引言Introduction
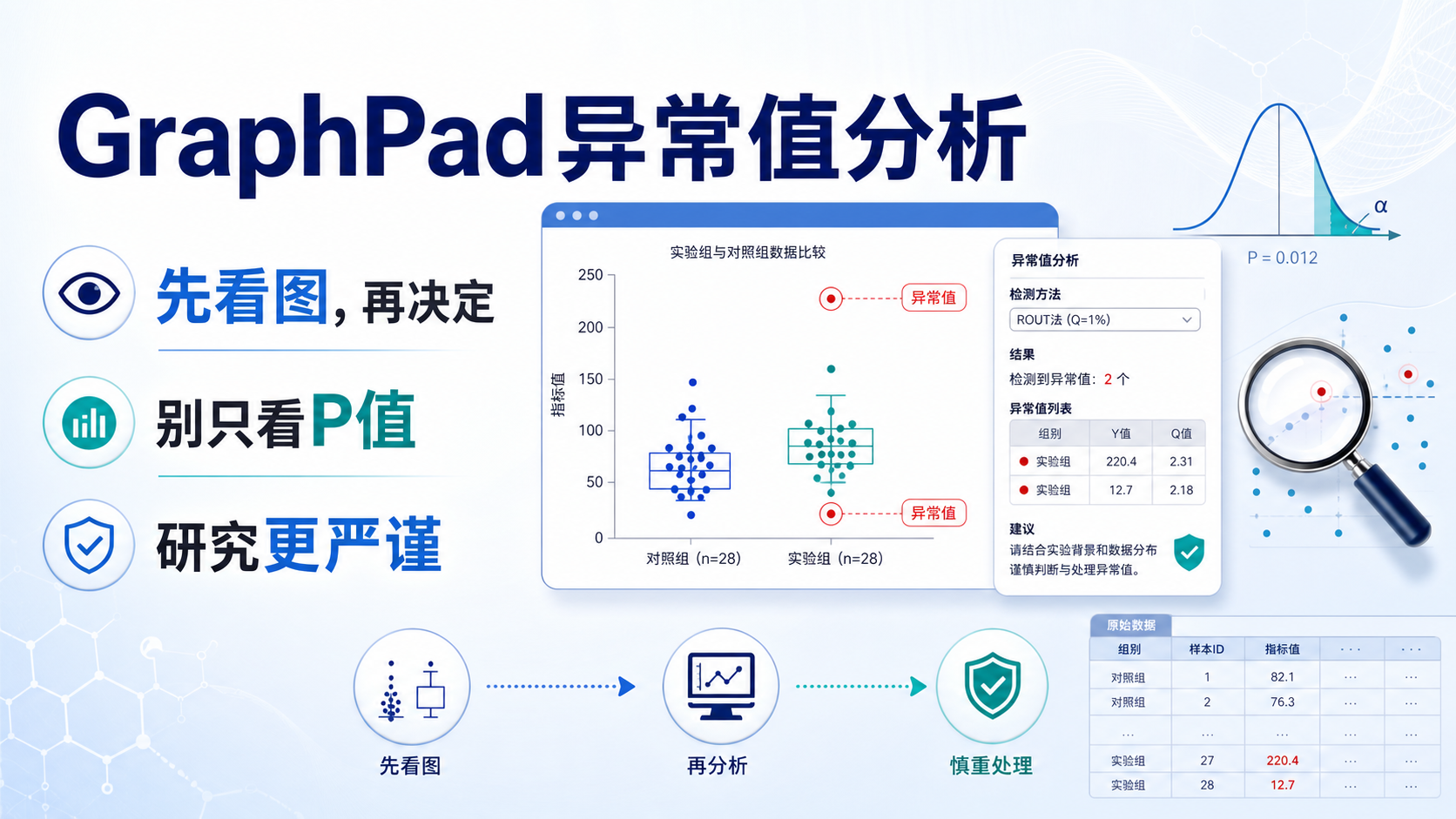
异常值会直接影响均值、回归和生存分析结果。对医学生、医生和科研人员来说,异常值 SPSS 处理 不是简单删数,而是先识别、再判断、再决定如何处理。下面用SPSS里最常见的4步方法,讲清楚怎么做更稳妥。
1. 先判断异常值类型,再决定方法
1.1 分类变量,先看频数分布
异常值 SPSS 处理的第一步,是先分清变量类型。
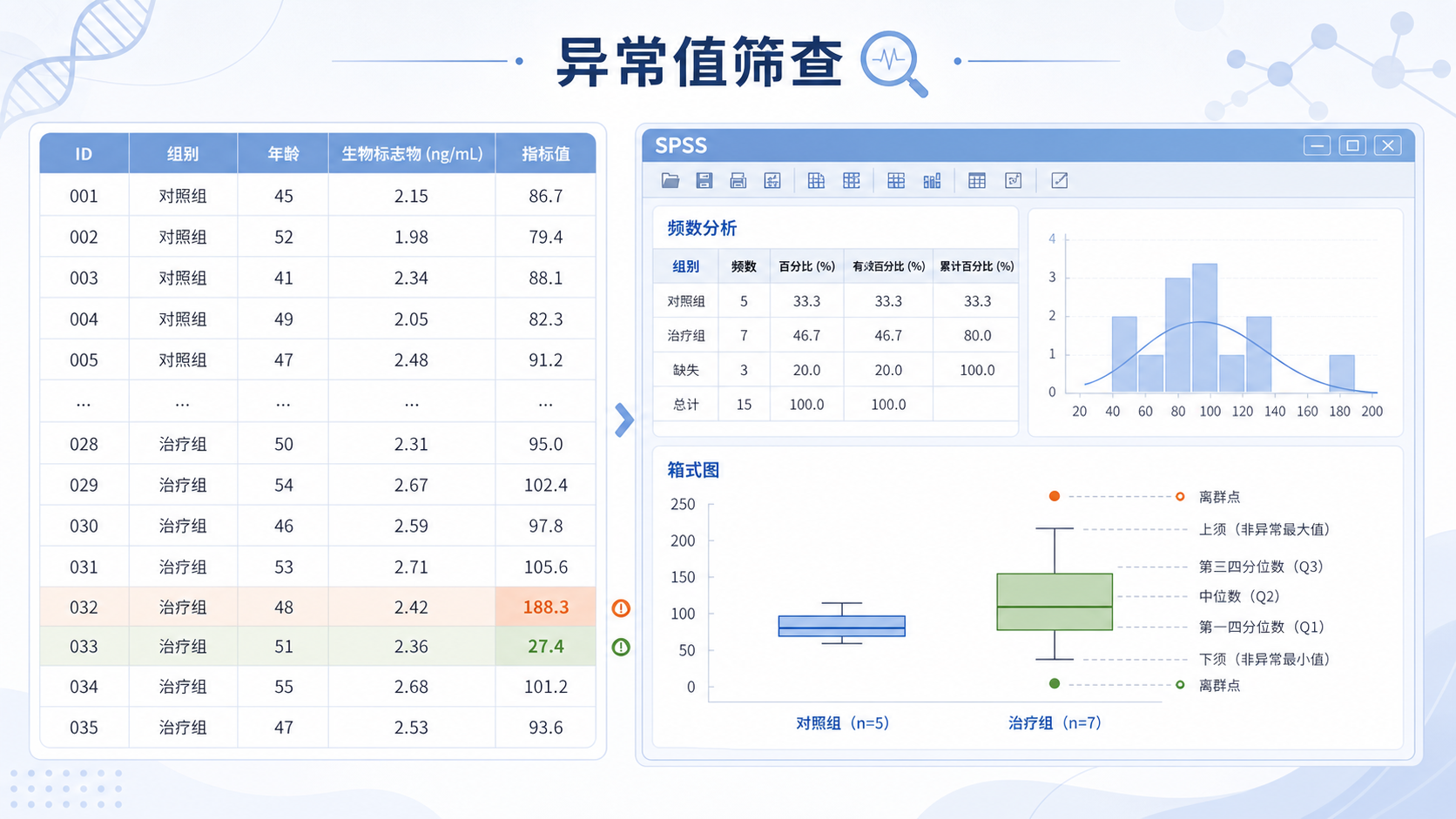
分类变量的异常值,常常是逻辑错误。比如性别编码只定义了1和2,却出现0、1.5或3。肿瘤分级只允许1到4,却录入了5或6。这类问题,频数分析最直接。
在SPSS中,可以通过“分析”→“描述统计”→“频率”查看每个取值。若出现不在定义范围内的数值,就要优先核对原始资料。对于吸烟状态和每日吸烟数量这类变量,还要看逻辑是否一致。比如“不吸烟”却填了具体吸烟支数,就是明显冲突。
这类异常值的核心不是“极端”,而是“矛盾”。
1.2 连续变量,重点看分布和离群点
