引言Introduction
置信区间怎么解读 ,是医学生、医生和科研人员在论文阅读与课题设计中最常遇到的统计问题之一。很多人会看P值,却忽略区间宽窄、是否跨越临界值,以及它真正表达的“不确定性”。
1. 先弄清:置信区间到底在回答什么问题
1.1 置信区间不是“结果对不对”
置信区间的核心作用,是描述估计值的不确定范围。
它不是在回答“这个结果是否成立”,而是在回答“如果重复抽样,真实值大致会落在哪个区间”。
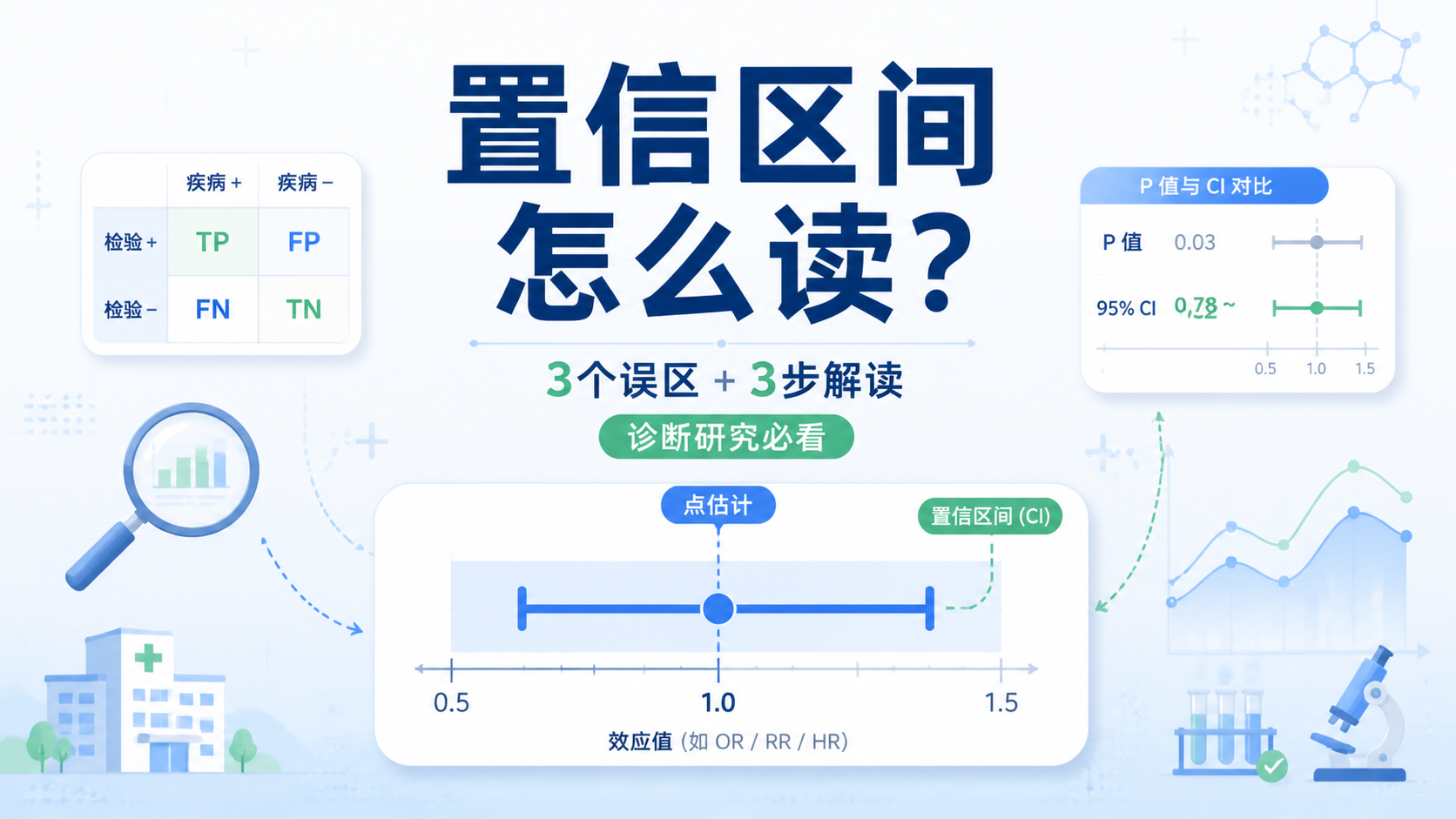
在诊断试验中,灵敏度、特异度、阳性预测值和阴性预测值都可以给出置信区间。比如灵敏度为0.80,95%置信区间为0.72到0.88,这说明点估计周围存在波动范围。它比单独报告一个百分比更完整。
1.2 它和P值不是一回事
很多人把置信区间 和P值混为一谈。其实两者回答的问题不同。
- P值 更偏向“是否有统计学差异”
- 置信区间 更偏向“效应有多大,范围有多宽”
如果一个区间很窄,说明估计更稳定。
如果一个区间很宽,说明样本量可能不足,或数据波动较大。
这也是为什么英文文献常要求同时报告点估计和置信区间。
1.3 诊断研究里最常见的应用
在诊断试验中,置信区间 常用于评价:
- 灵敏度
- 特异度
- 阳性预测值
- 阴性预测值
在四格表数据中,点估计容易算,但区间更能体现研究质量。临床研究中,读者往往先看指标,再看区间是否足够稳定。
2. 3个最常见的解读误区
2.1 误区一:把95%置信区间理解成“真实值有95%概率落在这里”
这是最常见的错误。严格来说,95%置信区间不是在说单次计算后真实参数有95%的概率落在区间内 。
更准确的理解是:在相同方法下反复抽样并构建区间,约95%的区间会覆盖真实值。
这个差别很重要。
前者是“概率解释”,后者是“长期频率解释”。
在论文写作和答辩中,这个表述差异经常决定专业度。
2.2 误区二:区间跨不跨1,和所有指标都一样
很多人看到比值类指标会习惯性判断“是否跨1”。但这不是所有情形都适用。
- 对比值比、风险比、优势比 ,通常看是否跨1
- 对比例类指标 ,如灵敏度、特异度,通常看是否跨越临床关注的阈值
- 对差值类指标 ,常常看是否跨0
所以,置信区间怎么解读,必须先明确指标类型 。
不能拿一种规则套所有统计量。
2.3 误区三:区间越窄,结果就一定越“好”
区间窄,通常说明估计更精确。
但这不等于结果更有临床价值。
例如,一个灵敏度很高但特异度较低的检测方法,区间再窄,也只能说明“估计稳定”,不能自动证明“适合临床使用”。真正的解读还要结合:
- 疾病流行情况
- 金标准是否可靠
- 样本是否代表目标人群
- 诊断阈值是否合理
置信区间是证据的一部分,不是结论本身。
3. 读懂置信区间的3个专业步骤
3.1 第一步,先看点估计
点估计是研究结果的中心值。
在诊断研究中,它告诉你模型或方法的“平均表现”。
例如:
- 灵敏度0.80
- 特异度0.90
- 阳性预测值0.89
- 阴性预测值0.82
这些数字先给出直观印象。
但没有区间,就不知道这些结果稳不稳。
3.2 第二步,看区间宽窄
区间宽,常提示样本量不足或事件数太少。
区间窄,通常提示估计更稳定。
举例说,灵敏度0.80,95%置信区间0.72到0.88,比0.80,95%置信区间0.50到0.95更可信。因为前者波动更小,后者不确定性更大。
