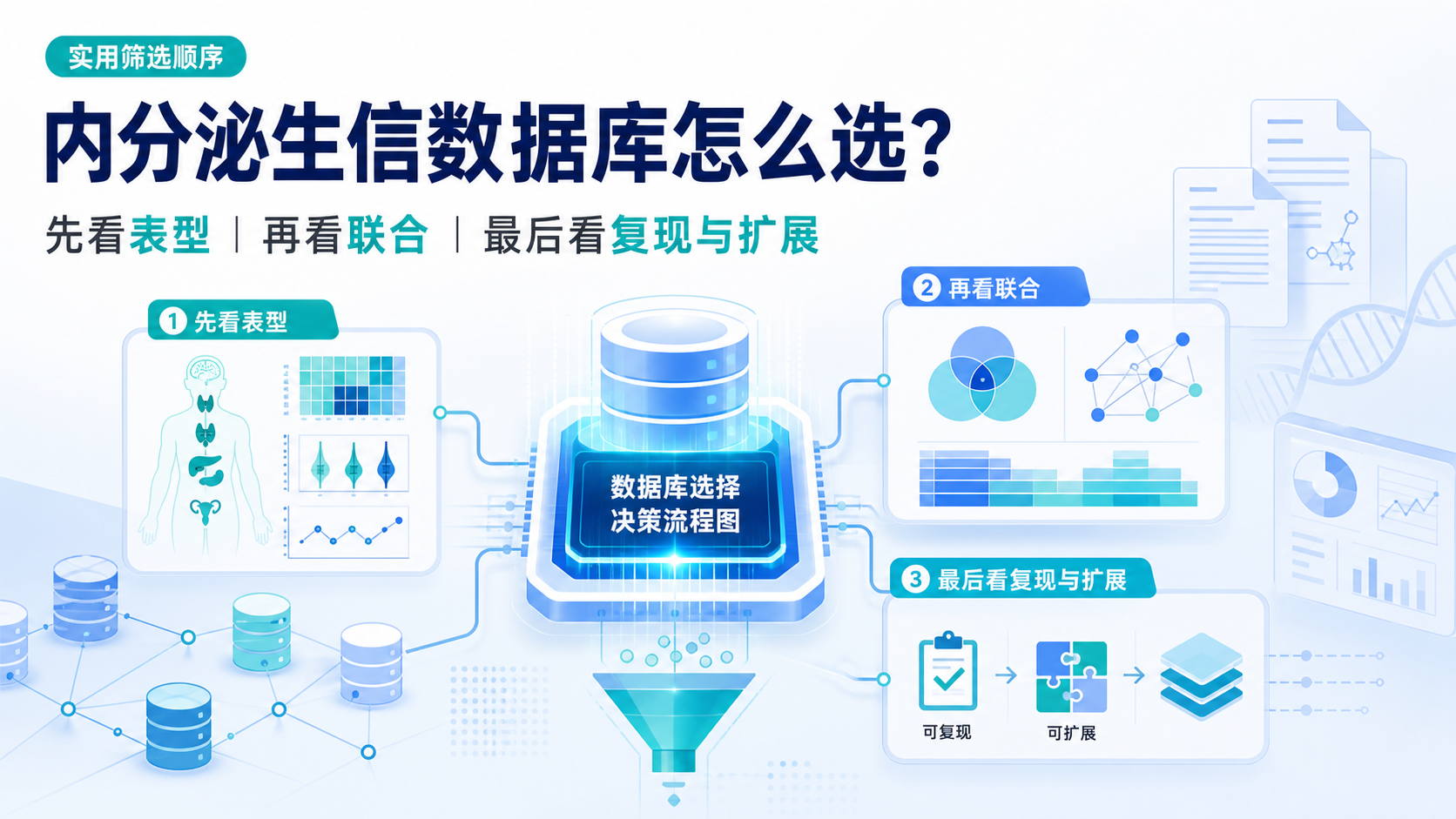
引言Introduction
肾病研究常见痛点是,数据分散、疾病分型复杂、临床变量不统一,导致课题难以快速落地。肾病专科生信数据库 如果选型不准,后续分析、分组和文章产出都会受影响。本文结合公共数据库和专科数据库思路,拆解如何精准选型。
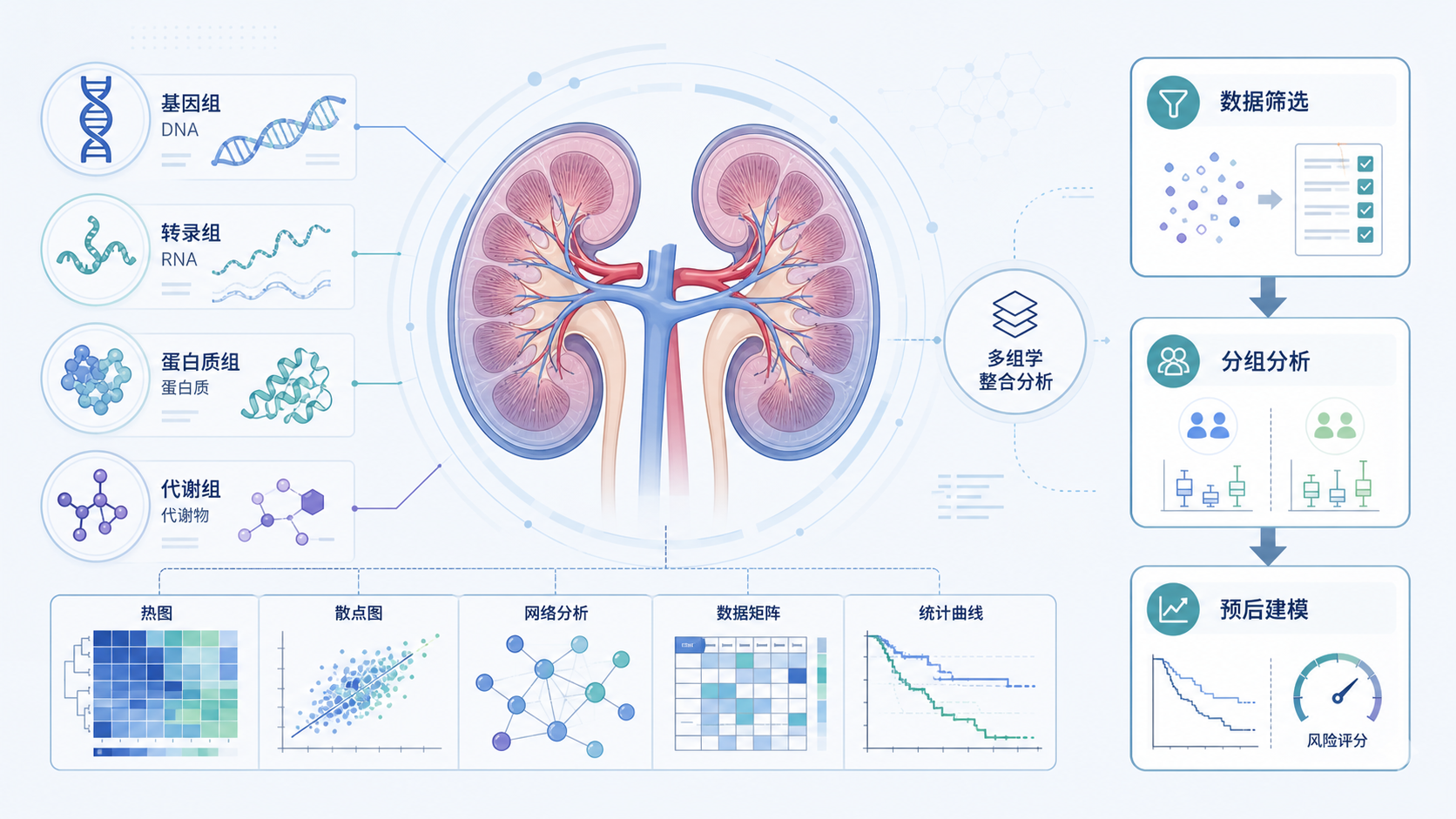
1. 先明确,肾病专科生信数据库解决什么问题
1.1 选型的核心,不是“库多”,而是“问题匹配”
做肾病研究,第一步不是找最多的数据库,而是先定问题。是做慢性肾病、急性肾损伤,还是肾小球疾病。是做临床分层,还是做分子机制,还是做预后模型。肾病专科生信数据库的价值,在于能否支持你的研究问题。
知识库中提到,研究设计必须先锁定疾病,再锁定临床问题或科学问题。这个原则在肾病同样适用。比如,你想比较不同分型、不同年龄、不同病程,数据库就必须有对应的临床变量。否则,再强的分析也会卡在分组环节。
1.2 肾病研究常见的3类需求
肾病研究通常落在三类需求上。
- 公共数据挖掘。
- 多组学联合分析。
- 临床预测模型或专科数据库搭建。
知识库中提到,单细胞、多组学、空间转录组、转录组联合分析已经成为高频方向。对于肾病课题,这意味着你可以优先选支持这些分析类型的平台,而不是只看单一表达矩阵。
如果你的目标是发文章,数据库必须同时满足“可分析”和“可讲故事”。
2. 肾病专科生信数据库的选型标准
2.1 先看疾病覆盖是否足够细
知识库强调,像GBD、JVTD这类数据库的优势在于疾病覆盖广,且可做临床病理因素关联分析。放到肾病场景,选型时先看它是否覆盖常见肾病亚型,以及是否能按年龄、性别、病程、并发症等维度拆分。
