引言Introduction
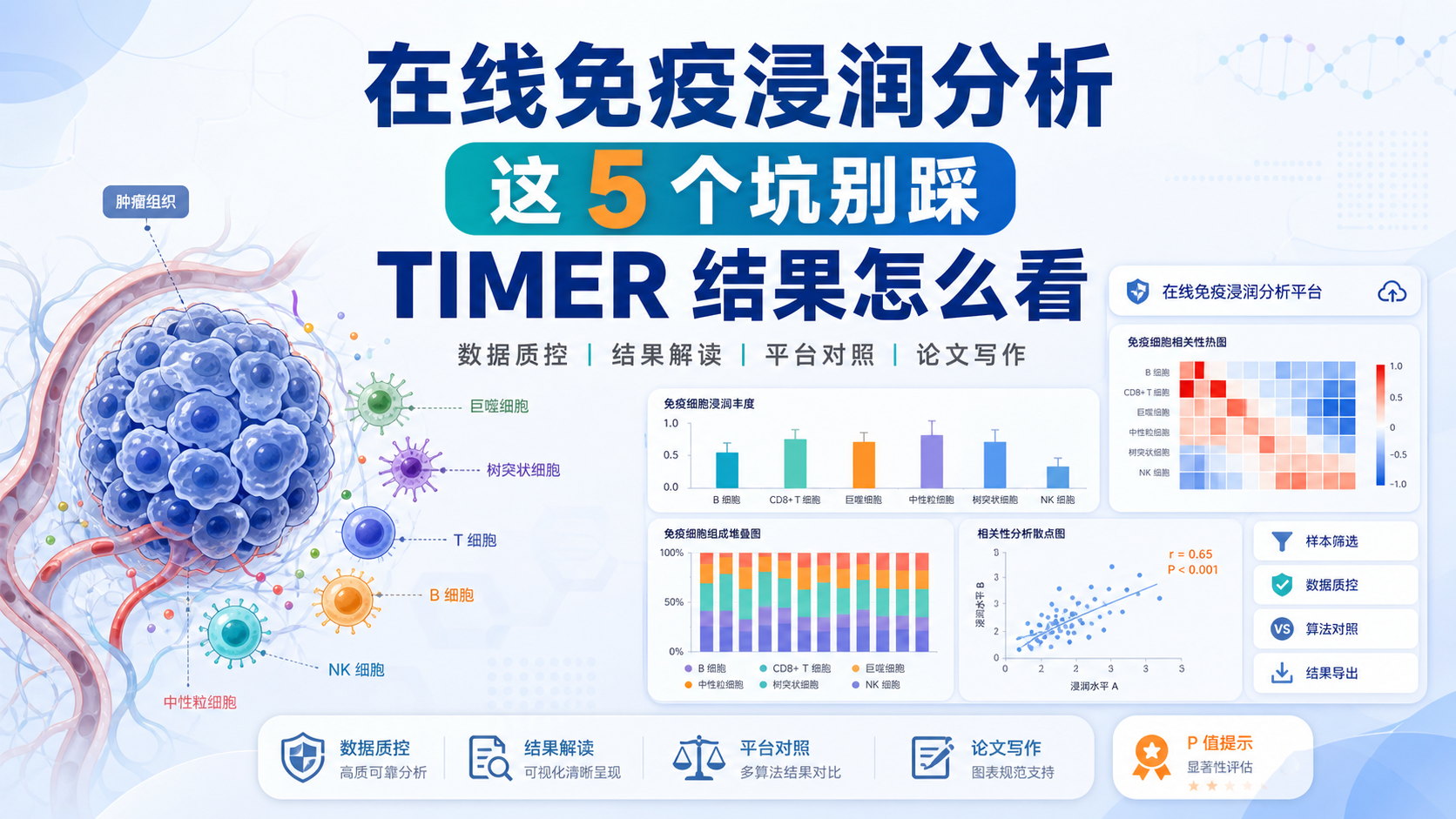
在线免疫浸润分析能快速回答一个关键问题,肿瘤样本里到底有哪些免疫细胞,差异是否真实存在。但很多人拿到结果后,只会看柱状图和P值,却忽略了TPM标准化、样本筛选和数据库差异,导致结论不稳。想把在线免疫浸润分析真正用于论文和课题,先要读懂结果背后的前提。
1. 在线免疫浸润分析的核心前提
1.1 先确认输入数据是否合格
在线免疫浸润分析最常见的工具是 TIMER、SSGSEA、CIBERSORT 一类平台。它们本质上都依赖表达矩阵。数据格式不对,后面的结果再漂亮也不可靠。
课程知识库里反复强调,Supersot 和 Timer 这类网站通常需要 TPM 数据 。因此,若原始数据是 FPKM,必须先转换。常用逻辑是每列 FPKM 除以该列总和,再乘以 10^6。这样做的目的,是让不同样本之间更可比。
1.2 样本处理会直接影响结果
在线免疫浸润分析前,还要处理样本类型。通常需要去掉正常样本,只保留肿瘤样本。课程中提到,TCGA 正常样本 ID 的第四位不是 0,这类样本应当剔除。另一个常见细节是把中划线替换成下划线,避免上传失败。
如果样本混入正常组织,免疫浸润比例可能被明显稀释。 这会让肿瘤组与对照组差异变小,甚至得出错误方向的结论。
1.3 基因长度和参考版本不能乱用
如果你打算从表达矩阵进一步做标准化,基因长度提取也要谨慎。课程明确提示,不要随便拿一个 GTF 文件就直接算。必须先确认参考基因组版本是否一致,比如 h79 与 h738 不能混用。
这类错误不一定立刻报错,但会悄悄影响下游分析。对在线免疫浸润分析而言,这种隐性偏差最危险。
2. 结果图怎么看才不算“只看热闹”
2.1 柱状图的核心是比例,不是绝对细胞数
