引言Introduction
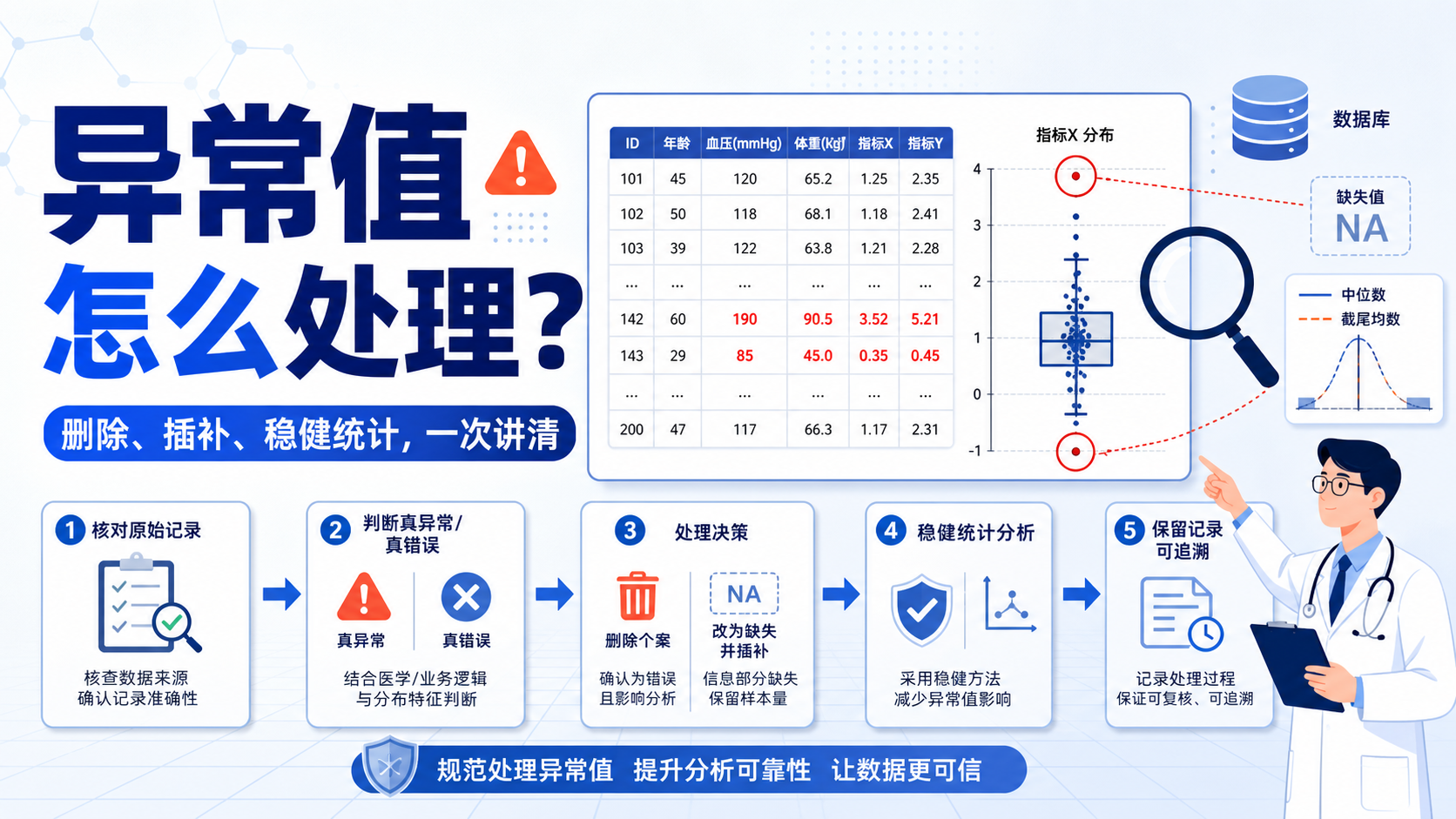
临床数据里,异常值校正方法 选错,往往会直接影响统计结果、结论和发文质量。对医学生、医生和科研人员来说,难点不在“发现异常值”,而在“该修正、删除,还是保留”。
1. 先判断异常值是不是“真错”
1.1 核对原始资料
发现异常值后,第一步不是马上删,而是回查原始档案、病历或问卷。很多问题其实是录入错误、单位写错,或抄录错误。
例如,成年男性身高记录为280cm,明显不合理。若核实后真实值是180cm,这类情况应直接修正。这类异常值校正方法最优先,因为它保留了真实信息。
1.2 适用场景
这一类方法适合:
- 可回溯到原始病历或数据库
- 调查对象可再次联系
- 变量很关键,不能轻易删除
如果能确认真实值,校正优先级高于删除。因为它不会减少样本量,也不会引入不必要的偏倚。
1.3 关键提醒
异常值校正方法的核心原则是先证伪,再处理。
不要把“看起来奇怪”直接等同于“错误”。尤其在临床研究中,极端值有时确实存在,比如重症患者的实验室指标、罕见病表型,不能机械剔除。
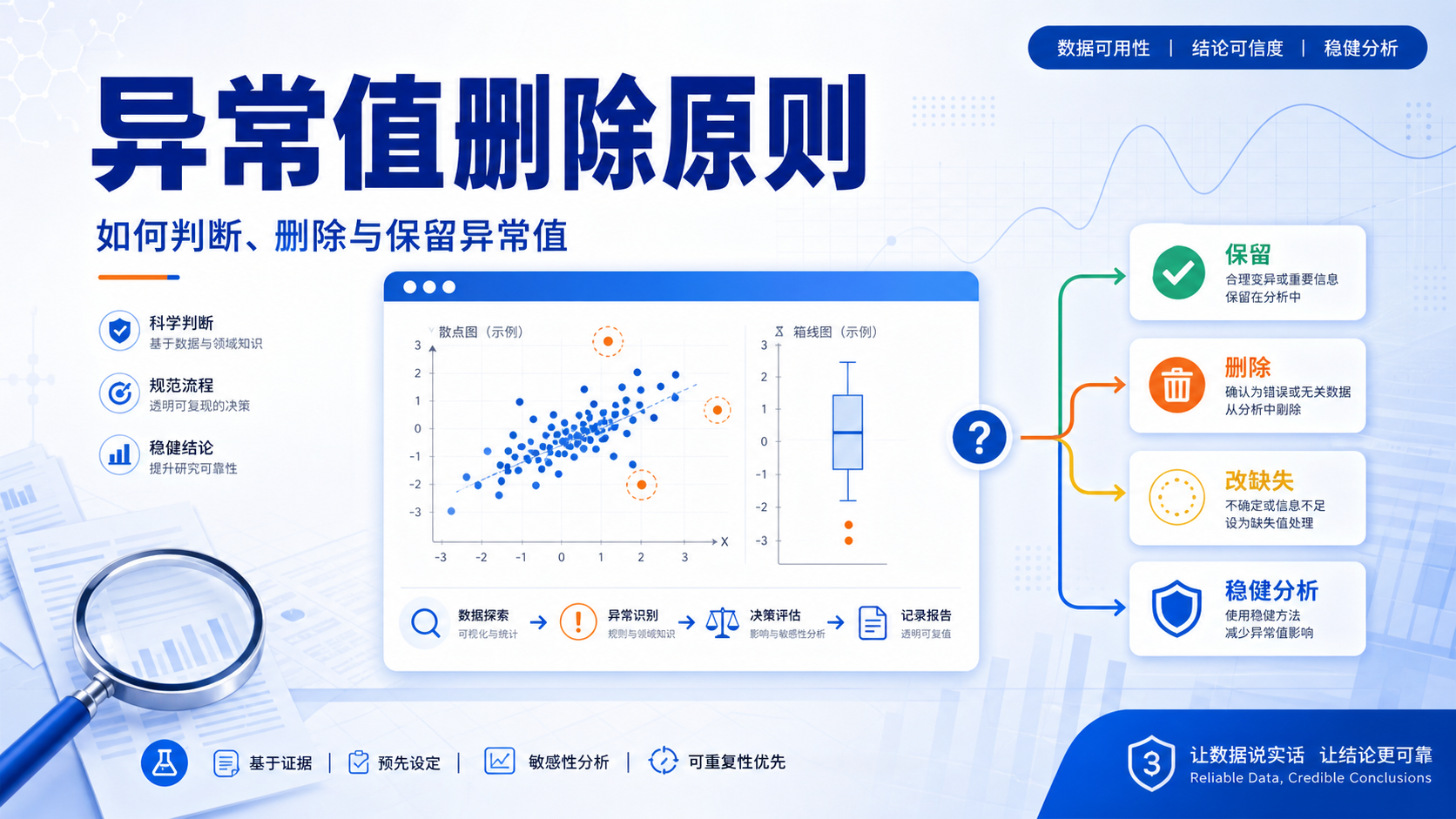
2. 不能核对时,何时删除个案
2.1 适用于明显逻辑错误
如果无法回查原始资料,又能明确判断该值不符合逻辑,且该变量很重要,可以考虑个案删除。知识库中的典型例子是,17岁女生体重记录为5kg,这种值明显不合常识。
这类异常值校正方法适合用于:
- 分组变量异常,导致个案无法分类
- 结局变量异常,影响主要分析
- 明显逻辑冲突,且无法修正
2.2 删除前要评估样本损失
删除个案会直接损失样本量。样本量越小,删除越要谨慎。
一般更适合:
