引言Introduction
做医学研究,最怕的不是没数据,而是研究设计选错,统计方法也跟着错 。医学研究设计统计的第一步,不是急着跑软件,而是先判断你做的是观察性研究还是实验性研究,再决定用队列、病例对照、横断面,还是RCT。

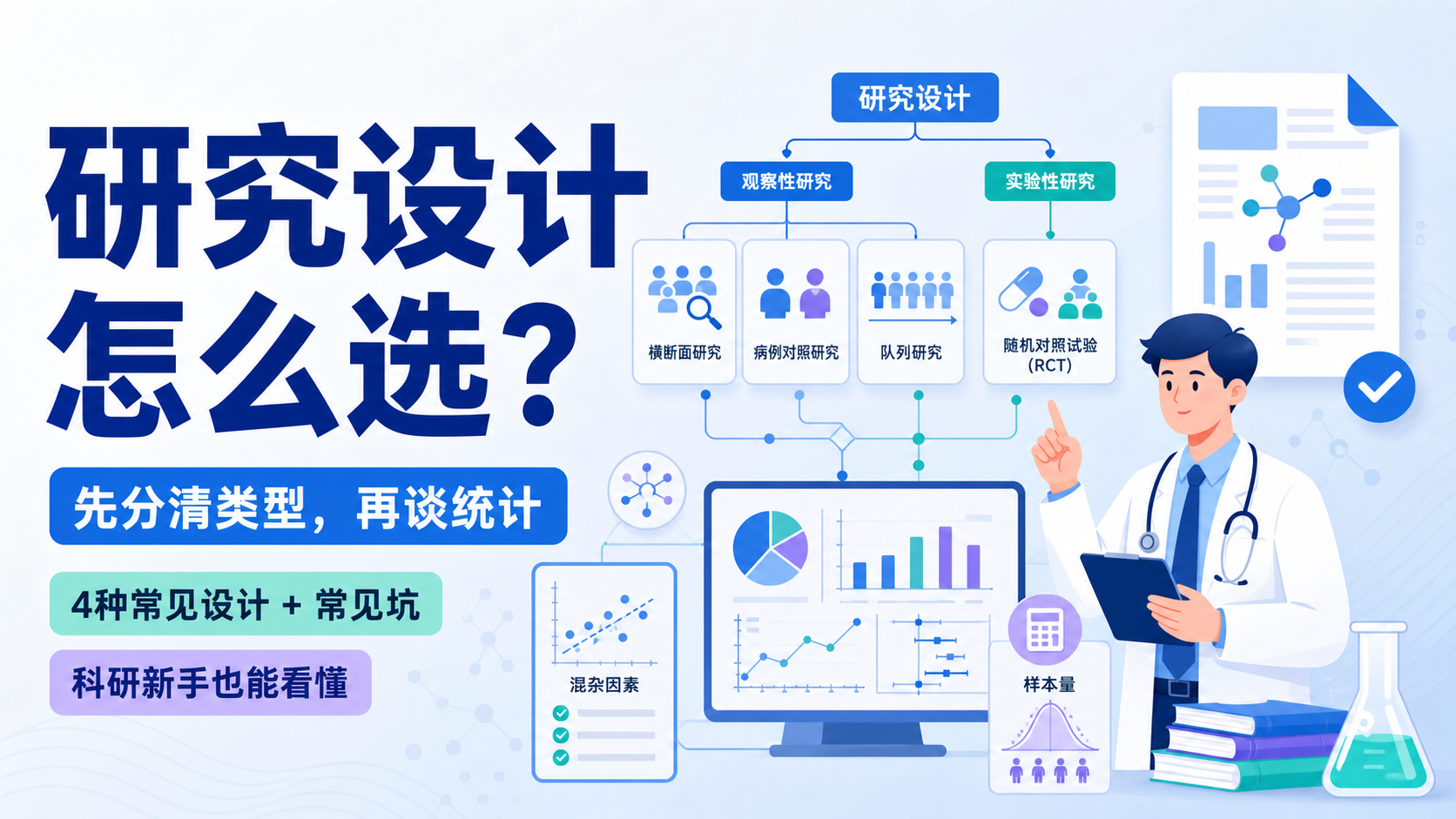
1. 先分清研究类型,再谈统计
1.1 观察性研究和实验性研究,差别很大
在临床研究里,最常见的总分法是两类。观察性研究不施加干预,实验性研究会主动干预受试者。
前者更像“站在旁边看”,后者更像“按方案做”。这个差别,会直接影响你后续的统计选择。
观察性研究里,常见的有横断面研究、病例对照研究、队列研究。比如你回顾门诊一年数据,统计肺癌患者数量和构成比,这类更偏描述。
如果你要追踪某个指标和结局的关系,就进入分析性研究。统计就不能只看均数,还要考虑比较和关联。
1.2 实验性研究更强调随机化
实验性研究最典型的是RCT。它的核心不是“我想做什么”,而是“我怎么随机分组”。
随机化能尽量平衡混杂因素,所以很多时候,统计上反而不需要太复杂的回归模型。
但实验设计一旦做错,后面的统计再漂亮也救不回来。比如把“按中心分组”当成随机分组,这在方法学上就不对。
随机化对象应该是受试者,不是医院中心。
2. 4种常见设计,怎么选
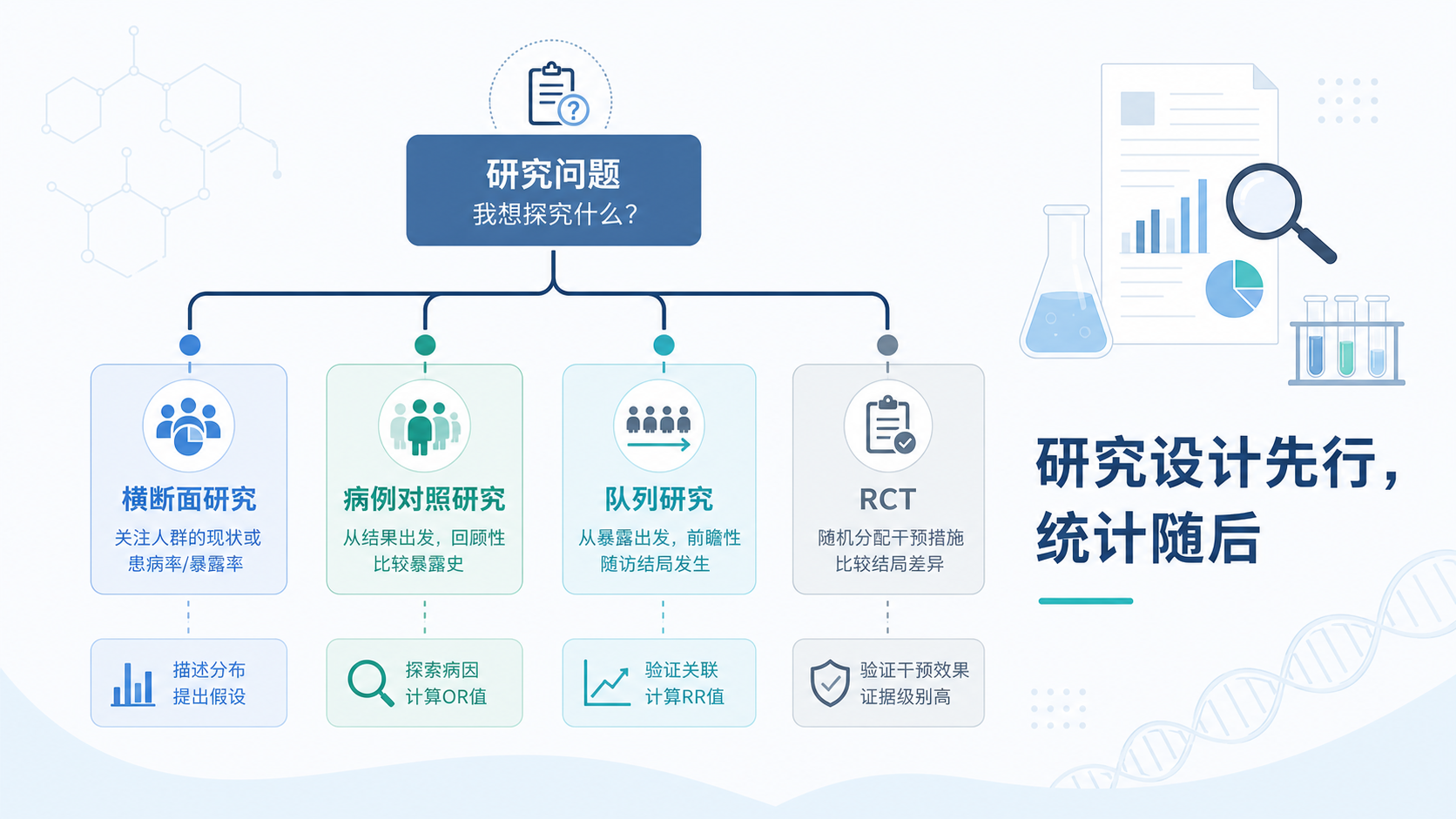
2.1 横断面研究,适合“现在有多少”
横断面研究像拍一张照片。你在同一时间点收集数据,看疾病分布、暴露情况、指标水平。
它最适合回答“有多少”“是什么样”,比如某院一年内糖尿病并发症的构成比。
统计上,横断面研究常见的是描述性统计和率的比较。
如果变量是连续型,可以算均数、中位数、标准差。
