






引言Introduction
生物信息学数据库已经成为医学生、医生和科研人员做课题的基础工具。数据从哪里来,怎么快速找到,如何减少重复实验,都是现实痛点。如果你想用更少的样本、更高效地找到差异分子和机制线索,就必须先理解生物信息学数据库的核心作用。
1. 生物信息学数据库的核心作用之一:提供可直接分析的研究数据
1.1 补足自己实验样本不足的问题
生物信息学分析离不开数据。数据主要有两种来源,一种是自己做实验获得,另一种是从公共数据库下载。前者常见于下机数据,通常是fq等原始文件。后者往往已经整理成表达矩阵,能直接进入后续分析。
这也是生物信息学数据库最基础、最重要的作用。 它把原本分散在不同课题组、不同平台上的数据集中起来,供研究者重复利用。对于样本量有限的课题,这一点尤其关键。
例如,研究肝癌时,如果已经有公开队列可用,就不必完全从头测序。可以直接下载公共数据库中的表达矩阵,再结合自己实验数据做联合分析。这样既能节省成本,也能提高统计稳定性。
1.2 降低时间、经费和技术门槛
测序和芯片实验需要样本、经费和周期。对很多基础研究团队来说,重复做全套测序并不现实。生物信息学数据库把高成本的“数据获取”前置完成,研究者只需聚焦分析。
从流程上看,数据库中的数据已经经过一定整理。研究者可以更快完成差异分析、聚类分析和富集分析。对于论文设计来说,这意味着更短的启动时间和更高的课题推进效率。
2. 生物信息学数据库的核心作用之二:支持差异分子筛选
2.1 用标准化数据做差异分析
生物信息学分析中,第一步常常是“挑”,也就是筛选和疾病相关的差异表达分子。数据库提供的表达矩阵和表型信息,正是开展这一步的前提。
没有数据库提供的数据,差异分析就很难标准化展开。 因为数据库数据通常具备统一格式,便于比较不同组别的表达水平。常用方法包括t检验、秩和检验,以及基于表达倍数和校正P值的阈值筛选。
在实际研究中,研究者通常会同时关注log2 Fold Change和padj。这样做的意义在于,既控制差异倍数,也控制多重比较带来的假阳性。样本越多,P值越容易变小,因此单看P值不够,必须结合效应量判断。
2.2 提高差异结果的稳定性
不同算法、不同阈值,得到的差异基因数量可能不一样。但数据库能让研究者使用多个队列或多个分析包进行交叉验证。真正稳定的分子,往往是多个数据集都能重复出现的共同差异基因。