如果数据库只提供笼统的“肾病”标签,而没有亚型信息,往往很难支撑高质量研究。对肾病专科生信数据库来说,分层越细,研究空间越大。
2.2 再看数据类型是否够用
一个可用的数据库,至少要看三件事。
- 是否有转录组数据。
- 是否支持单细胞分析。
- 是否可扩展到空间转录组、多组学或预后分析。
知识库中明确提到,单细胞分析应用广泛,且和空间转录组联合分析很受欢迎。对于肾病这类组织异质性强的疾病,单细胞数据尤其关键。它能帮助你区分肾小管、免疫细胞、成纤维细胞等不同群体的变化。
2.3 还要看能否支撑“从发现到验证”的链条
高质量生信研究不是只做差异分析。知识库里反复强调的流程包括:
- 细胞群注释。
- 亚群分析。
- 关键基因筛选。
- 火山图和相关性分析。
- GSEA富集分析。
- WGCNA筛选关键基因。
- 预后分析验证。
肾病专科生信数据库如果能把这些步骤串起来,才能真正提高发文效率。
3. 哪类数据库更适合肾病专科研究
3.1 公共数据库适合“起步快”
如果你是医学生、住培医生或刚入门的科研人员,公共数据库是最快的切入点。知识库中提到,GEO、TCGA、GBD、公开临床数据库,都可以用于数据挖掘。
对肾病来说,公共数据库适合做三件事。
- 先验证课题是否有数据。
- 再筛选是否有稳定分组。
- 最后判断是否具备发表潜力。
先找数据,再谈创新。 这是最稳妥的路径。
3.2 专科数据库适合“深挖临床问题”
如果你已经明确肾病方向,专科数据库的优势更明显。它通常能整合特定疾病的临床信息、样本信息和组学数据,适合做更深入的分层分析和临床工具开发。
知识库中提到,数据库类文章的优势在于不一定需要额外实验验证,而且引用率往往较高。对肾病研究来说,如果数据库能持续更新,还能不断产出新选题。这对科室建设和团队长期发文都很有价值。