很多人看到在线免疫浸润分析结果,第一反应是看某种免疫细胞“高不高”。但多数平台输出的是相对比例或相对分数 ,不是绝对细胞数。
这意味着,柱子变高,不一定代表细胞真的增加,也可能是其他细胞比例下降后的相对上升。
课程中提到的 CIBERSORT、TIMER、XCELL、MCP counter,原理不同,但共同点是利用表达特征估计免疫组成。因此解读时一定要先看平台方法,再解释生物学意义。
2.2 热图和堆叠图主要用于模式展示
在线免疫浸润分析常配套热图、堆叠柱状图或小提琴图。它们的作用不完全相同。
- 热图适合看整体模式。
- 堆叠图适合看每个样本的构成。
- 小提琴图适合看组间差异。
如果图里 22 种免疫细胞比例总和为 1,说明这是构成性数据。这类图更适合做比较,而不是直接下机制结论。
2.3 P值小,不等于结果就能发表
课程中多次强调,结果筛选常用 P 值小于 0.05。这个标准适合初筛,但不够证明稳健。
尤其当你同时比较多种免疫细胞时,应该关注是否存在多重检验问题。若只盯着一个显著结果,很容易高估其意义。
更稳妥的做法,是把 P 值、效应方向、样本数量和生物学背景一起看。 这才符合在线免疫浸润分析的基本逻辑。
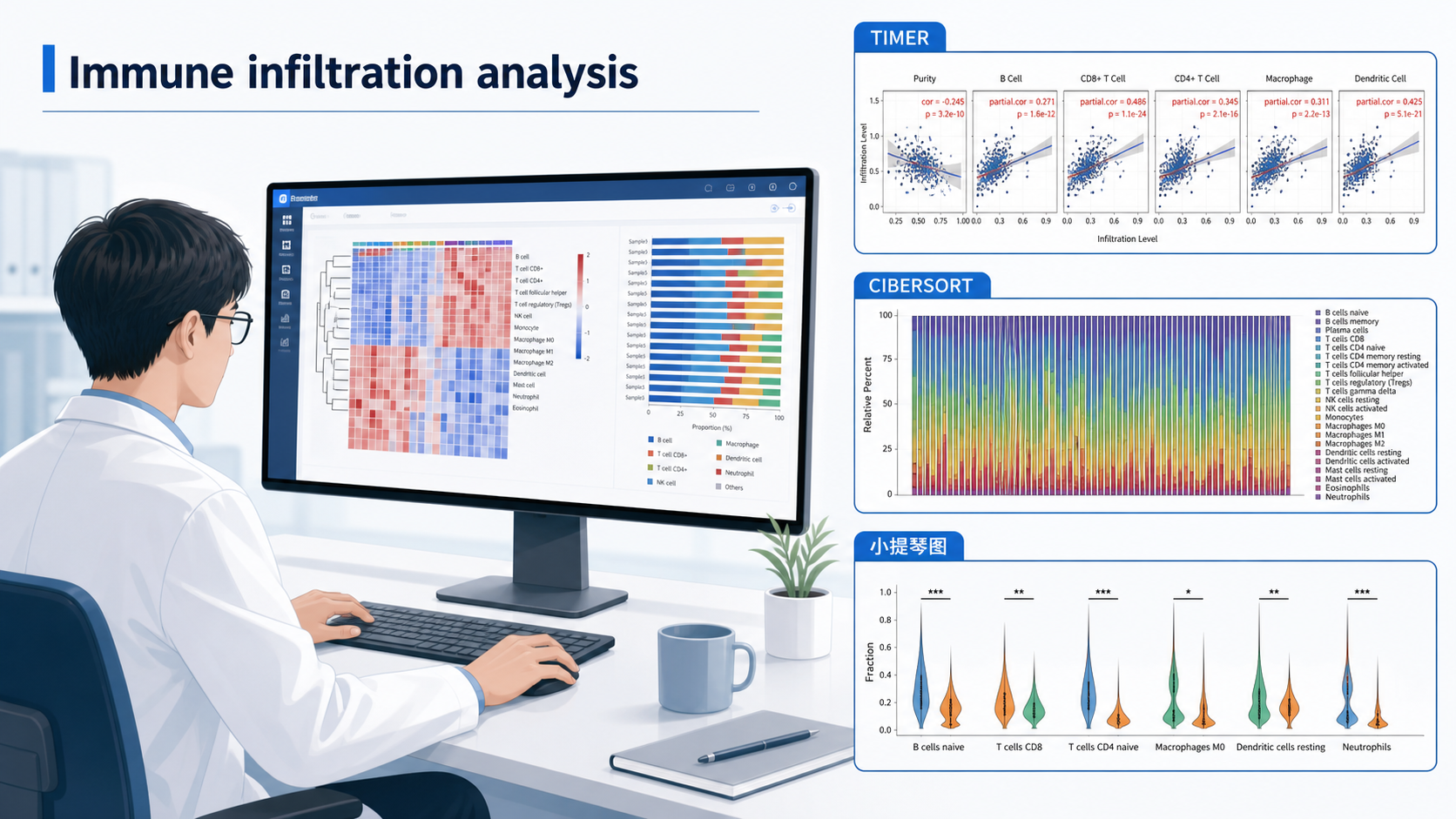
3. TIMER 和其他平台结果怎么对照理解
3.1 TIMER 常用于肿瘤免疫细胞分布
课程知识库提到,TIMER 由哈佛医学院刘晓乐教授团队开发,可估计多种癌症中的 6 类免疫细胞分布,包括 B 细胞、CD4 T 细胞、CD8 T 细胞、中性粒细胞、巨噬细胞和树突细胞。
它采用约束最小二乘回归思路,更适合做肿瘤免疫浸润的在线分析。
对于医学生和科研人员来说,TIMER 的价值在于:它不只是给你一个分数,而是帮助你判断某个基因变化是否伴随免疫微环境改变。
3.2 不同算法之间出现差异很正常
