





引言Introduction
内分泌专科生信数据库怎么选,直接决定后续选题、建模和发文效率。很多研究者不是不会分析,而是一开始选错数据库 ,导致样本不够、表型不准、结果难以复现。
1. 先看数据库是否支持“内分泌表型”匹配
1.1 表型越清晰,故事越容易成立
做内分泌专科生信数据库,第一步不是看数据量,而是看表型定义是否足够准确 。内分泌疾病常常涉及代谢、激素、炎症、免疫和组织特异性变化。如果数据库只给出宽泛诊断标签,后续很难建立明确的机制链条。
知识库里提到,选题可以从两组比较、配对或非配对比较、泛览比较入手,也可以扩展到临床特征、分子特征、通路特征等多个维度。对内分泌方向来说,这意味着你要优先找能同时覆盖疾病分型、临床分层和治疗反应的数据集。
1.2 优先选择能做分层分析的数据
好的内分泌专科生信数据库,不只是“有病人”,而是“有可分层的人群”。
例如,能区分高低风险组、治疗前后组、不同代谢状态组、不同激素水平组的数据,更适合做差异分析和预后分析。
如果数据库还能结合临床信息,如年龄、性别、分期、复发、OS等,就更有价值。因为后续可以直接接上单因素、多因素、ROC、nomogram、C-index 和 DCA 等分析模块,减少补数据的时间。
2. 再看数据库是否“能联合”,而不是单点分析
2.1 内分泌研究更适合多维整合
知识库反复强调,多组学联合分析能把故事做得更完整。对于内分泌专科生信数据库也是一样。单一表达矩阵往往只能回答“差异是否存在”,但很难回答“为什么存在”。
在内分泌方向,常见的联合维度包括:
- 转录组和临床数据库联合
- 转录组和甲基化联合
- 单细胞和空间转录组联合
- 表型评分和细胞亚群联合
- 药靶分析和分子对接联合
联合分析的核心价值,是把“相关性”推进到“机制链条”。 这也是更容易获得高质量结果的原因。
2.2 数据库要能支撑后续网络构建
知识库中提到,生信分析不仅是差异表达,还包括PPI、ceRNA、RBP、TF、药物靶点预测等互作网络。
