引言Introduction
做肿瘤生信时,最耗时间的不是画图,而是找数据、整理临床分组和反复验证结果。UALCAN 把TCGA、CPTAC、MET500等公共组学数据整合到一个交互式平台,适合快速做表达、预后、甲基化和泛癌分析。
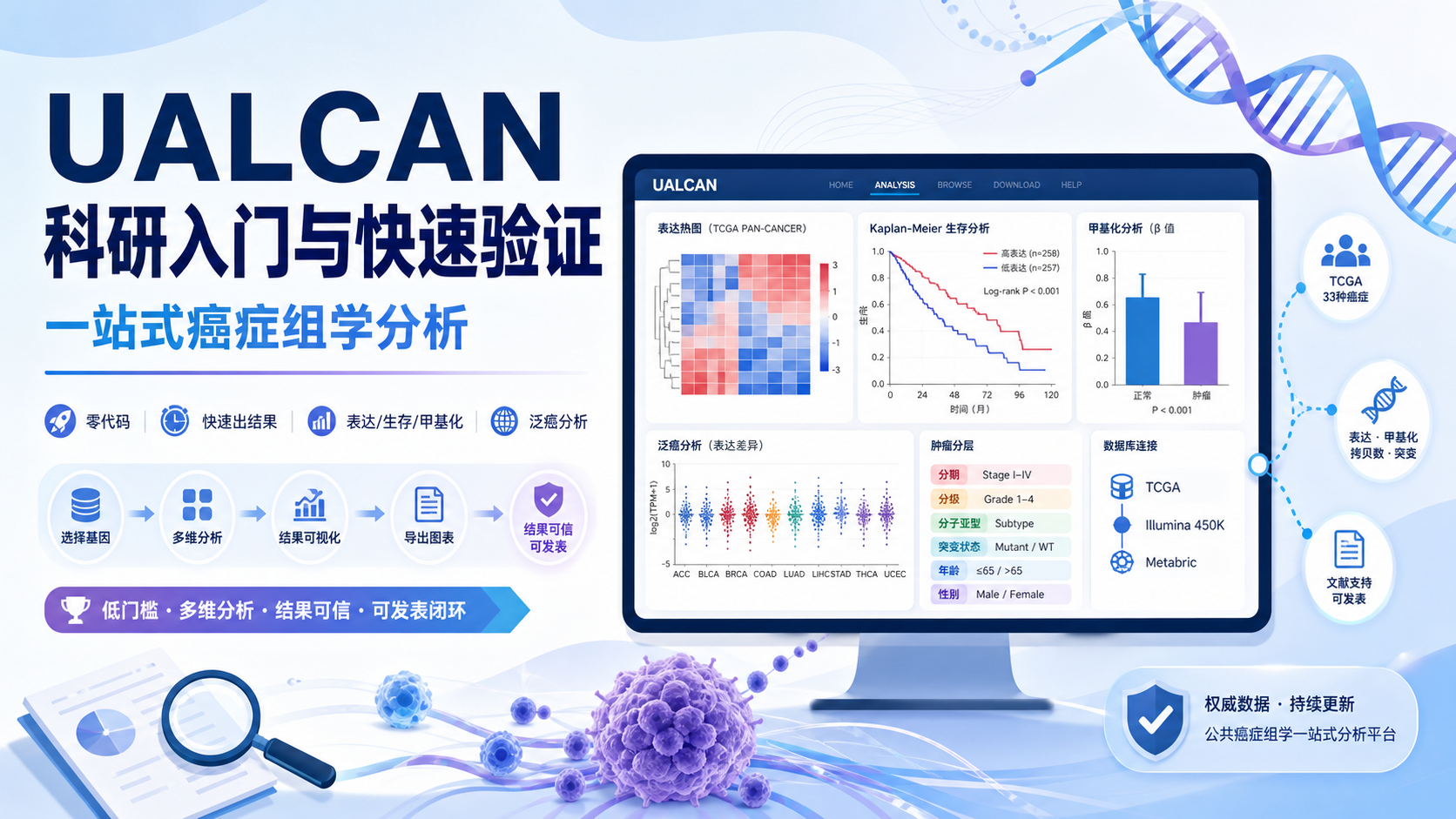
1. UALCAN为什么适合科研入门和快速验证
1.1 一站式调用公共癌症组学数据
UALCAN 的核心价值,是把多个公共数据库的分析入口集中到同一界面。用户可以直接访问TCGA、MET500、CPTAC等数据来源,不必自己下载原始数据、清洗样本、再做分组。
这对医学生、医生和科研人员尤其重要。因为很多课题的第一步,不是复杂建模,而是先判断一个基因在肿瘤里“有没有信号”。
平台支持查看蛋白、miRNA、lincRNA表达谱,还能关联患者生存信息。对于需要先做“可行性筛查”的课题,这种设计很高效。
1.2 适合验证候选基因和生物标志物
在论文选题阶段,科研人常会先从差异基因、文献热点或家族基因入手。UALCAN 可以帮助快速验证候选基因是否在肿瘤组织中异常表达,是否与临床结局相关。
如果一个基因在多个癌种中都表现出稳定差异,后续就更值得进入机制实验或更深层的组学分析。
根据教程知识库,UALCAN还通过外部链接接入HPRD、GeneCards、PubMed、TargetScan、Human Protein Atlas、DrugBank、Open Targets和GTEx。也就是说,它不只是“出图工具”,还是一个便于扩展信息的入口。
2. UALCAN的第一个关键优势:操作门槛低,结果输出快
