






引言Introduction
面对转录组、芯片或GEO数据时,很多医学生和科研人员都会卡在第一步。表达数据库怎么选,直接影响后续差异分析、质检、归一化和结果可信度。
1. 先看数据来源是否匹配研究目的
1.1 数据来源决定可用性
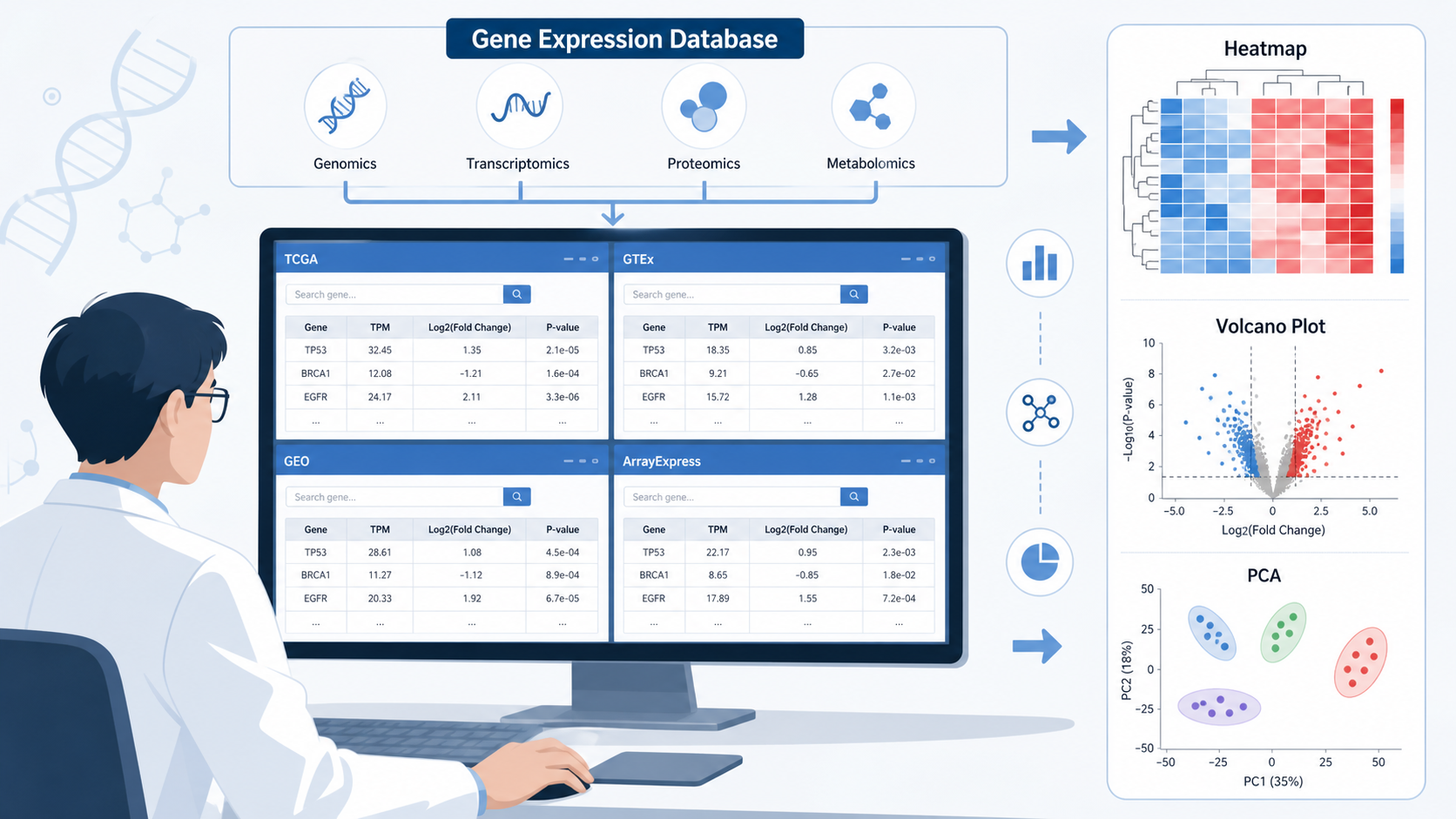
表达数据库首先要看数据来自哪里。常见来源包括自己的芯片或测序数据,以及GEO等公共数据库挖掘数据。如果研究目标是复现已发表结论,公共数据更合适。 如果目标是分析本团队样本,上传自有数据更合适。
不同数据库对数据类型支持不一样。常见输入包括带有表达值的基因列表,或完整的芯片、测序表达谱数据。以 NetworkAnalyst 为例,用户可以上传 Gene Expression Table,进入差异分析流程。
1.2 研究问题不同,数据库选择也不同
如果你只想做差异分析,重点看是否支持质检、归一化和差异基因筛选。
如果你后续还要做网络分析、功能富集、热图、火山图和Venn图,就要优先选功能更完整的表达数据库。
结论很简单。先明确你要的是“数据存储”,还是“分析入口”。 前者看收录范围,后者看流程完整度。
2. 再看数据类型是否适合你的样本
2.1 芯片和测序不能混选
表达数据库怎么选,第二个关键点是数据类型。芯片数据和测序数据的分析方法并不完全相同。
在 NetworkAnalyst 中,芯片数据常用 Limma,测序数据常用 EdgeR 或 DESeq2。如果数据库没有明确区分数据类型,后续分析容易出错。
另外,样本数也会影响方法选择。知识库明确提到,在 NetworkAnalyst 中,当样本数≥50时,不可以用 DESeq2。这个限制对大型队列很重要。
2.2 ID类型和物种支持必须提前确认
好的表达数据库,应该支持常见ID类型,并允许按物种选择。知识库中提到,NetworkAnalyst 提供17个物种选择。
如果你的数据平台不在支持范围内,可以先把基因ID转换为 Entrez ID 等常用ID,再导入分析。
这一步很关键。ID不统一,后面的差异基因、富集分析和网络分析都会失真。
3. 看质检和归一化能力够不够强
3.1 质检是判断数据库专业度的核心
真正好用的表达数据库,不只是能上传文件,还要能完成质检。常见质检包括:
- 箱线图,判断数据是否已归一化。
- 计数总和,查看每个样本的整体读取量。
- PCA,识别离群样本。
- 密度图,观察不同组的分布情况。
如果数据库不能提供这些基础质检,数据可靠性就很难保证。
3.2 归一化方法要足够灵活
表达数据库怎么选,还要看是否支持多种归一化方法。知识库中列出常见方法,包括:
- None,无处理。
- log2转换。
- 方差稳定性归一化。
- 分位数归一化。
- 分位数归一化后VSN。
对初学者来说,先用箱线图判断是否已经归一化很实用。若芯片数据 log2FC 均小于16,测序数据 log2FC 均小于20,通常提示已归一化,可选择 None。
一个合格的表达数据库,必须让用户清楚知道数据是否可直接进入差异分析。
4. 看差异分析流程是否足够规范
4.1 差异分析要有完整步骤
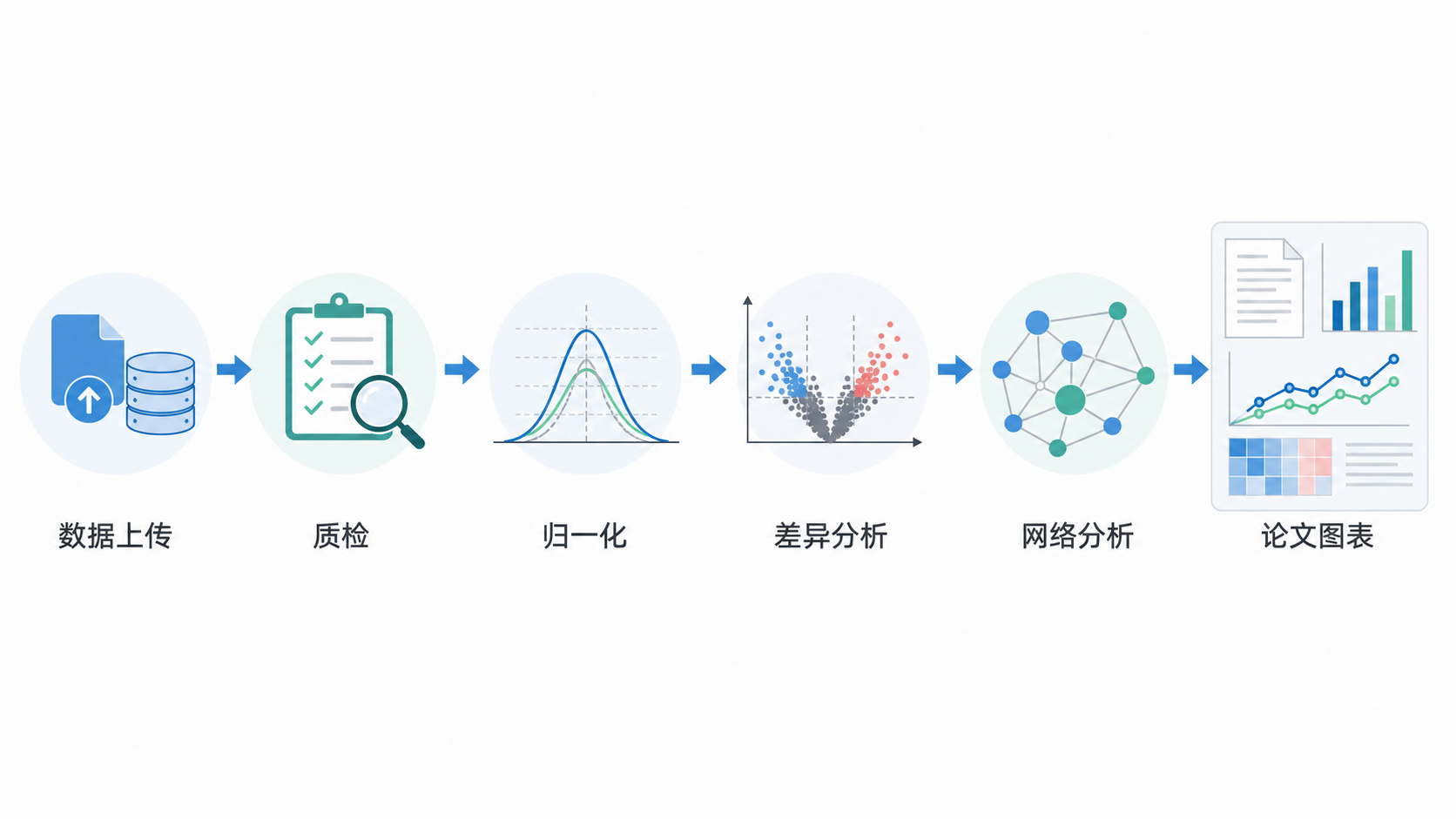
专业的表达数据库,不应该只给结果,还要能展示流程。知识库中的标准流程是:
- 上传数据。
- 质检。
- 归一化。
- 差异分析。
- 输出差异基因。
这个流程看似简单,但每一步都决定结果质量。表达数据库如果缺少任何一步,分析可重复性都会下降。
4.2 参数设置要支持真实研究场景
好的数据库,还要支持不同研究设计。比如:
- 单因素分析。
- 双因素分析。
- 阻塞因素设计。
- 配对比较。
- 时序比较。
知识库还特别提到一个常见报错:Error: No residual degrees of freedom。原因通常是样本不足,特别是独立双因素分析时。如果总组数过多、每组样本太少,模型就无法估计残差自由度。这说明数据库是否能正确处理复杂设计,是选择时的重要指标。
4.3 差异基因筛选要可控
常见筛选参数包括:
- adj P,通常设为0.05。
- log2FC。
- 按log2FC或adj P排序。
- 升序或降序查看。
能否灵活设置阈值,决定表达数据库是否适合论文级分析,而不是只适合演示。
5. 看结果输出和后续分析是否完整
5.1 结果图谱是否标准
表达数据库怎么选,最后要看能否输出科研常用图形。知识库中提到,差异分析后的常见结果包括:
- 热图。
- 火山图。
- Venn图。
- 富集分析图。