对内分泌专科生信数据库而言,这一点非常关键。因为内分泌疾病往往涉及多层调控,单个基因很难解释完整病理过程。
如果数据库本身信息完整,你就能顺着分析走下去:
- 找差异基因。
- 做富集分析。
- 找核心通路。
- 构建互作网络。
- 再做临床验证或外部验证。
数据库能不能支撑这条链,是选型时必须看的第二个指标。
3. 最后看数据库是否适合“复现”和“扩展”
3.1 可复现性决定审稿风险
做内分泌专科生信数据库,最怕的是数据来源不清、样本注释混乱、平台差异太大。知识库中提到,数据清洗是一个非常耗时的环节,有时会持续数月。这个信息非常重要。
所以,选数据库时要重点检查:
- 样本量是否足够
- 是否有明确纳入和排除标准
- 是否存在黑灰数据集问题
- 基因注释是否一致
- 不同队列之间平台是否可比
一个不能复现的数据库,通常很难支撑高质量文章。
3.2 可扩展性决定项目上限
内分泌疾病经常不是单线条疾病。比如代谢异常、激素紊乱、炎症反应、肿瘤微环境、免疫改变,常常会同时出现。
因此,数据库最好能继续扩展到多数据库、多疾病、多组学联合分析。
知识库里提到,结合越多,故事通常越完整,得分也可能更高。但前提是组合必须有逻辑,而不是机械堆砌。不是组学越多越好,而是证据链越完整越好。
如果数据库支持外部验证、交叉验证或多队列验证,那么研究的可信度会明显提高。对于医学生、医生和科研人员来说,这比单纯追求“样本多”更重要。
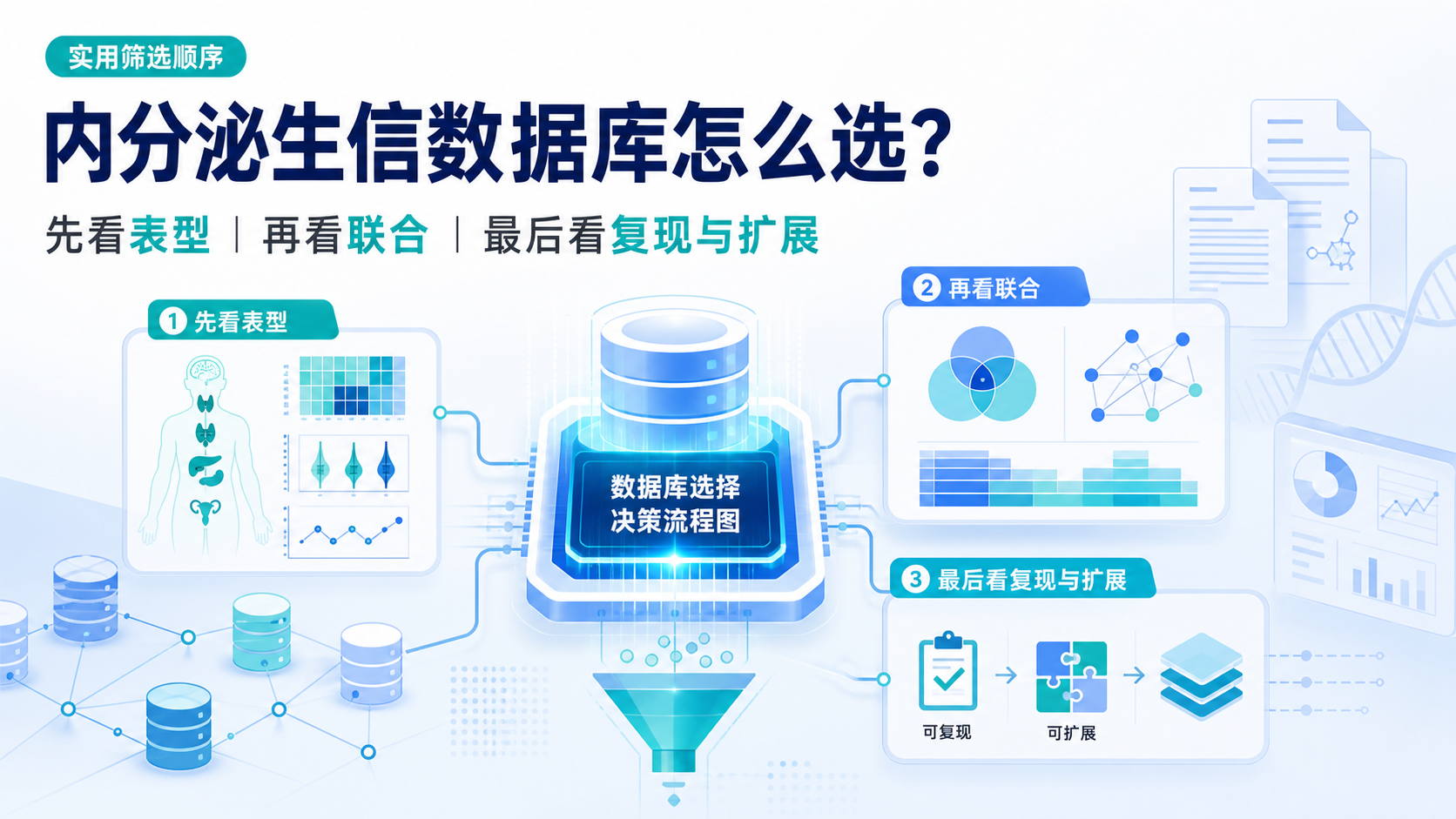
4. 内分泌专科生信数据库的实用筛选顺序
4.1 先定研究问题,再定数据库
很多人一开始就问“哪个数据库最好”,但正确顺序应该是先定问题。
例如:
- 想做诊断模型,优先找有完整临床变量的数据库。
- 想做机制研究,优先找组学深、可做通路分析的数据库。
- 想做亚群研究,优先找单细胞或空间数据。