连续变量的异常值,通常表现为极端大或极端小。比如年龄-5岁,身高1.6却被录成1.6厘米,或者收缩压低于舒张压。
这时不能只靠肉眼,要结合统计分布判断。
SPSS里常用两种办法:
- 箱式图 ,适合快速发现离群点。
- Z转换 ,适合标准化后识别偏离均值过远的数据。
一般来说,Z值绝对值大于2,需重点核查 。如果数据明显不符合临床逻辑,即使Z值没超阈值,也可能是异常。
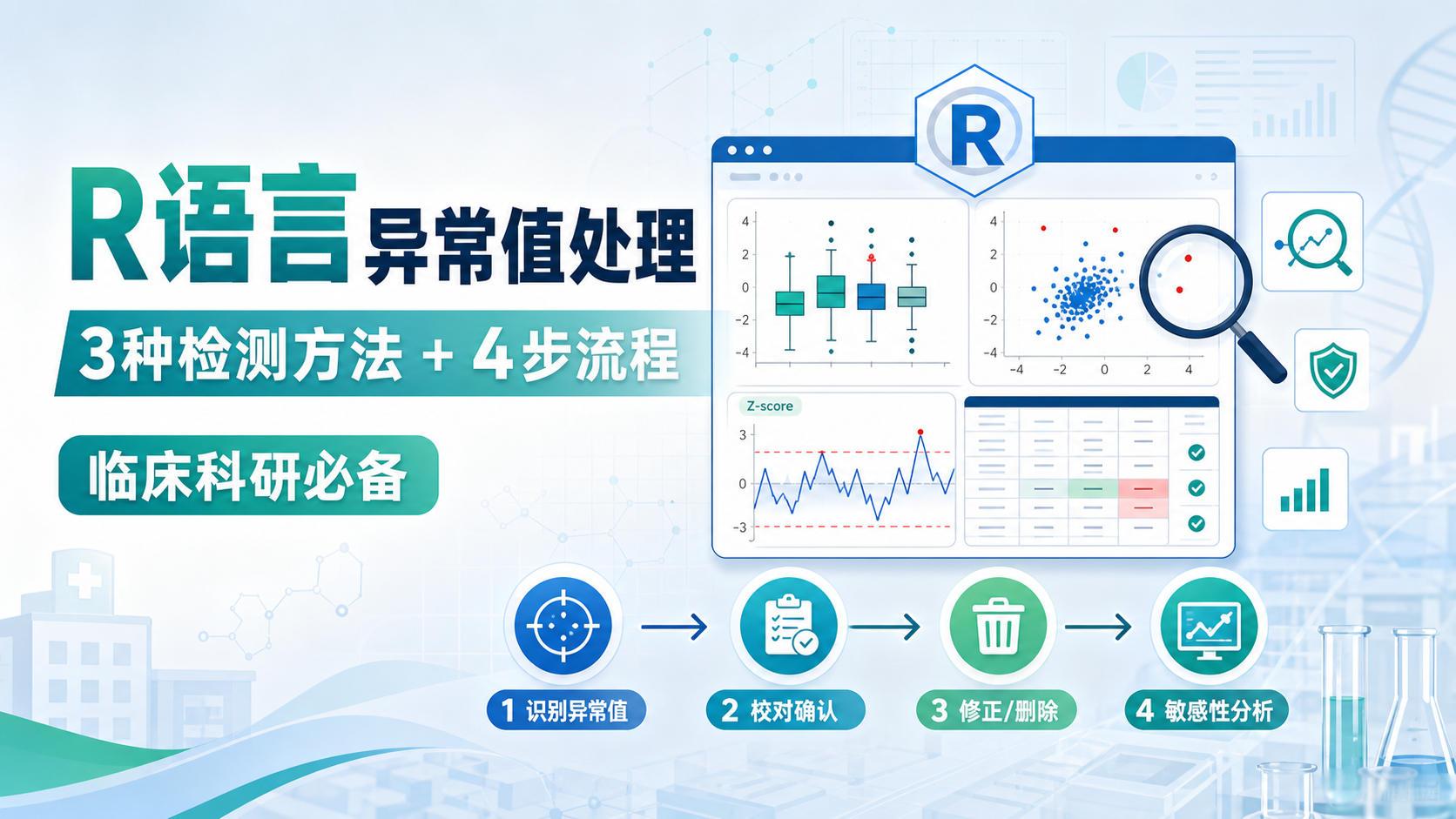
2. 用SPSS快速定位异常值
2.1 频数法找分类变量异常值
在SPSS中,先进入“数据视图”和“变量视图”。
“变量视图”能看到变量定义,比如gender代表性别,1=男性,2=女性。
“数据视图”则是一行一个病例,一列一个变量。
操作路径很简单:
分析 → 描述统计 → 频率 。
把目标分类变量放进分析框,点击确定即可。
输出结果里,如果出现未定义编码,就说明存在异常值。接下来可回到数据视图,结合排序功能快速定位。对于样本量较大时,这一步尤其重要。它能把问题从“疑似存在”变成“具体在哪一行”。
2.2 箱式图找连续变量异常值
连续变量建议用“探索”生成箱式图。
路径是:分析 → 描述统计 → 探索 。