3.3 自建数据库适合“形成壁垒”
知识库特别强调自建数据库的重要性。原因很简单。别人能复现的分析,价值有限。你如果能围绕肾病建立自己的数据库,就能把数据、分析和展示平台整合在一起。
适合自建的场景包括:
- 科室积累了较多病例。
- 研究方向相对集中。
- 想持续产出系列文章。
- 需要在线分析功能,服务团队和同行。
自建肾病专科生信数据库,不只是为了写一篇文章,更是为了建立长期资源。
4. 如何判断一个肾病专科生信数据库是否值得用
4.1 看它是否支持明确分组
肾病研究常见分组包括疾病组与对照组、不同病理分型、不同年龄段、不同治疗状态。知识库中提到,很多高质量文章的关键,不在于复杂方法,而在于分组设计好。
所以你要检查数据库是否支持以下信息:
- 病种细分。
- 临床病理变量。
- 样本来源清晰。
- 分组逻辑可复现。
如果分组做不起来,后面的差异分析、通路分析、模型构建都没有意义。
4.2 看它是否便于找“关键分子”
知识库提到,生信分析的核心之一,是通过层层筛选锁定关键基因,再做表达、通路、预后或诊断分析。对肾病来说,数据库最好能支持:
- 差异表达筛选。
- 相关性分析。
- hub基因识别。
- ROC或Cox分析。
- 预后和临床价值评估。
能支持“筛选—验证—转化”闭环的数据库,才是好数据库。
4.3 看它是否更新及时
知识库明确提到,数据库更新非常重要,尤其是最新版本与旧版本差别可能很大。对肾病研究来说,更新决定了数据是否过时,分析结论是否可信。
如果一个数据库多年不更新,可能会带来三个问题。
- 数据样本不完整。
- 临床变量滞后。
- 结论不适合当前研究场景。
更新频率,是选型时必须核查的硬指标。
5. 肾病专科生信数据库的实用选型策略