这对科研尤其重要。因为后续做机制研究、验证实验和文章发表,都需要稳定可靠的候选分子。数据库能帮助研究者从“大量候选”中筛出“高置信目标”,减少误判。
3. 生物信息学数据库的核心作用之三:帮助功能归类和通路解读
3.1 把基因放进生物学语境中理解
筛到差异基因之后,下一步不是直接下结论,而是要“圈”,也就是归类和整合。数据库在这里的作用是提供先验注释信息,帮助研究者理解这些基因是否属于同一功能模块。
富集分析就是典型应用。它通过GO、通路、分子功能等注释,把基因分组,判断它们是否集中在某些生物过程里。这一步能把“单个基因变化”上升为“通路层面的变化”。
对医学生和临床研究者来说,这比单看某个基因更有解释力。因为疾病往往不是单分子异常,而是多个分子共同参与的网络失衡。
3.2 提升文章逻辑和结果可解释性
如果只列出一组差异基因,文章往往缺少生物学故事。加入数据库后的功能分析,可以回答“这些基因为何重要”。例如,差异基因是否富集在炎症、细胞周期、代谢或免疫相关通路中。
这类结果更容易与疾病表型建立联系。也更有利于从临床问题出发,形成“数据发现——功能解释——实验验证”的完整链条。这正是高质量生信文章的基本逻辑。
4. 生物信息学数据库的核心作用之四:构建分子互作网络,寻找关键节点
4.1 发现分子之间的关系,而不是孤立看基因
生物信息学数据库不仅能做单分子检索,还能构建蛋白质-蛋白质相互作用网络,也就是PPI网络。以STRING这类数据库为代表,其核心价值在于把分散的基因连接起来,显示它们之间的功能关系。
这是数据库从“信息仓库”升级为“关系平台”的关键一步。 研究者不再只看某个基因是否上调,而是看它处在怎样的互作网络中,是否位于核心位置。
对于复杂疾病,网络分析尤其有用。因为关键基因常常不是表达最高的那个,而是网络中连接度高、位置关键的那个节点。
4.2 支持Hub基因筛选和机制挖掘
在筛到差异基因后,常见做法是进一步构建网络并寻找Hub基因。网络中的核心节点,往往更适合作为后续实验验证对象。因为它们更可能影响多个下游过程。
数据库在这里提供了可视化和打分信息。它综合实验数据、文献挖掘、共表达、邻近关系和预测结果,帮助研究者评估相互作用的可靠性。这能显著提升候选基因筛选的效率。
如果你做的是肿瘤、炎症、代谢病或神经疾病研究,网络分析通常比单纯差异分析更容易形成机制深度。它也是很多论文从“描述型结果”走向“机制型结果”的关键一步。