把身高、年龄等变量放入因变量列表,点击确定。
箱式图会显示中位数、四分位数、极值和异常值标记。
超出1.5倍IQR范围的数据,通常要进一步核对。
例如,身高数据中如果出现1.6和1.79,结合临床常识,很可能是单位写错了,应该是160和179。
这类错误在录入过程中很常见。箱式图的价值,不只是找极端值,更是帮助你发现“明显不合理的记录”。
2.3 Z转换找标准化异常值
如果变量接近正态分布,可用Z转换辅助判断。
路径是:分析 → 描述统计 → 描述 ,勾选“将标准化得分另存为变量”。
生成后,数据表会多出一列Z值。
Z值绝对值大于2,通常提示该样本值得重点检查。
这种方法适合年龄、身高、实验室指标等连续变量。
但要注意,Z值是统计学提示,不是最终裁决。最终还要结合临床背景和原始记录。
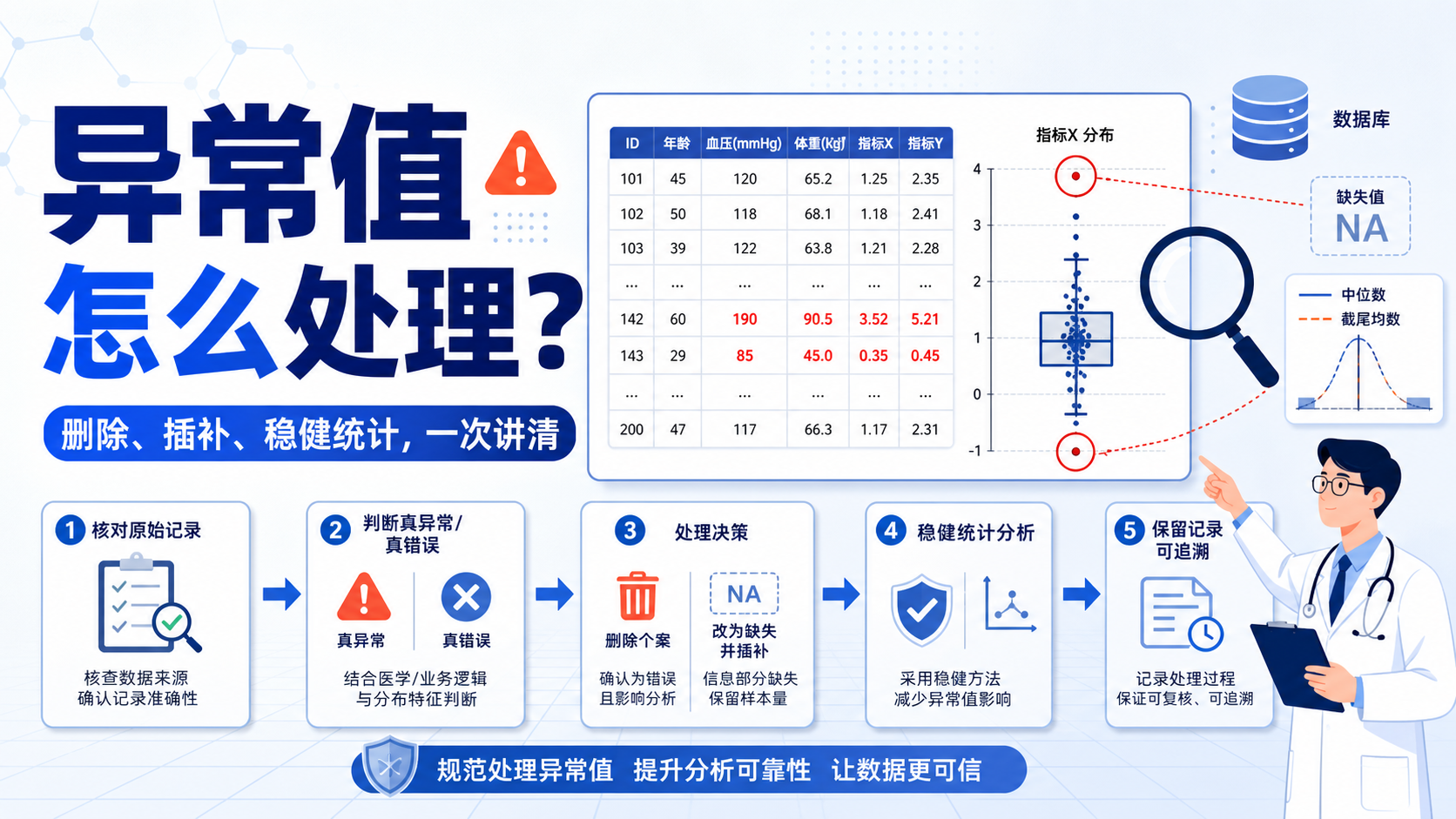
3. 发现异常值后,怎么处理才规范
3.1 优先核对原始资料
异常值 SPSS 处理的标准原则,是先核对,再修改。
如果能找到原始病历、病例报告表或调查对象,应优先确认真实值。
这是最稳妥的做法。
比如年龄录成-15,核对后发现其实是15。