2.1 不依赖代码,适合临床和基础双背景用户
UALCAN 最大的优势之一,是不需要编程即可完成常见分析。对于习惯临床思维、但不熟悉R或Python的人来说,这一点非常重要。
平台主界面结构清晰,常见入口包括Home、Tutorial、TCGA、CPTAC、CBTTC、FAQ、About Us和Citations。新手可以直接通过Tutorial上手。
从实际使用角度看,它把复杂的数据分析过程压缩成几个步骤。输入基因,选择分析类型,点击Explore,就能得到可视化结果。对于需要快速出图、快速判断方向的项目,这种效率非常高。
2.2 适合教学、汇报和初筛
在研究生教学、组会汇报和课题开题中,UALCAN 很适合做“第一轮证据”。
你可以快速拿到以下信息:
- 基因在肿瘤与正常组织中的表达差异。
- 不同临床亚型中的表达情况。
- 生存分析结果。
- 启动子区甲基化对表达的影响。
- 泛癌表达趋势。
这些内容足以支撑初步假设,也方便进一步安排实验验证。对时间紧、任务多的科研人来说,这是非常实用的优势。
3. UALCAN的第二个关键优势:多维度分析能力强
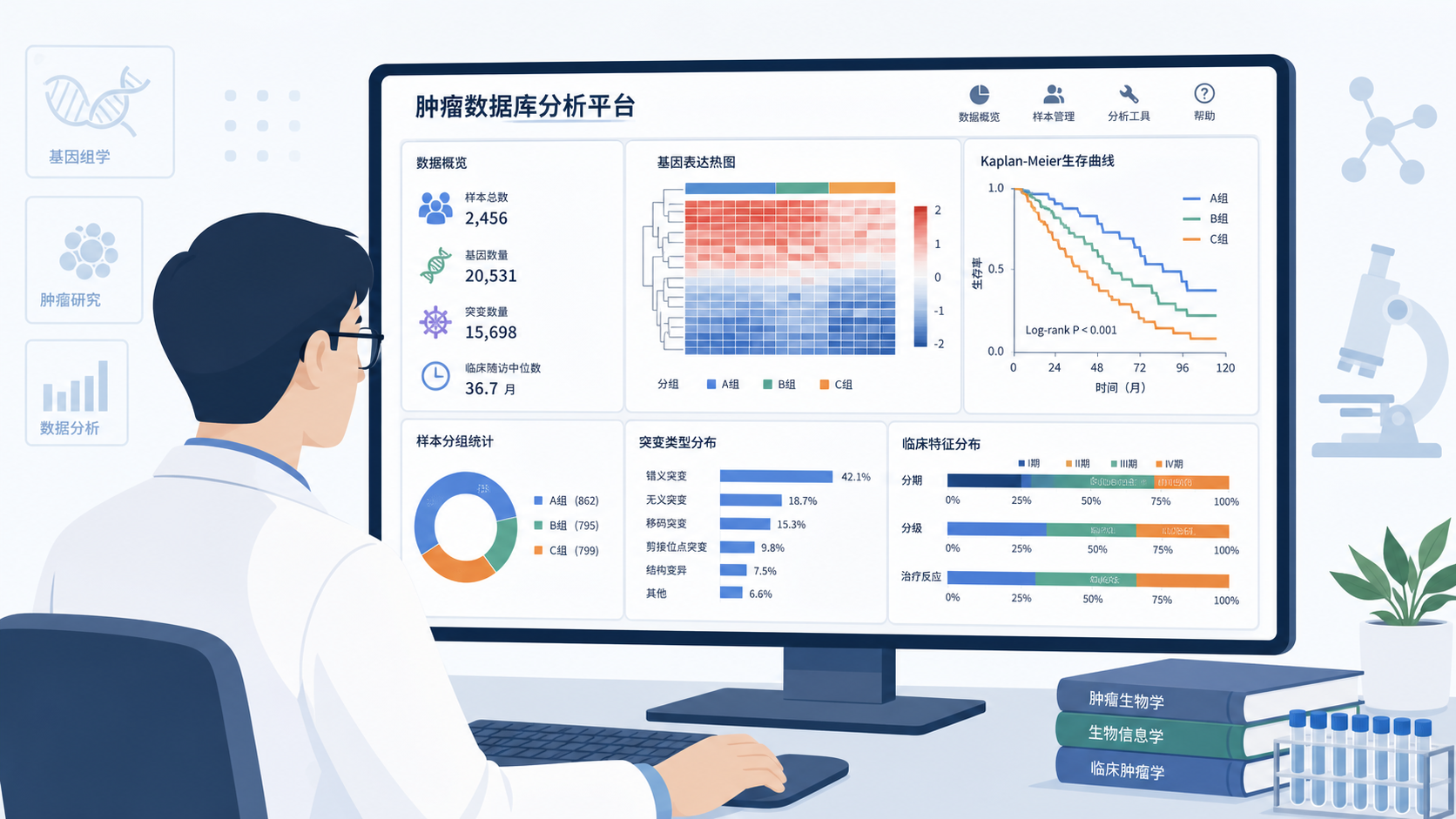
3.1 同时覆盖表达、生存和甲基化
很多数据库只能做单一维度分析,而UALCAN 支持多种常用维度。
知识库显示,它可以做蛋白、miRNA、lincRNA表达谱分析,也可以查看患者生存信息,还能评估启动子区甲基化对基因表达的表观遗传调控。
这意味着,一个基因的研究不必只停留在“表达升高或降低”。你还可以继续追问:
- 它是否影响预后。
- 它的异常表达是否与甲基化相关。
- 它在不同亚型中是否一致。