如果是分类变量,就看频数、构成比,再做卡方检验或Fisher精确概率法。
它的优点是快,缺点是难判断因果。
所以横断面研究适合摸底,不适合轻易下“因果结论”。
2.2 病例对照研究,适合“为什么会得病”
病例对照研究是先看结局,再回溯暴露。比如先找肺癌患者,再找没有肺癌的人作对照,回头比较吸烟史。
这类设计适合研究病因,尤其适合罕见病。
统计上常见的是两组分类资料比较。
你比较的是暴露因素在病例组和对照组中的差异,常用卡方检验。
如果样本量小、理论频数不足,就要考虑Fisher精确概率法。
它的关键词是“先有病,再追原因”。
所以做这类研究时,要特别注意混杂因素。随机化做不到,就要靠限制、配对、分层,或者多因素分析来处理。
2.3 队列研究,适合“谁的预后更好”
队列研究是先按暴露分组,再向后看结局。
比如按是否吸烟分组,随访肺癌发生率。临床上也常做回顾性队列,用既往病历资料追踪预后。
这类设计很适合做预后研究。如果你关心“某个指标高不高,会不会影响未来结局”,队列研究通常是很合适的。
它比病例对照更接近时间顺序,也更容易回答“暴露在前,结局在后”。
统计上,二分类结局可比较率。
如果要看生存时间,就会用生存分析,比如log-rank检验、Cox回归。
如果结局是连续变量,就看均数变化,必要时做重复测量分析。
2.4 RCT,适合“这个治疗到底有没有用”
RCT是临床干预研究的金标准之一。
它的强项是随机分组,能减少混杂,特别适合评价疗效。
如果你研究的是药物、器械、手术方案或干预措施,RCT通常是最有说服力的设计。
但它对伦理、样本量、盲法、执行一致性要求都更高。
统计方法通常相对直接。
二分类结局用卡方检验,连续结局用t检验或方差分析。