- 样本量较大
- 异常比例较低
- 异常值会明显扭曲结论
如果研究的是暴露因素或结局因素,通常不建议轻易删除。因为这会降低统计效能,甚至改变研究结论。
2.3 先做敏感性分析
如果拿不准是否删除,建议先比较两种结果:
- 保留异常值的分析结果
- 删除异常值后的分析结果
如果结论一致,说明该异常值影响有限。
如果结论相反,就要重新判断删除是否合理。这一步是临床研究中很实用的异常值校正方法。
3. 不删也不改时,如何降低影响
3.1 用稳健统计替代均数
当异常值是真实值,但会明显拉偏均值时,可以改用中位数。中位数对极大值和极小值不敏感,更适合偏态分布数据。
如果变量大于0,还可以考虑对数变换。对数变换后,几何均数能降低极大值的影响。
但要注意,对数变换会夸大极小值影响 ,不能盲目使用。
3.2 使用截尾均数
截尾均数是另一类常见的异常值校正方法。它先把数据排序,再从两端去掉一定比例的数据,最后计算剩余部分的均值。
这类方法适合:
- 需要反映“平均水平”
- 数据中有少量极端值
- 希望减少异常值干扰
常见做法是两端各去掉5%或10%。但目前没有统一标准,不同软件默认设置也不同。因此截尾比例应结合研究目的、样本分布和软件规则来定。
3.3 适用边界
稳健统计的优点是保留样本信息,不因少数极端值而失真。
但它不是“修正原始错误”的方法。也就是说,如果数据是录错的,还是应该先修正,而不是直接用稳健指标掩盖问题。
4. 异常值改成缺失值,何时更合适
4.1 适合逻辑错误但无法精确修复的情况
有些异常值既无法核对,也不适合直接删除。这时可以把异常值改为缺失值,再按缺失值处理思路继续分析。
这类异常值校正方法常用于:
- 数值明显不合理,但无法确认真实值
- 该变量不能保留错误记录