- 它在蛋白层面是否同样异常。
这种多层次验证,明显更符合E-E-A-T中的专业性要求。
3.2 可做泛癌分析,提高研究广度
UALCAN 支持泛癌基因表达分析。对科研选题来说,这一功能很重要。
因为很多肿瘤相关基因并不只在单一癌种中起作用。泛癌分析可以帮助你判断这个基因是“特定癌种特异”,还是“跨癌种共性”。
如果一个分子在多个癌种中都表现异常,它更适合作为后续标志物筛选、药物靶点优选或共性机制研究的起点。知识库中的功能基因集检索模式,也说明UALCAN适合从“基因家族”或“通路集合”切入,而不是只盯一个单点基因。
3.3 支持肿瘤分层,结果更接近真实临床场景
UALCAN并不只是给一个总的表达均值。它强调肿瘤亚型和临床变量分层。
这对临床科研非常关键。因为同一个基因,在不同分期、分级或分子亚型中的意义可能完全不同。
分层分析能显著减少“平均化”带来的误判。
知识库中的应用范例提到,CDCA家族成员在HCC研究中就利用了UALCAN评估mRNA表达及其与临床病理变量的关系。这说明它不仅适合做展示,也适合做正式研究中的证据模块。
4. UALCAN的第三个关键优势:结果可信,便于和文献体系衔接
4.1 数据来源清晰,引用路径明确
做科研最怕的是数据来历不清。UALCAN 直接基于公共数据库,并且在主界面提供引用文献和更新信息。
对于论文写作和方法学描述,这很有帮助。因为你可以明确交代数据来源、版本和分析逻辑,提升文章可重复性。
知识库显示,UALCAN最早由Chandrashekar等人发表于Neoplasia,2017年。平台已经被广泛用于肿瘤基因表达和生存分析研究。对读者来说,这种“有文献支撑”的工具,更容易建立信任。