其中火山图可区分上调和下调基因,热图可展示样本分组和基因表达模式。这些图不是“附加功能”,而是论文写作的基础证据链。
5.2 是否支持进一步分析
更完整的表达数据库,通常还会支持后续网络分析和功能分析。知识库的 NetworkAnalyst 还包含:
- 网络分析。
- 功能分析。
- 转录因子互作。
- 疾病、药物或化合物网络。
- 共表达网络。
对于医学生、医生和科研人员来说,这意味着一个数据库可以从差异基因直接延伸到机制分析。这类一体化平台更适合发文和课题设计。
5.3 结果可下载、可复现更重要
选择表达数据库时,还要看是否支持下载。包括:
- 质检结果下载。
- 差异分析结果下载。
- 火山图SVG导出。
- 热图和富集结果保存。
能导出高质量文件,说明这个数据库更适合正式科研场景。
6. 选型时的实用建议
如果你刚开始接触表达数据库,建议先从示例数据入手。知识库明确建议,初次使用可先用示例数据熟悉流程,再上传自己的数据。
这样可以先理解上传格式、参数设置和结果判断逻辑,再处理真实样本。
如果你已经有明确研究目标,可以按以下顺序筛选:
- 是否支持你的数据类型。
- 是否支持你的物种和ID类型。
- 是否有质检和归一化。
- 是否支持你需要的差异分析模型。
- 是否能导出图和结果用于论文。
这套顺序比单纯比较界面好不好看更重要。
总结Conclusion
表达数据库怎么选,核心不是“哪个最热门”,而是是否满足你的研究问题、数据类型、质检要求、分析模型和结果输出。对医学生、医生和科研人员来说,一个合格的组织表达数据库,必须同时兼顾数据输入、差异分析和后续机制挖掘。
如果你希望少走弯路,可以优先选择像 NetworkAnalyst 这样流程完整、支持质检、归一化、差异分析和网络分析的平台。也可以结合解螺旋的课程与工具思路,把数据上传、参数设置和结果解读一次性理顺,提升发文效率。
选对数据库,才能把表达数据真正转化为可发表的证据。
- 引言Introduction
- 1. 先看数据来源是否匹配研究目的
- 2. 再看数据类型是否适合你的样本
- 3. 看质检和归一化能力够不够强
- 4. 看差异分析流程是否足够规范
- 5. 看结果输出和后续分析是否完整
- 6. 选型时的实用建议
- 总结Conclusion



