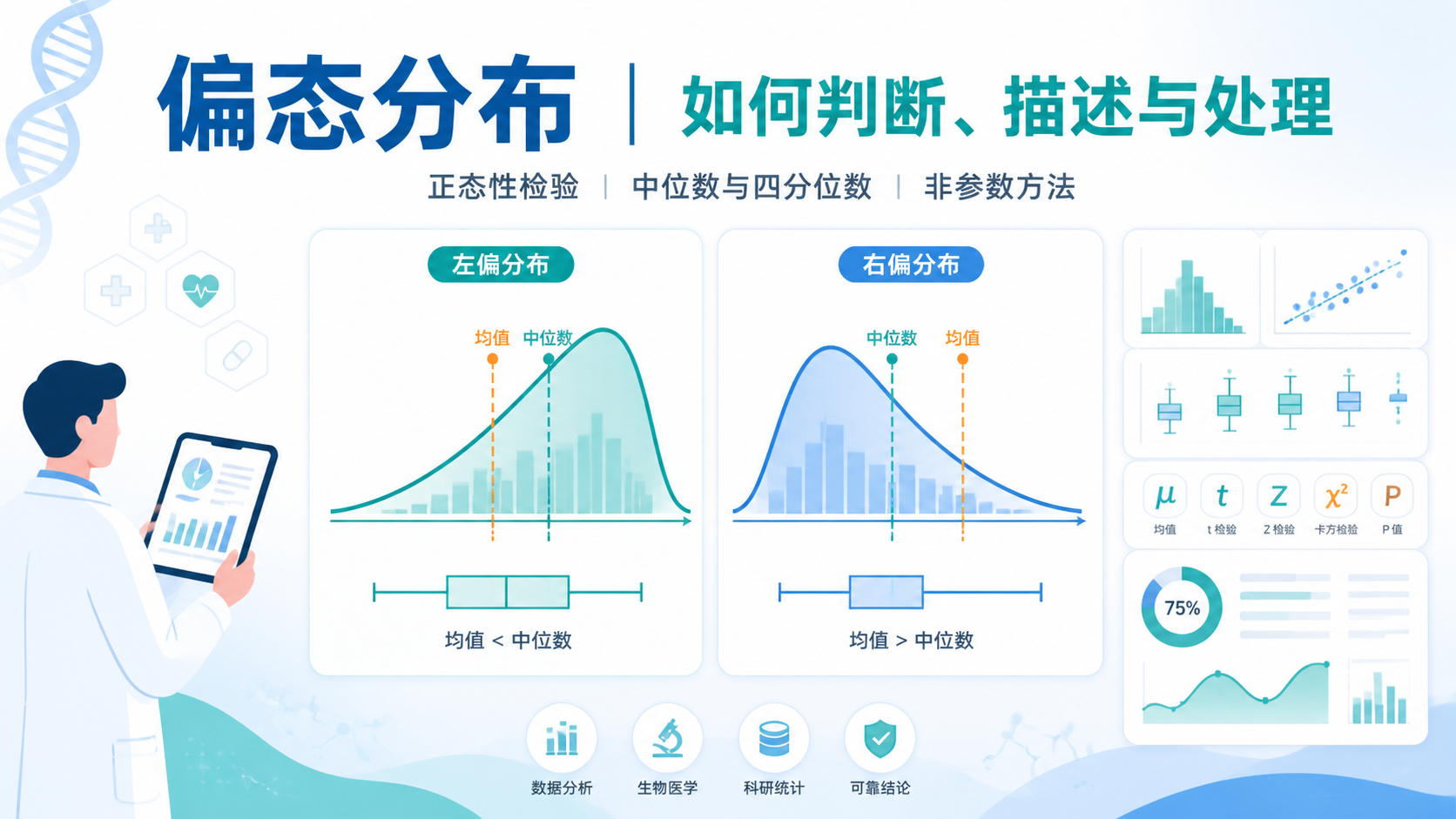
与之相对,偏态分布是指数据分布不再左右对称 。它的一侧尾部更长,数据会向某一方向拉伸。也就是说,数据并没有围绕均值“均匀展开”,而是明显偏向一边。
在临床数据中,偏态分布很常见。比如等待时间、住院天数、某些生化指标、费用数据,往往都不是标准的钟形分布。只要数据被少数极端值拉长尾部,就要警惕偏态分布。
1.2 偏态分布的两个方向
偏态分布通常分为两类。
- 正偏态分布 :右侧尾部长。大多数数据集中在左侧,少数较大值把曲线向右拉长。
- 负偏态分布 :左侧尾部长。大多数数据集中在右侧,少数较小值把曲线向左拉长。
判断方向时,不要只看“最高点在左还是右”。更重要的是看尾巴拉向哪边 。这比看均值更可靠,因为均值容易被极端值影响。
2. 偏态分布为什么重要
2.1 它会影响统计描述
偏态分布最直接的影响,是统计描述方式要变。如果数据明显偏态,单纯用均数±标准差,往往不能真实反映中心位置和离散程度。
原因很简单。均值会被极端值拖动。比如一组住院天数中,大部分患者住院3到5天,但少数患者住院20天以上,均值就会被明显拉高。此时中位数更能代表“典型水平”。
因此,临床研究里常见的原则是:
- 正态分布:均数±标准差。
- 偏态分布:中位数和四分位数间距。
这是数据描述的基础,也是后续统计分析的前提。
2.2 它会影响统计检验
偏态分布还会影响方法选择。很多参数检验都有分布前提。比如t检验、方差分析等,通常要求数据来自正态或近似正态总体。
如果数据明显偏态,却直接套用参数检验,可能出现两类问题:
- P值不可靠。
- 组间差异被高估或低估。
所以在做分析前,必须先判断分布。偏态分布不是“麻烦变量”,而是提醒你换一种更合适的方法。
3. 怎么判断偏态分布
3.1 先看图,再看检验
判断偏态分布,建议按“先图示,后检验”的顺序。
常用图示法包括:
- 直方图。
- Q-Q图。
- P-P图。
- 茎叶图。