4.2 便于和外部数据库联用
科研工作很少只靠一个网站完成。UALCAN 的优点在于,它能和HPRD、GeneCards、PubMed、TargetScan、Human Protein Atlas、DrugBank、Open Targets、GTEx等数据库形成衔接。
这让它特别适合作为“中转站”。
例如,你可以先在UALCAN中确认一个基因在肿瘤中的表达和预后意义,再去HPA看蛋白定位,去PubMed查已有机制研究,去Open Targets看靶点开发线索。
这种组合式分析,比单纯截图更能支撑论文逻辑。
4.3 更适合讲清楚“为什么选这个基因”
在投稿和答辩中,审稿人或导师常问一个问题:为什么是这个基因,不是别的?
UALCAN 能帮助你回答这个问题。因为它提供了表达、分层、预后和甲基化等多角度证据。
当你把这些结果组合起来时,研究选题就不再只是“碰巧挑中一个基因”,而是“基于公共数据系统筛选出的候选分子”。
5. UALCAN的第四个关键优势:适合形成可发表的分析闭环
5.1 从初筛到验证,路径更完整
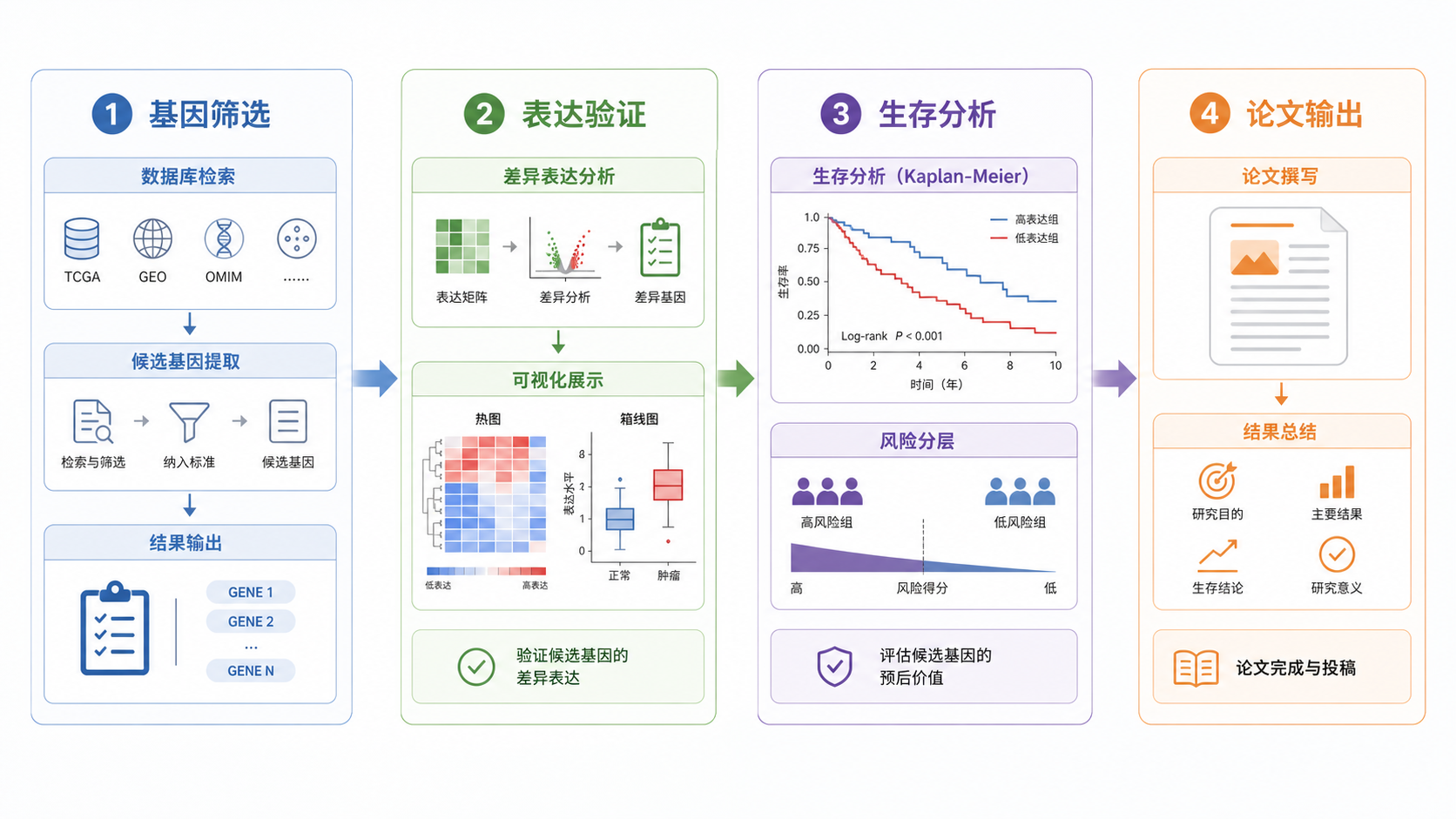
一个成熟的生信课题,通常需要从筛选到验证再到解释。UALCAN 最适合承担前两步。
你可以先用它确认候选基因的表达模式,再结合临床变量和生存结果做优先级排序。之后再进入实验验证、免疫组化、qPCR或更深层组学分析。
如果课题目标是高效产出,UALCAN可以明显缩短前期筛选时间。
它的价值不是替代实验,而是减少无效实验。
5.2 对多组学课题尤其友好
知识库中提到,UALCAN可用于甲基化等多组学展示,也支持CPTAC蛋白组数据。