- 又不想整条记录删除
4.2 后续可接缺失值处理
改为缺失值后,可以再考虑:
- 均值或众数填补
- 回归法
- 多重填补法
- 虚拟变量法
这些方法更适合后续系统处理缺失,而不是直接用来“纠正”异常值本身。
所以,先把异常值规范地转成缺失值,是很多研究中更稳妥的异常值校正方法。
4.3 什么时候不要这么做
如果异常值本身是关键结局或关键暴露信息,且其真实值尚不明确,简单改成缺失值可能会改变样本结构。此时仍应优先核对,再决定下一步。
5. 保留异常值,只做标记
5.1 适合真实极端值
有些异常值通过核实后发现是真实存在的,只是偏离总体分布。比如罕见但合理的极端实验室数值,或重症患者的特殊表现。
这时可以保留,不作处理,只做标记。
不处理本身也是一种处理方式。
5.2 适合做稳健性检验
保留异常值后,在分析中要评估它是否会影响结果。
常用做法包括:
- 描述时同时看均数和中位数
- 建模时检查残差和影响点
- 做敏感性分析,比较有无该值时的结果
这种异常值校正方法的本质,是尊重真实数据,同时控制统计偏倚。
5.3 适用前提
前提是你已经判断它不是录入错误,也不是逻辑错误。
如果只是因为“太极端”就保留,风险很大。必须结合临床背景和统计结果一起判断。
6. 五类场景下怎么选
6.1 能核对原始数据
首选:修正原始记录。
这是最符合数据质量原则的异常值校正方法。
6.2 明显错误且无法核对
可选:删除个案,或改为缺失值。
若变量关键,删除前要做敏感性分析。
6.3 异常值是真实的,但会影响均值
可选:中位数、对数变换、截尾均数。
重点是降低极端值对统计量的拉偏效应。
6.4 异常值无法判断
可选:先保留并标记,再比较不同处理策略下的结果。
这是较稳妥的研究流程。
6.5 变量属于分组变量或结局变量
