引言Introduction
肿瘤研究中,肿瘤基因数据库在线分析 能快速完成表达、预后和甲基化评估,但很多医学生和科研人员常卡在“选哪个数据库、怎么用、结果怎么解释”。本文整理5种最实用的方法,帮助你少走弯路,直接进入分析。
1. 先明确分析目标,再选数据库
1.1 不同问题,对应不同工具
做肿瘤基因数据库在线分析 ,第一步不是打开网站,而是先想清楚问题类型。你是要看差异表达,还是做生存分析,还是查甲基化调控。目标不同,数据库选择就不同。
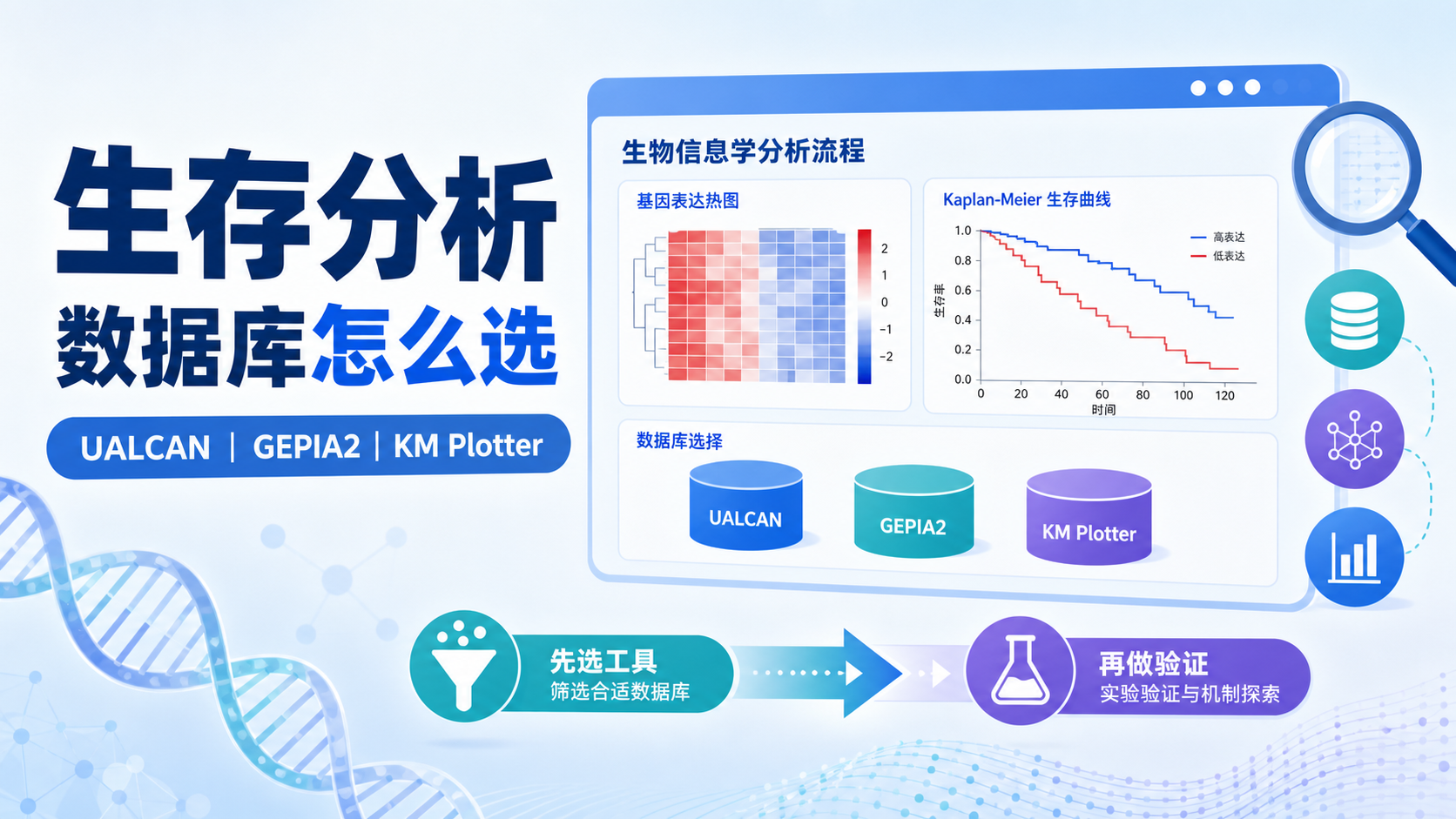
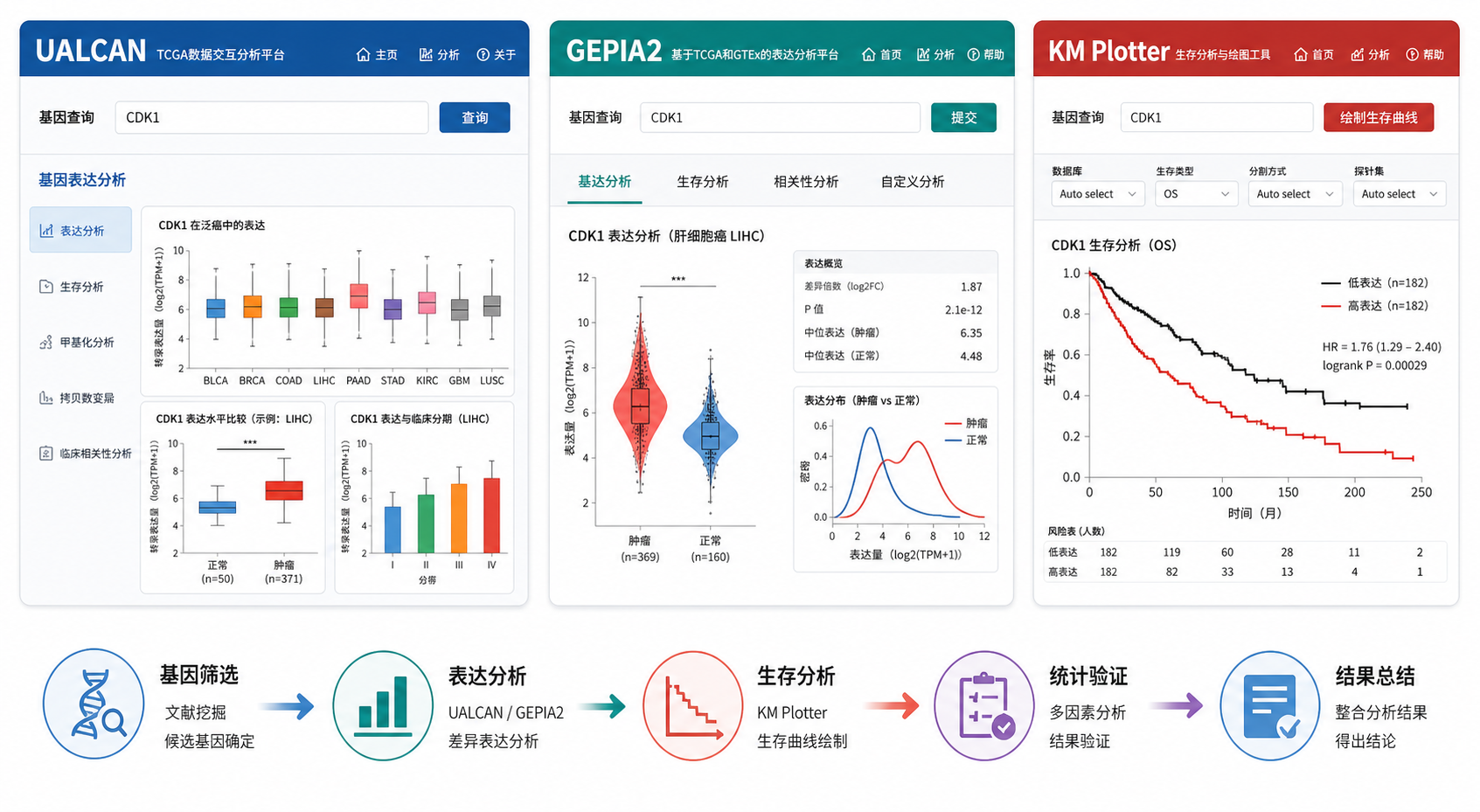
从上游知识库看,常用的在线预后分析工具主要有3个:UALCAN、GEPIA2、KM Plotter 。它们都基于公开肿瘤数据,但侧重点不同。UALCAN更适合快速查看TCGA相关表达、预后和甲基化信息。GEPIA2适合单基因和多基因生存分析。KM Plotter则更适合做更细的Kaplan-Meier生存验证。
1.2 先选对工具,能节省大量返工
如果你一开始就把所有基因丢进一个网站,往往会遇到结果杂乱、参数不统一、图不好解释的问题。正确做法是先定义终点,再匹配数据库功能。
可以按这个思路筛选:
- 想看TCGA里的表达和预后,优先用 UALCAN。
- 想做单基因、差异生存基因、多基因生存图,优先用 GEPIA2。
- 想做更标准的KM生存曲线和亚组分析,优先用 KM Plotter。
2. 用UALCAN做TCGA预后和表达验证
2.1 适合快速验证候选基因
UALCAN是一个交互式癌症组学分析平台,支持TCGA、MET500、CPTAC、CBTTC等公开数据。它的优势是入口清晰,适合对候选基因做第一轮验证。对于需要快速判断基因是否值得深入研究的场景,UALCAN很高效。
在知识库示例中,用户可点击主页进入TCGA分析,再选择TCGA Gene,输入基因或基因集,进行表达与生存分析。页面会同时给出表达结果、生存曲线、甲基化相关性分析,以及泛癌分析结果。
2.2 不只看生存,还要看调控层面
UALCAN的一个重点功能是启动子甲基化评估。也就是说,它不只是告诉你“这个基因高表达是否预后更差”,还可以进一步看甲基化是否可能参与表达调控 。这对肿瘤机制研究很重要。
此外,它还链接到 GeneCards、TargetScan、PubMed、HPA 和 GTEx 等外部资源。这类联动信息有助于把在线分析结果,快速扩展到文献和多组学验证。