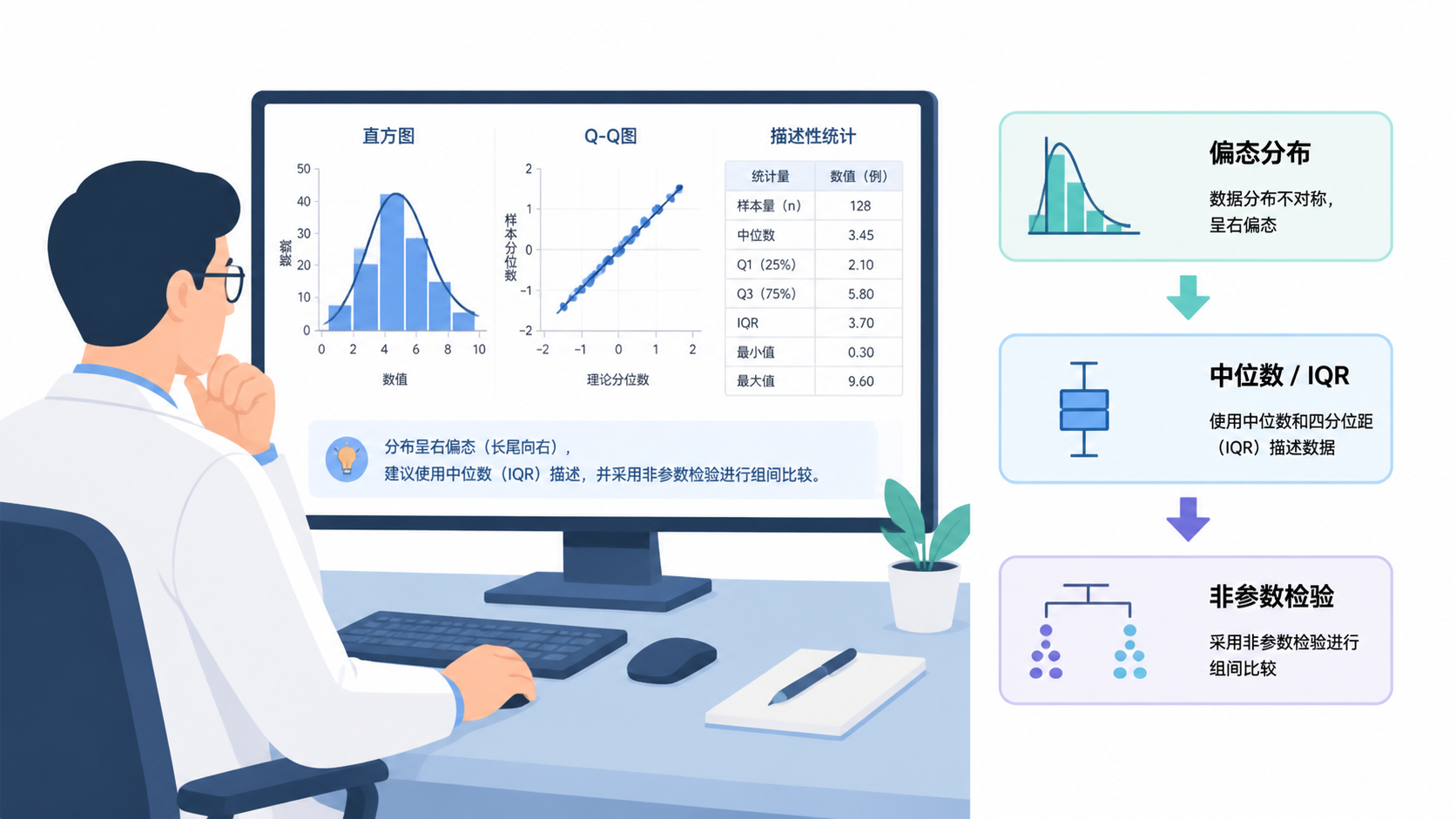
其中,直方图最直观。若图形呈现中间高、两边低的钟形 ,通常可考虑近似正态。若一侧尾巴明显更长,则提示偏态分布。
Q-Q图和P-P图也很有价值。若散点明显偏离对角线,就说明数据与正态分布不一致。对样本量较大时,图示法往往比单纯依赖P值更实用。
3.2 再做正态性检验
常用的正态性检验包括:
- Shapiro-Wilk检验,适用于样本量较小的情况,SPSS中一般为样本量≤5000。
- Kolmogorov-Smirnov检验,适用于样本量较大的情况,SPSS中一般为样本量>5000。
判断逻辑很直接。当P>0.05时,不拒绝“数据来自正态总体”的原假设,可认为近似正态。
当P<0.05时,提示数据与正态分布存在显著差异,需要重点考虑偏态分布。
但要注意,样本量大时,检验很敏感,容易把轻微偏离也判成不正态。此时不能只盯着P值,还要结合图形和临床背景一起判断。
3.3 不要误解“样本量大于30”
教材里常说“样本量大于30时,一般满足正态分布”,这句话容易被误解。严格来说,它更多是在说中心极限定理开始发挥作用,样本均值的分布趋近正态 ,并不等于原始数据本身就是正态分布。
所以,样本量大,不代表可以忽略偏态分布。
这点在临床研究里很重要。
4. 偏态分布该怎么描述
4.1 用中位数和四分位数
偏态分布最常见的描述方式是:
- 中位数。
- 四分位数间距。
- 或者中位数(P25,P75)。
这套写法比均数±标准差更稳健。因为中位数受极端值影响小,能更好反映数据的中心趋势。
例如,当住院天数呈明显右偏时,用“中位数7天,四分位数间距5到10天”比“均数9.8±6.4天”更符合数据实际。
4.2 报告时要和分布对应
写论文时,数据描述必须和分布一致。不要同一变量前面说“偏态分布”,后面又写“均数±标准差”。这会让审稿人直接怀疑统计基础不牢。
建议形成固定思路:
- 先判断分布。
- 再选描述指标。
- 最后决定统计检验方法。
这是临床统计写作的标准流程。