5. 生物信息学数据库的核心作用之五:连接科研发现与实验验证
5.1 为后续实验提供明确方向
好的数据库不仅帮助“发现”,更帮助“验证”。在完成差异分析、富集分析和互作分析后,研究者可以基于数据库结果,优先选择最值得做实验的候选分子。
这一步非常重要。因为实验资源有限,不可能对所有基因逐个验证。数据库的价值就在于把大海捞针变成有依据的优先级排序。
例如,某个基因同时满足差异显著、位于核心网络、并且富集于疾病相关通路,那么它就更值得进入qPCR、Western blot、细胞功能实验或动物实验。
5.2 支持从数据到论文的闭环
对科研人员来说,数据库不是终点,而是桥梁。它把公开数据、课题假设和实验设计连接起来,形成完整研究闭环。特别是在单细胞、circRNA、RBP、甲基化和肿瘤药物等方向,数据库已经成为课题起点。
优秀的生信研究,通常不是“找一个数据库跑一遍”,而是“围绕问题整合多个数据库”。 这样才能把表达差异、功能富集、分子互作和实验验证串联起来。
如果你希望更系统地完成这类分析,像解螺旋这样的专业生信与科研服务平台,可以帮助你更快完成数据库检索、分析设计和结果整合,减少重复劳动,把时间更多留给课题思考和实验验证。
总结Conclusion
生物信息学数据库的5大核心作用,可以概括为:提供数据、筛选差异、解释功能、构建网络、支持验证。 它不仅是生信分析的入口,也是课题设计、机制挖掘和论文产出的基础设施。
对医学生、医生和科研人员来说,真正高效的研究,不是盲目新增实验,而是先学会用好数据库。先找数据,再做筛选,再做机制,再做验证,路径会更清晰,结果也更可靠。
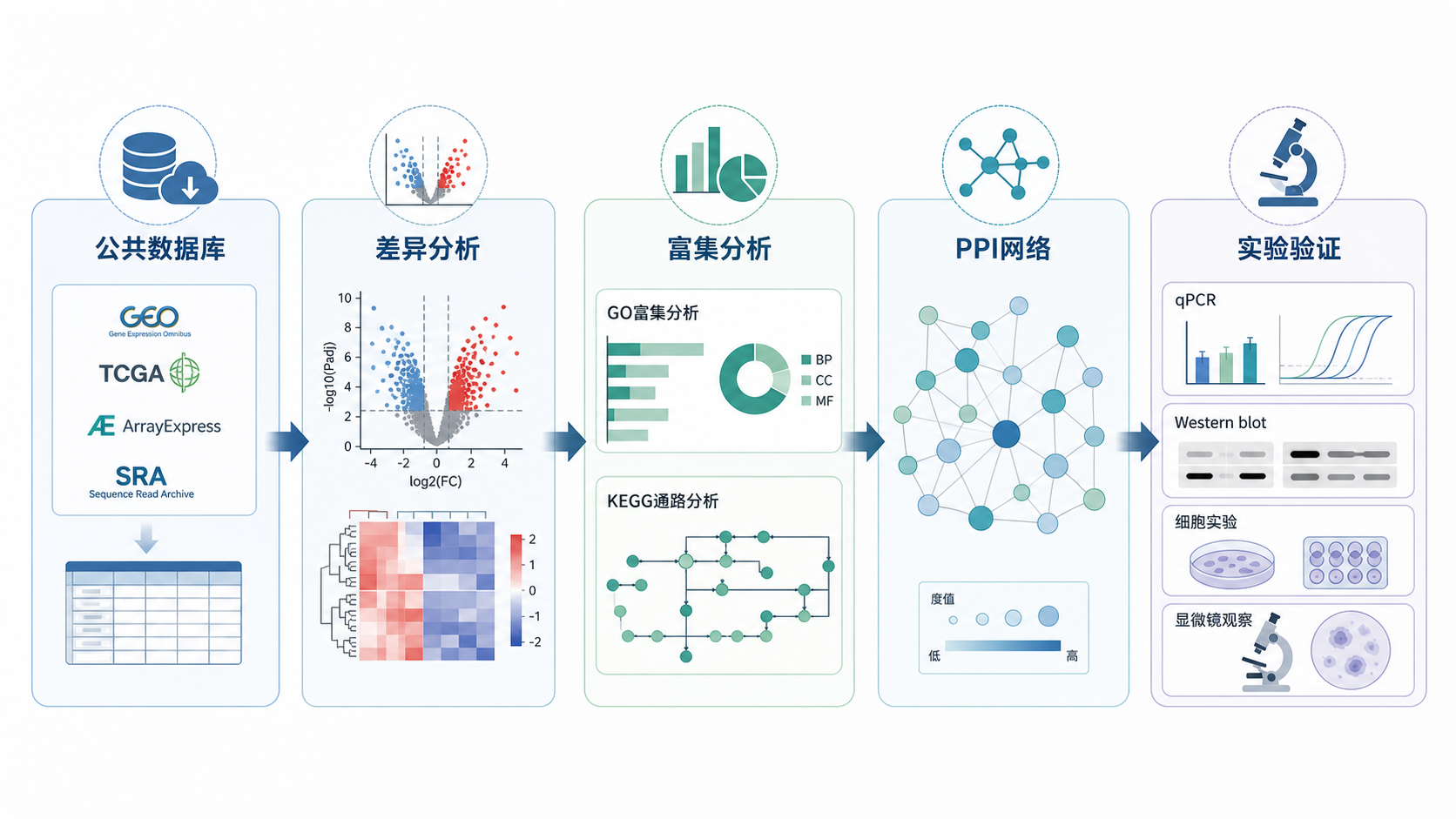
如果你正在做生物信息学数据库相关课题,想提升选题效率、分析质量和文章产出速度,可以借助解螺旋的专业支持,把数据优势真正转化为科研成果。
- 引言Introduction
- 1. 生物信息学数据库的核心作用之一:提供可直接分析的研究数据
- 2. 生物信息学数据库的核心作用之二:支持差异分子筛选
- 3. 生物信息学数据库的核心作用之三:帮助功能归类和通路解读
- 4. 生物信息学数据库的核心作用之四:构建分子互作网络,寻找关键节点
- 5. 生物信息学数据库的核心作用之五:连接科研发现与实验验证
- 总结Conclusion