如果有时间结局,就用Kaplan-Meier和log-rank检验。
如果有亚组分析,还要看交互作用。
3. 统计方法怎么跟设计对上号
3.1 先看变量类型,再看组数
医学研究设计统计最常见的误区,就是上来就问“该用t检验还是卡方”。
其实应该反过来。先看你的研究设计,再看变量类型,再看组数和是否配对。
简单记忆如下。
- 连续变量 ,先看分布,再决定用均数、标准差,还是中位数、四分位数。
- 分类变量 ,看频数、构成比、率。
- 两组独立样本 ,常见t检验或卡方检验。
- 配对资料 ,要用配对t检验或配对卡方思路。
- 多组比较 ,常见方差分析。
- 重复测量 ,用重复测量方差分析或更合适的混合模型。
3.2 混杂因素不是靠“祈祷”解决的
很多初学者一看到结果不显著,就开始怀疑样本量。
其实更常见的问题是混杂因素没处理好。
可以用的办法包括:
- 随机化分组。
- 限制纳入标准。
- 配对设计。
- 分层分析。
- 多因素分析。
如果分组不随机,或者基线不平衡,统计模型就要承担更多校正任务。
这也是为什么研究设计决定统计,统计不能替代设计。
4. 4个常见坑,很多人都踩过
4.1 把“描述”当“因果”
横断面研究只能说明当前状态。
你可以说某指标和疾病相关,但不能轻易说它导致了疾病。
描述性研究不能替代因果推断。
4.2 把“回顾性队列”写成“病例对照”
这两个最容易混。
区分关键在于:分组依据是暴露,还是结局。
按暴露分组再追踪结局,是队列。
按结局分组再回头找暴露,是病例对照。
4.3 把“配对设计”当普通两组比较
配对设计不是两组独立样本。
它强调同源、同一个体前后对照,或者一一匹配。
如果你忽略配对,统计方法就会失真。
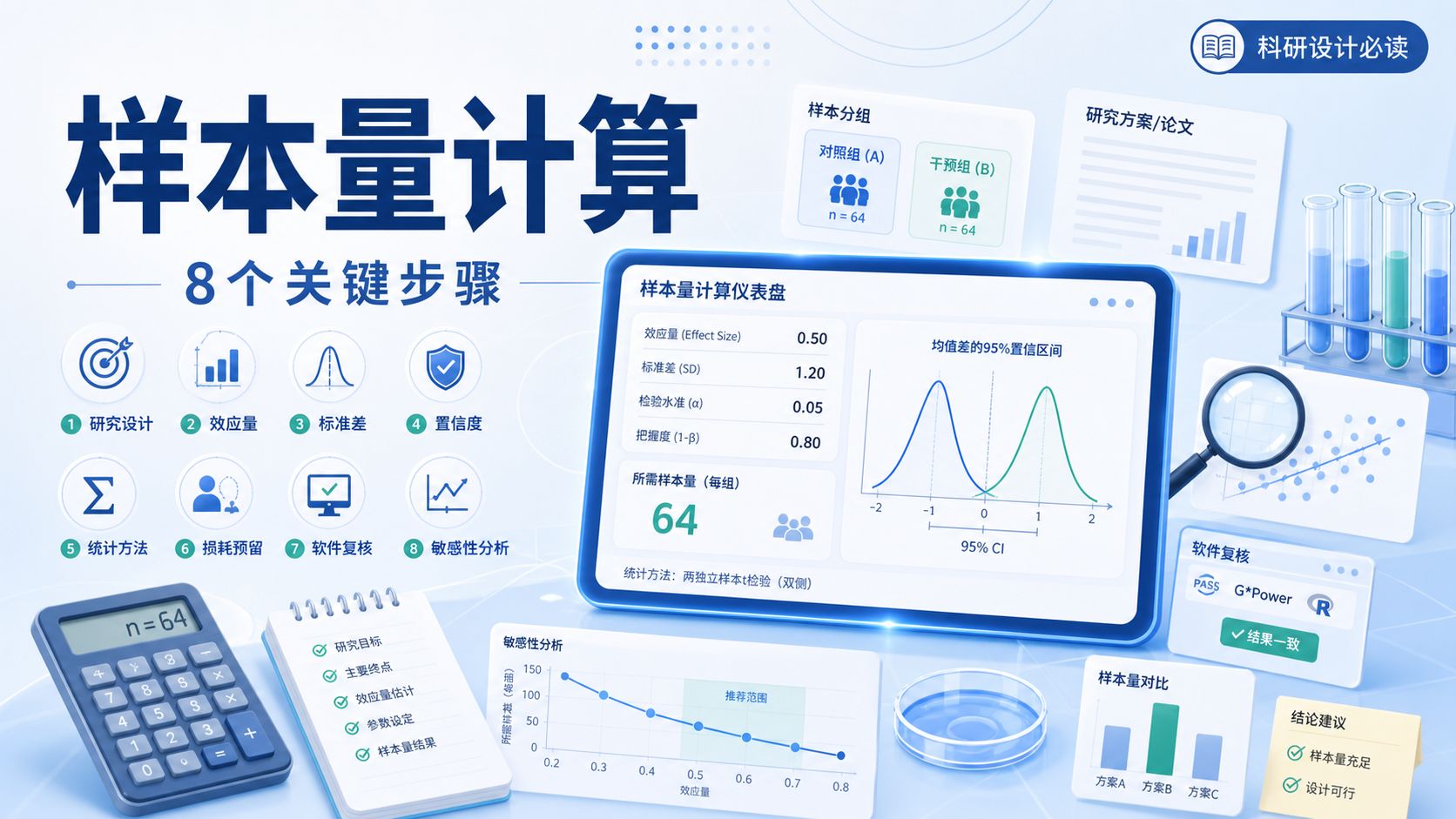