5.1 先试课题,再定平台
不要一开始就追求“大而全”。你可以先拿一个具体肾病问题试跑。比如:
- 某种肾病与对照的差异分析。
- 某个免疫细胞亚群变化。
- 某个关键基因的诊断价值。
- 某个临床因素与预后的关系。
如果平台能顺利完成这一轮,再扩大到多组学和联合分析。这样最稳。
5.2 优先选择“少代码或零代码”可操作平台
知识库中提到,GEPIA2、UALCAN等工具之所以常用,是因为它们适合不擅长代码的人快速完成分析。对于临床医生尤其重要。因为大多数人真正缺的,不是想法,而是落地速度。
对于肾病专科生信数据库,最好同时兼顾专业深度和操作门槛。
5.3 把数据库当成研究工具,不是展示工具
很多人选数据库,只看界面是否漂亮。其实更该看它能否服务科研流程。真正有价值的数据库,应该帮助你完成:
- 选题。
- 分组。
- 筛分子。
- 建模型。
- 做验证。
这也是知识库反复强调的核心逻辑。先有框架,再填内容。
总结Conclusion
肾病研究要想做得快、做得稳,关键不是盲目追求数据库数量,而是围绕研究问题精准选型。肾病专科生信数据库应优先满足疾病覆盖细、临床分层清、数据类型全、更新及时、分析链条完整这五个条件。
如果你希望把肾病课题从“能做”提升到“好发”,就要尽早建立自己的专科数据库思维。对于需要高效落地的团队,解螺旋 可以帮助你围绕肾病方向进行数据库选型、课题设计和个性化定制,让数据挖掘更快进入可发表阶段。
- 引言Introduction
- 1. 先明确,肾病专科生信数据库解决什么问题
- 2. 肾病专科生信数据库的选型标准
- 3. 哪类数据库更适合肾病专科研究
- 4. 如何判断一个肾病专科生信数据库是否值得用
- 5. 肾病专科生信数据库的实用选型策略
- 总结Conclusion