- 想做药靶研究,优先找能接药物库和靶点库的数据。
这也是知识库中提到的核心原则:技术要服务于科学问题,而不是为了技术而技术。
4.2 关注数据质量,而不是只看知名度
有些数据库很有名,但并不一定适合你的题目。
内分泌专科生信数据库的选择,应优先考虑:
- 表型是否明确。
- 临床信息是否完整。
- 是否便于联合分析。
- 是否支持外部验证。
- 是否有足够的创新空间。
如果你是做毕业、申博或高分文章,建议优先选择可形成完整分析闭环的数据。这样从筛选、建模到验证,逻辑更顺,审稿质疑也更少。
5. 解螺旋视角:把数据库选型变成可执行方案
内分泌专科生信数据库选型,本质上是把“选题”变成“可落地的分析路线”。如果前期调研不到位,后面再好的算法也很难补救。
最省时间的做法,是先用数据库筛出可分析、可验证、可扩展的题目,再进入正式建模。
在这个环节,解螺旋可以帮助你完成数据库调研、数据清洗思路梳理、分析框架搭建和题目个性化设计。这样你不用在海量数据库里反复试错,也能更快锁定适合内分泌方向的高质量项目。
总结Conclusion
内分泌专科生信数据库怎么选,关键看三点。第一,表型是否清晰。第二,是否支持多维联合。第三,是否具备可复现和可扩展能力。
只要围绕这3个指标筛选,数据库选型就不会盲目,后续的差异分析、网络构建和临床验证也会更顺畅。
如果你正在做内分泌方向课题,想少走弯路,可以借助解螺旋做前期数据库筛选和研究设计,让项目从一开始就建立在更稳的证据基础上。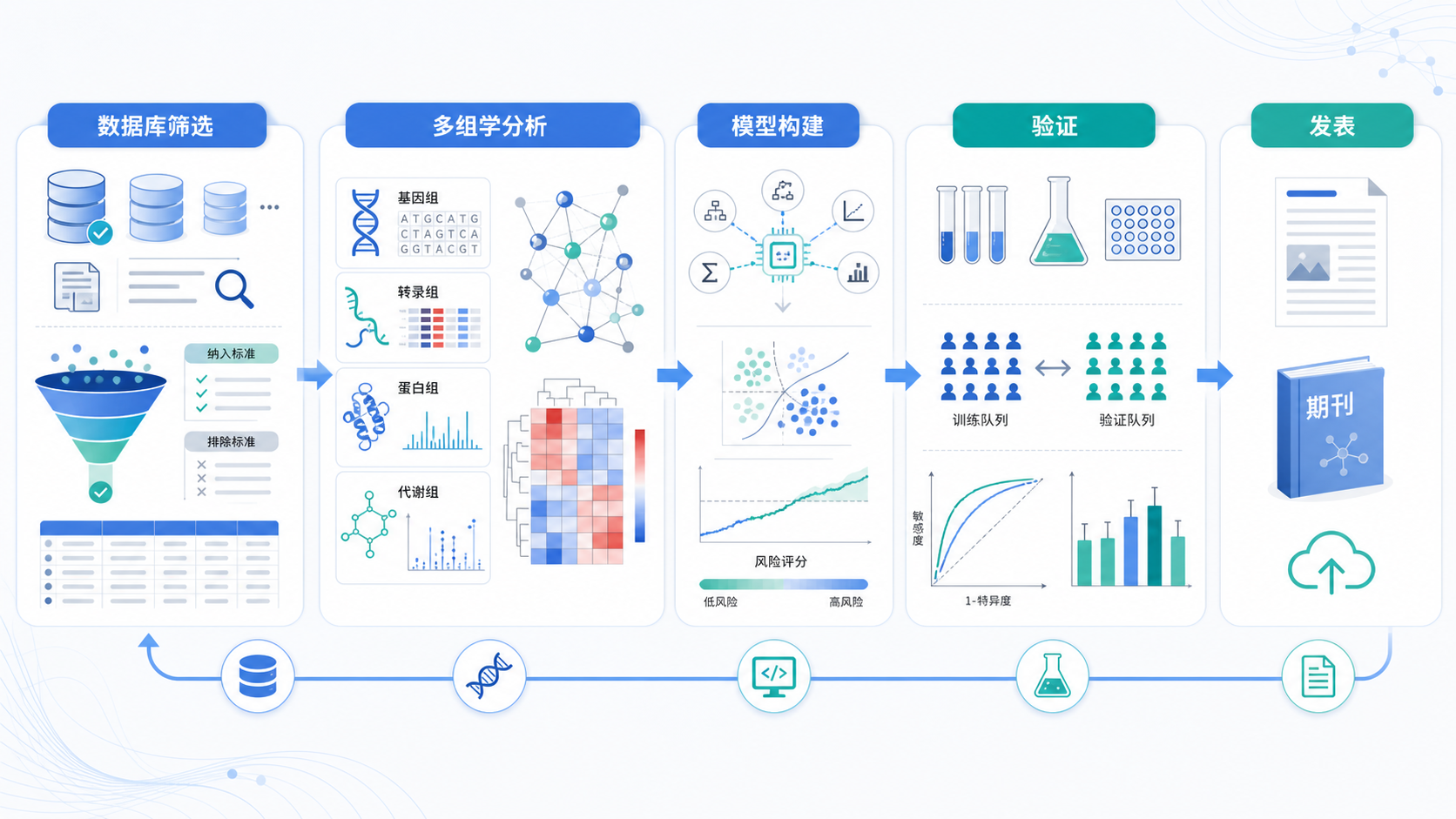
- 引言Introduction
- 1. 先看数据库是否支持“内分泌表型”匹配
- 2. 再看数据库是否“能联合”,而不是单点分析
- 3. 最后看数据库是否适合“复现”和“扩展”
- 4. 内分泌专科生信数据库的实用筛选顺序
- 5. 解螺旋视角:把数据库选型变成可执行方案
- 总结Conclusion