这使它很适合“转录组+蛋白组+表观遗传”这种论文结构。对于临床科研来说,多组学展示更容易提高文章完整度。
当然,前提是分析逻辑要合理,不能为了“多组学”而堆砌图表。
5.3 适合和解螺旋的教程体系配套使用
对于很多科研新人来说,问题不是不会点,而是不知道先看什么、后看什么。
UALCAN 虽然简单,但如果缺少路线图,仍然容易走弯路。比如不知道该先看TCGA还是CPTAC,不知道表达差异和预后分析该如何组织,也不知道怎样把甲基化结果写进文章逻辑里。
这时,配合解螺旋 的数据库教程和分析思路,会更高效。你可以借助系统化课程快速理解UALCAN的入口、结果解读和论文呈现方式,把“会用工具”变成“会做课题”。这一步,往往决定你的数据能不能真正转化成文章。
总结Conclusion
UALCAN 之所以被科研人广泛使用,核心就在于四点:上手快、多维度、可联用、能形成分析闭环。它特别适合医学生、医生和科研人员做肿瘤公共数据初筛、候选基因验证和论文前期证据整理。
如果你正在做肿瘤生信,想快速判断一个基因是否值得深入研究,UALCAN 是非常实用的第一站。进一步想系统掌握数据库分析思路,可以结合解螺旋 的相关教程,把工具用成方法,把结果做成文章。
- 引言Introduction
- 1. UALCAN为什么适合科研入门和快速验证
- 2. UALCAN的第一个关键优势:操作门槛低,结果输出快
- 3. UALCAN的第二个关键优势:多维度分析能力强
- 4. UALCAN的第三个关键优势:结果可信,便于和文献体系衔接
- 5. UALCAN的第四个关键优势:适合形成可发表的分析闭环
- 总结Conclusion