4.4 样本量和脱落率算错
一个常见错误是,先算出需要200例,再加20%写成240例。
这其实不严谨。
如果你最终想保留200例,应该反推总样本,而不是直接加法处理。
样本量计算必须和脱落率联动考虑。
5. 选型时,记住这条临床思路
5.1 先问自己三个问题
做医学研究设计统计时,先别急着打开软件,先回答三个问题:
- 你要回答的是病因、诊断、预后,还是疗效。
- 你的变量是连续、分类,还是时间结局。
- 你的分组方式是独立、配对,还是重复测量。
这三个问题一旦清楚,设计就不会乱。
设计清楚了,统计方法通常也就顺了。
5.2 适合科研新手的实用路径
如果你是医学生、规培医生或刚起步的科研人员,建议优先考虑两条路。
一条是病例对照,适合找病因线索。
一条是回顾性队列,适合做预后分析。
这两类通常比RCT更容易启动,也更容易在真实临床中找到数据。
但别忘了,容易做不等于容易发。
创新点、临床问题、数据质量,仍然是决定结果的关键。
总结Conclusion
医学研究设计统计不是“先统计,后设计”,而是先设计,后统计 。
横断面看现状,病例对照找病因,队列看预后,RCT评疗效。把设计选对,统计方法就有了正确起点。
如果你想少走弯路,可以从临床问题出发,先把研究类型、变量类型、混杂控制方法梳理清楚,再进入统计分析。这也是解螺旋一直强调的科研路径。
当你把设计和统计真正对上号,论文质量、答辩效率和投稿成功率都会更稳。
- 引言Introduction
- 1. 先分清研究类型,再谈统计
- 2. 4种常见设计,怎么选
- 3. 统计方法怎么跟设计对上号
- 4. 4个常见坑,很多人都踩过
- 5. 选型时,记住这条临床思路
- 总结Conclusion