CIBERSORT 参考 22 种免疫细胞,XCELL 可覆盖更多细胞类型,MCP counter 侧重标记基因定量。由于参考矩阵不同,结果不完全一致是正常现象。
所以,在线免疫浸润分析不应只依赖一个平台。更合理的做法是交叉验证。
例如,同一个基因若在 TIMER 和 CIBERSORT 中都与 CD8 T 细胞呈负相关,结论可信度会更高。如果只有一个平台显著,最好先保留谨慎态度。
3.3 相关性不等于因果
这是最容易被误读的一点。
在线免疫浸润分析常见的是“基因表达与免疫细胞比例相关”。相关只能说明两者同时变化,不能证明谁导致谁。
因此,写文章时不要直接写“该基因促进某免疫细胞浸润”,除非你有实验验证或机制证据。
4. 结果解读时最该关注的三个层面
4.1 先看方向,再看强度
解读在线免疫浸润分析时,建议按三个层面阅读。
- 哪些细胞升高或降低。
- 差异是否有统计学意义。
- 变化是否符合疾病背景。
例如,课程中提到 TMB high 组中,CD8 T 细胞、CD4 记忆静息 T 细胞、M1 和 M2 巨噬细胞、树突静息细胞显著低于 TMB low 组。这个结果提示高 TMB 组可能存在免疫抑制,且与预后变差一致。
能和临床表型对上,结果才更有解释力。
4.2 再看样本规模和过滤条件
在线免疫浸润分析的稳定性,与样本数密切相关。课程提到某些分析最终有 238 个样本参与,其中 121 个为 low 组,117 个为 high 组。这样的样本规模,结果通常比小样本更稳。
但如果你在分析过程中筛掉大量样本,最终结论就要更谨慎。
所以,报告结果时最好写清楚:
- 总样本数。
- 过滤规则。
- 分组方式。
- 统计检验方法。
4.3 最后看是否能回到机制假设
好的在线免疫浸润分析,不是只给一张图,而是能回到课题假设。
如果你的研究关注某个基因、某个通路或某个突变,那么免疫浸润结果应当服务于主线。比如差异基因、生存分析、拷贝数变异和免疫浸润之间是否形成闭环。