2.3 建议使用场景
UALCAN适合以下任务:
- 快速查看目标基因在TCGA中的表达差异。
- 初步判断基因是否与患者生存相关。
- 补充启动子甲基化证据。
- 为后续实验设计提供方向。
3. 用GEPIA2做单基因和多基因生存分析
3.1 单基因分析最直接
GEPIA2是北京大学开发的在线生信分析网站,预处理了TCGA和GTEx数据。它的生存分析模块很成熟,适合做肿瘤基因数据库在线分析 中的核心验证步骤。
单基因分析时,输入基因名,选择OS,cutoff设为中位数,选择对应癌种数据集,例如LIHC,然后点击add和plot,就能得到生存曲线。这种方法简单、直观,适合论文中的主图或补充验证。
3.2 多基因分析更适合构建研究框架
GEPIA2还有两个特别实用的模块。一个是 Most Differential Survival Genes ,可以直接列出生存差异基因。另一个是 Survival Map ,可以输入多个基因做多基因生存分析。
在知识库示例中,输入15个有氧呼吸相关差异基因,选择OS、p值0.05、cutoff为中位数、数据集LIHC,点击plot即可生成热图。对于需要构建通路或基因集层面的研究,这个功能很有价值。
3.3 适合什么研究阶段
GEPIA2更适合:
- 单基因预后验证。
- 筛出生存相关基因。
- 做多基因初筛和结果展示。
- 结合表达数据形成“表达-预后”闭环证据。
4. 用KM Plotter做权威的生存曲线验证
4.1 数据覆盖广,适合发表前验证
KM Plotter是很多发表文章常用的生存分析工具。知识库指出,它可分析mRNA芯片、mRNA测序数据及miRNA,覆盖55,675个基因和18,674个癌症样本,评估54,000多个基因对21种癌症生存率的影响。这意味着它在样本规模和分析深度上都很有优势。
对科研人员来说,KM Plotter常被用于发表前的最终验证。因为它支持更细的亚组分析,也更适合做标准化的Kaplan-Meier曲线。
4.2 操作逻辑很清晰
使用时,输入单个或多个基因列表,选择预后指标,如OS,再按需要做亚组设置,最后点击draw KM plot即可查看结果。若是多基因分析,也可直接输入基因集后开始分析。
知识库举例中,ATP6V1C1和SLC16A3都可直接生成生存曲线。如果你的研究要强调“某个基因在不同分组中的预后价值”,KM Plotter非常适合。