这类问题直接更正即可。
如果是收缩压和舒张压录反,也应在确认后修正原值,而不是简单删除。
3.2 无法核对时,再考虑删除或置缺失
如果原档案无法追溯,处理方式要看变量重要性。
常见做法有三种:
- 删除整个个案 ,适用于关键变量无法判断,且该记录无法可信使用。
- 将异常值改为缺失值 ,适用于只影响某一个变量。
- 保留异常值并标记 ,适用于需要后续敏感性分析的情况。
不是所有异常值都要删。
有些极端值可能代表真实临床现象。比如某些患者的脉压差较大,未必是错误。
所以处理前一定要判断它是“录入错误”还是“真实极端”。
3.3 关键变量异常,要更谨慎
如果异常出现在分组变量或结局变量中,影响会更大。
例如生存结局只有0和1,却录入了3,这时无法判断该病例属于生存还是死亡。
这种情况通常不能继续纳入分析。
一旦关键变量失真,整条记录的可信度就会下降。
这也是临床研究中最需要谨慎处理的部分。
4. 做完异常值SPSS处理后,还要做这两件事
4.1 记录每一步修改
高质量的数据清洗,不只是改对了,还要可追溯。
建议保留一份清洗日志,记录:
- 哪个变量出现异常值
- 异常值是什么
- 采用了什么方法识别
- 最终如何处理
- 是否保留原始值
这样后续写论文方法学部分时,也能清楚说明数据处理流程。
这对提升研究可信度很重要。
4.2 重新检查分析结果是否变化
异常值处理后,建议重新跑一次描述统计和主要模型。
看看均值、标准差、回归系数或P值是否发生明显变化。
如果变化很大,说明异常值对结果影响较强,应在讨论中说明。
异常值 SPSS 处理不是一次性动作,而是一个“识别-核对-修正-复核”的闭环。
总结Conclusion
异常值处理的关键,不在于“发现一个就删一个”,而在于先分清变量类型,再用合适方法识别,再结合临床逻辑判断。对分类变量,先做频数分析。对连续变量,优先用箱式图和Z转换。发现问题后,先核对原始资料,再决定是修正、置缺失、删除还是保留。
如果你希望把这套流程更高效地用在论文、课题和临床数据清洗中,可以进一步了解解螺旋 的临床研究与数据处理支持,帮助你更快完成规范的异常值 SPSS 处理 。

- 引言Introduction
- 1. 先判断异常值类型,再决定方法
- 2. 用SPSS快速定位异常值
- 3. 发现异常值后,怎么处理才规范
- 4. 做完异常值SPSS处理后,还要做这两件事
- 总结Conclusion