有闭环,文章才像一篇完整研究,而不是图表拼接。
5. 写论文时如何把在线免疫浸润分析讲清楚
5.1 结果描述要具体
不要只写“免疫细胞显著变化”。这太空。
建议写清:
- 哪些细胞变化。
- 哪个组更高。
- 用了什么检验。
- P 值是多少。
比如可以写成:“与低表达组相比,高表达组 CD8 T 细胞比例显著下降,Wilcoxon 检验 P < 0.05。”
这种写法最适合论文结果部分。
5.2 讨论部分要避免过度推断
讨论时可以提出机制假设,但不要把相关性直接写成因果。
更稳妥的表达是“提示”“可能”“与……一致”。
这不仅更符合学术规范,也更容易通过审稿。
5.3 图注和方法必须一致
课程知识库特别强调图形一致性。不同图里最好统一标注方式、统计方法和分组命名。
如果前文用加号标记死亡事件,后文却不标,就会显得不规范。
在线免疫浸润分析的可信度,很多时候就体现在这些细节里。
总结Conclusion
在线免疫浸润分析的价值,不在于“做出一张图”,而在于把表达数据、样本处理、平台原理和统计解释串成完整逻辑 。解读时要先确认数据是否为 TPM,样本是否经过规范筛选,再判断细胞比例、P 值和生物学方向。只有这样,结果才更接近真实的肿瘤免疫状态。
如果你希望把在线免疫浸润分析用于课题设计、文章复现或结果解读,建议优先建立标准化流程,再结合解螺旋的课程与工具体系提升效率。用规范的数据处理和清晰的解读框架,才能把免疫浸润结果真正转化为可发表、可验证的研究结论。
- 引言Introduction
- 1. 在线免疫浸润分析的核心前提
- 2. 结果图怎么看才不算“只看热闹”
- 3. TIMER 和其他平台结果怎么对照理解
- 4. 结果解读时最该关注的三个层面
- 5. 写论文时如何把在线免疫浸润分析讲清楚
- 总结Conclusion