4.3 什么时候优先选它
当你已经在前两个数据库里得到初步结果,KM Plotter就可以作为进一步确认工具。它适合:
- 发表前的独立验证。
- 亚组生存分析。
- 单基因或少量基因的深度预后分析。
5. 用流程化思路提升分析质量
5.1 不是只会点按钮,而是要会串联分析
很多人做肿瘤基因数据库在线分析 ,问题不在网站不会用,而在分析链条不完整。一个更稳妥的流程是:
- 先做差异筛选。
- 再做生存分析。
- 再看甲基化或外部注释。
- 最后把结果回到文献和实验设计中。
知识库里也提到,若涉及特定基因,还可以进一步做GO、KEGG分析,或延伸到miRNA预测、免疫浸润、相关性分析。这类延展能显著增强文章深度。
5.2 结果解释要遵循证据层级
在线数据库给的是“候选证据”,不是最终结论。比如:
- 生存曲线只能说明相关性。
- 表达差异不能直接证明致病机制。
- 甲基化关联也不能替代功能实验。
所以,最好的写法是把数据库结果作为假设生成工具,再结合实验或独立队列验证。 这也是E-E-A-T导向内容最重要的一点:客观、可复现、不过度推断。
5.3 推荐一个实用组合
如果你是医学生、医生或科研人员,可以直接按这个组合走:
- UALCAN :看表达、预后、甲基化。
- GEPIA2 :做单基因和多基因生存。
- KM Plotter :做最终生存验证。
这三个工具串起来,基本可以覆盖大多数肿瘤候选基因的在线验证需求。
总结Conclusion
如果你想高效完成肿瘤基因数据库在线分析 ,关键不是“会不会用网站”,而是“能不能按研究问题选对工具”。UALCAN适合快速验证表达和甲基化,GEPIA2适合单基因与多基因生存分析,KM Plotter适合更权威的生存曲线确认。
建议你把这3个工具作为基础组合,再根据课题需要扩展到GO、KEGG、免疫浸润或miRNA预测。
如果你希望系统掌握这套流程,建议直接学习解螺旋 整理的TCGA数据库与数据挖掘课程。它能帮你把“看结果”变成“做研究”,更快完成从候选基因到论文图表的转化。
- 引言Introduction
- 1. 先明确分析目标,再选数据库
- 2. 用UALCAN做TCGA预后和表达验证
- 3. 用GEPIA2做单基因和多基因生存分析
- 4. 用KM Plotter做权威的生存曲线验证
- 5. 用流程化思路提升分析质量
- 总结Conclusion