在诊断试验中,区间宽窄常受以下因素影响:
- 样本量
- 阳性和阴性例数是否均衡
- 数据是否集中
- 测试方法稳定性
3.3 第三步,看临床意义
统计显著不等于临床有用。
最终要看区间是否落在临床可接受范围内。
比如某项筛查工具的最低可接受灵敏度是0.85。
如果研究结果是0.88,95%置信区间0.84到0.92,那么它虽然点估计达标,但下限低于0.85,临床上仍需谨慎。
这就是专业阅读中最重要的一步。
不是只看中位数或点估计,而是看区间是否支持决策。
4. 诊断研究中如何报告才更规范
4.1 建议同时给出点估计和置信区间
在临床研究写作中,单独报告“灵敏度80%”是不够的。
更规范的写法是:
- 灵敏度0.80,95%置信区间0.72到0.88
- 特异度0.90,95%置信区间0.81到0.94
这样可以让读者同时看到结果和不确定性。
也更符合国际期刊的写作习惯。
4.2 四格表是基础,但不是终点
对于诊断试验,四格表可以计算出常见指标。
但如果要做论文,通常还要关注:
- 是否报告置信区间
- 是否说明金标准
- 是否说明样本来源
- 是否考虑阈值选择偏倚
没有区间的四格表,只能算“结果摘要”。
加上置信区间,才更接近可发表的研究表达。
4.3 软件计算更适合科研场景
手工公式可以帮助理解原理,但科研工作中,使用统计软件或专业计算工具更高效。
尤其当要同时计算灵敏度、特异度、阳性预测值、阴性预测值及其区间时,软件能减少计算错误。
对医学生和研究者而言,关键不是死记公式,而是理解:
- 点估计是什么
- 区间代表什么
- 如何结合临床阈值做判断
5. 3个误区背后的共同问题
5.1 只看结果,不看不确定性
很多论文阅读停留在“数值是多少”。
但科研评价更重要的是“这个数值稳不稳”。
置信区间的价值,就在于把不确定性显性化。
这也是它比单个百分比更有信息量的原因。
5.2 只会解释统计,不会回到临床
统计解释如果脱离临床场景,就会失真。
比如同样的灵敏度,在筛查和确诊场景中的意义完全不同。
因此,解读时必须回到研究目的:
- 是早筛,还是确诊
- 是高敏感优先,还是高特异优先
- 是群体筛查,还是个体诊断
5.3 只关注显著性,忽略效应大小
很多初学者习惯先问“显著吗”。
但科研真正重要的是效应大小和可信度。
置信区间正是连接“效果大小”与“证据强度”的关键工具。
这是临床研究中最值得训练的统计素养之一。
总结Conclusion
置信区间怎么解读,关键不在记公式,而在理解它表达的不确定性、稳定性和临床意义。
最常见的3个误区分别是,把它当成概率区间、把所有指标都套同一判断规则、以及误以为区间越窄就一定越有临床价值。
对医学生、医生和科研人员来说,真正专业的读法是:先看点估计,再看区间宽窄,最后回到临床阈值和研究场景。这样才能把统计结果转化为可用证据。
如果你在诊断试验、临床课题或论文写作中,常常卡在置信区间 解读和结果呈现,不妨借助解螺旋的科研与写作支持工具,把统计表达、论文结构和结果报告做得更规范、更高效。

- 引言Introduction
- 1. 先弄清:置信区间到底在回答什么问题
- 2. 3个最常见的解读误区
- 3. 读懂置信区间的3个专业步骤
- 4. 诊断研究中如何报告才更规范
- 5. 3个误区背后的共同问题
- 总结Conclusion