5. 偏态分布如何处理
5.1 优先考虑非参数方法
如果变量呈偏态分布,常用非参数检验替代参数检验。比如:
- 两组独立样本比较,可考虑 Mann-Whitney U 检验。
- 配对资料比较,可考虑 Wilcoxon符号秩检验。
- 多组比较,可考虑 Kruskal-Wallis检验。
这些方法对分布要求更低,更适合偏态数据。它们关注秩次而非原始值,因此对极端值更稳健。
5.2 也可以考虑转换数据
在某些研究中,偏态分布变量还可以尝试数据转换,比如对数转换、平方根转换等。转换后如果接近正态,就可以重新评估是否适合参数分析。
但转换不是万能的。是否转换,要看变量意义、可解释性和研究目的。
如果转换后难以回到临床解释层面,非参数方法往往更直接。
5.3 真实案例思路
以临床常见数据为例,血清指标、炎症因子、住院费用、时间变量,常常存在长尾。此时不应默认它们满足正态分布。正确做法是先画直方图,再做SW检验,最后结合Q-Q图判断。
如果结果提示偏态分布,就用中位数和四分位数描述,并选择合适的非参数检验。这比“先上t检验,出问题再补解释”更科学,也更符合E-E-A-T要求。
总结Conclusion
偏态分布并不罕见,反而是临床数据中的常见状态。你只要记住5点,就能大幅降低统计错误:
- 偏态分布是不对称分布。
- 正偏态和负偏态,关键看尾部方向。
- 先看直方图、Q-Q图,再做正态性检验。
- 偏态数据优先用中位数和四分位数描述。
- 分析时优先考虑非参数检验或合理转换。
如果你正在做临床研究、论文写作或统计分析,建议把“先判断分布”作为固定流程。这样能避免方法选错,也能让结果更可信。想进一步提升数据清洗、统计描述和论文写作效率,可以关注解螺旋品牌 ,把复杂的统计判断变成更标准、更高效的研究流程。
- 引言Introduction
- 1. 偏态分布是什么
- 2. 偏态分布为什么重要
- 3. 怎么判断偏态分布
- 4. 偏态分布该怎么描述
- 5. 偏态分布如何处理
- 总结Conclusion