优先级更高,不能轻率处理。
因为这类错误会直接影响分组、模型和最终结论。
7. 实操建议:先流程化,再个体化
7.1 建议的处理顺序
可以按以下顺序处理异常值:
- 识别异常值
- 核对原始资料
- 判断是否为录入错误
- 决定修正、删除、转缺失、稳健分析或保留
- 做敏感性分析
这个流程能最大程度减少主观性。
7.2 记录处理规则
科研中最怕的是“前后标准不一致”。
建议在数据清洗前就写清楚规则,例如:
- 哪些值视为逻辑错误
- 哪些值允许保留
- 删除阈值是多少
- 是否进行敏感性分析
规则先定,结果才更可信。
7.3 让统计和临床一起判断
临床数据不是纯统计问题。
同一个极端值,统计上可能是异常,临床上却可能是罕见真实事件。
因此,异常值校正方法的选择,最好由临床背景和统计原则共同决定。
总结Conclusion
异常值校正方法没有统一模板,关键是看数据是否可核实、变量是否重要、异常是否真实,以及处理后会不会改变结论。优先核对原始资料,其次再考虑删除、转缺失、稳健统计或保留标记。对医学生、医生和科研人员来说,真正专业的做法不是“快速处理”,而是“有证据地处理”。 如果你希望把异常值处理、缺失值处理和数据清洗流程做得更规范,可以结合解螺旋 的数据科研工具与方法支持,提升研究效率和结果可信度。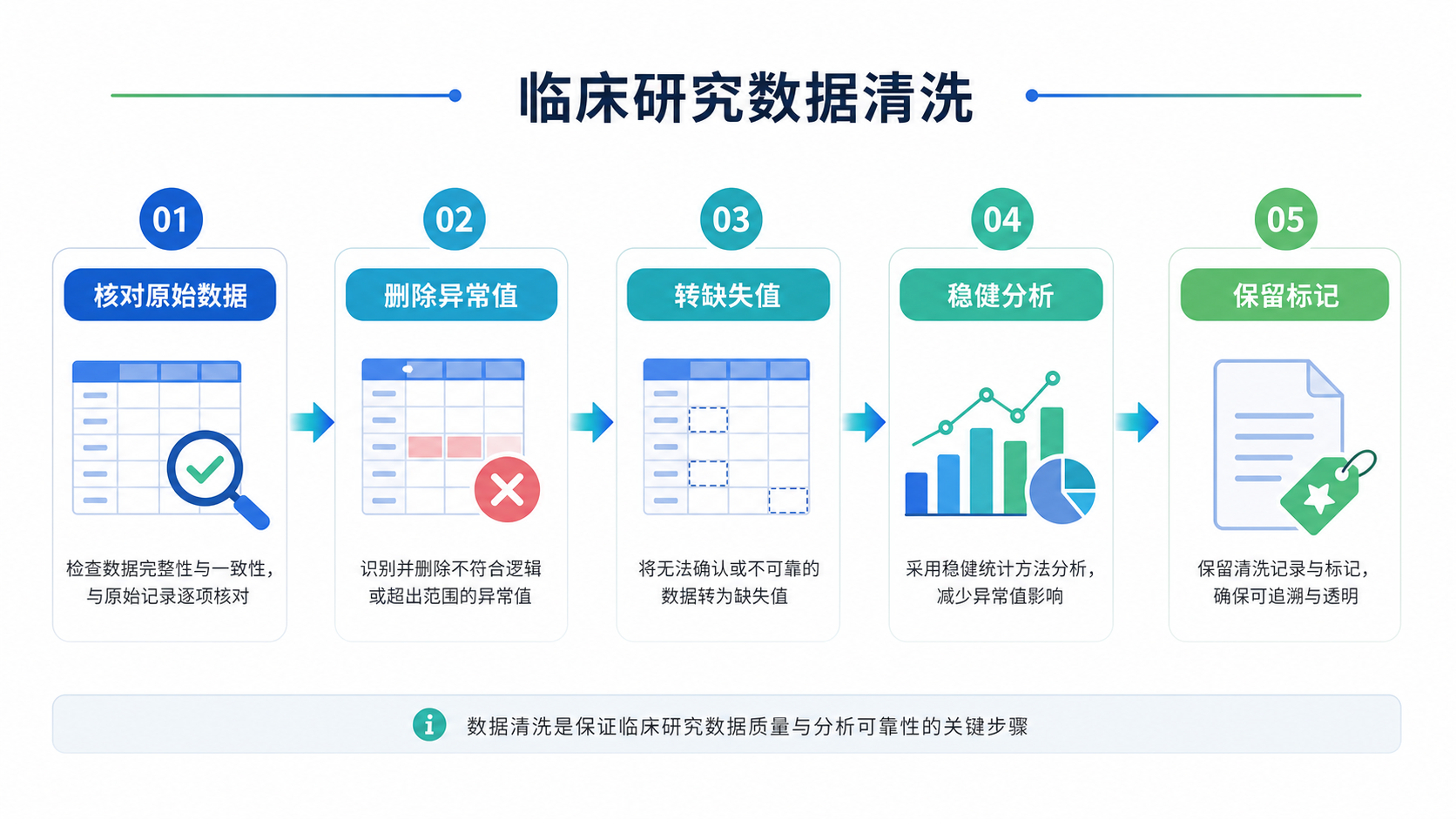
- 引言Introduction
- 1. 先判断异常值是不是“真错”
- 2. 不能核对时,何时删除个案
- 3. 不删也不改时,如何降低影响
- 4. 异常值改成缺失值,何时更合适
- 5. 保留异常值,只做标记
- 6. 五类场景下怎么选
- 7. 实操建议:先流程化,再个体化
- 总结Conclusion