引言Introduction
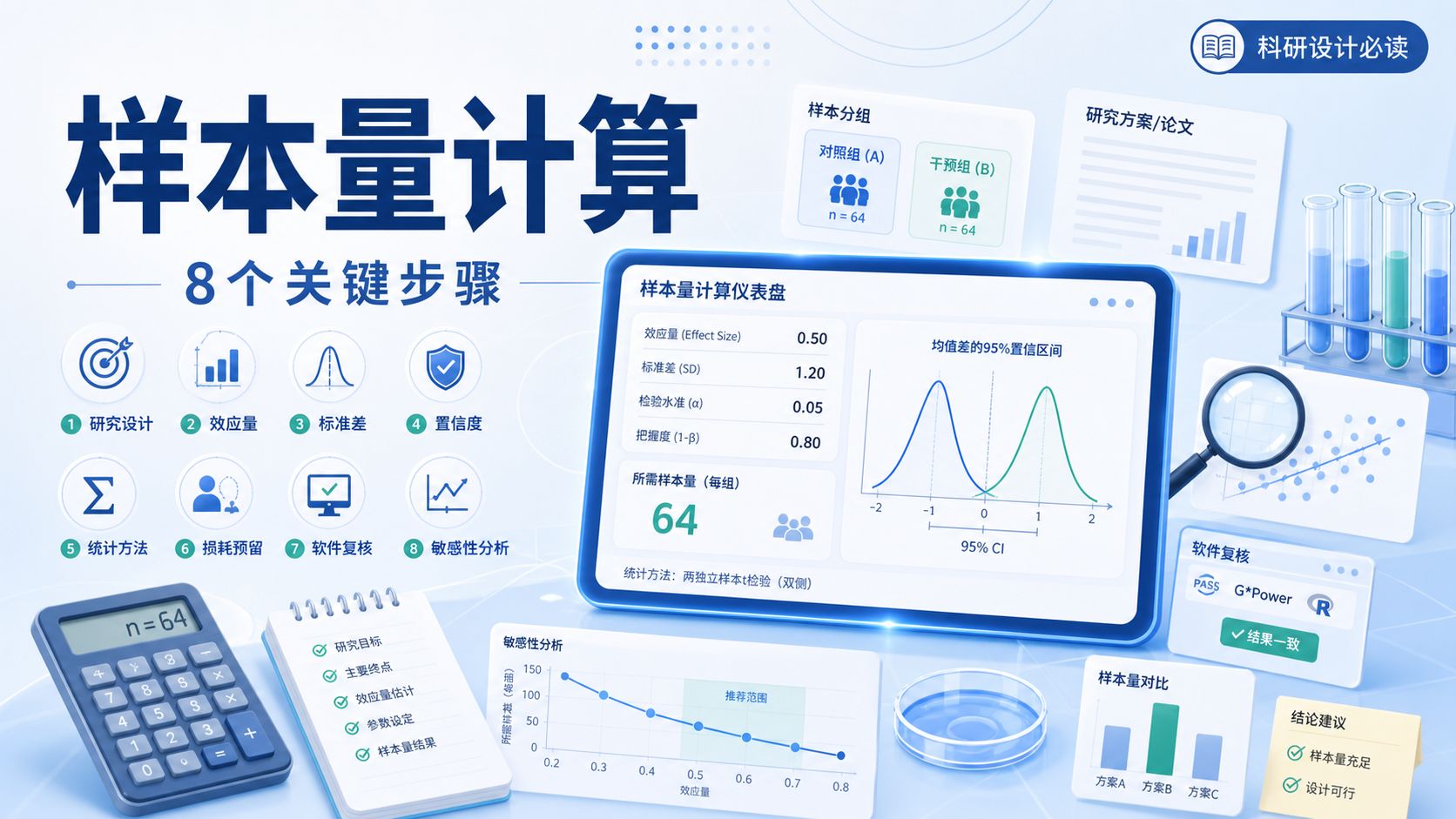
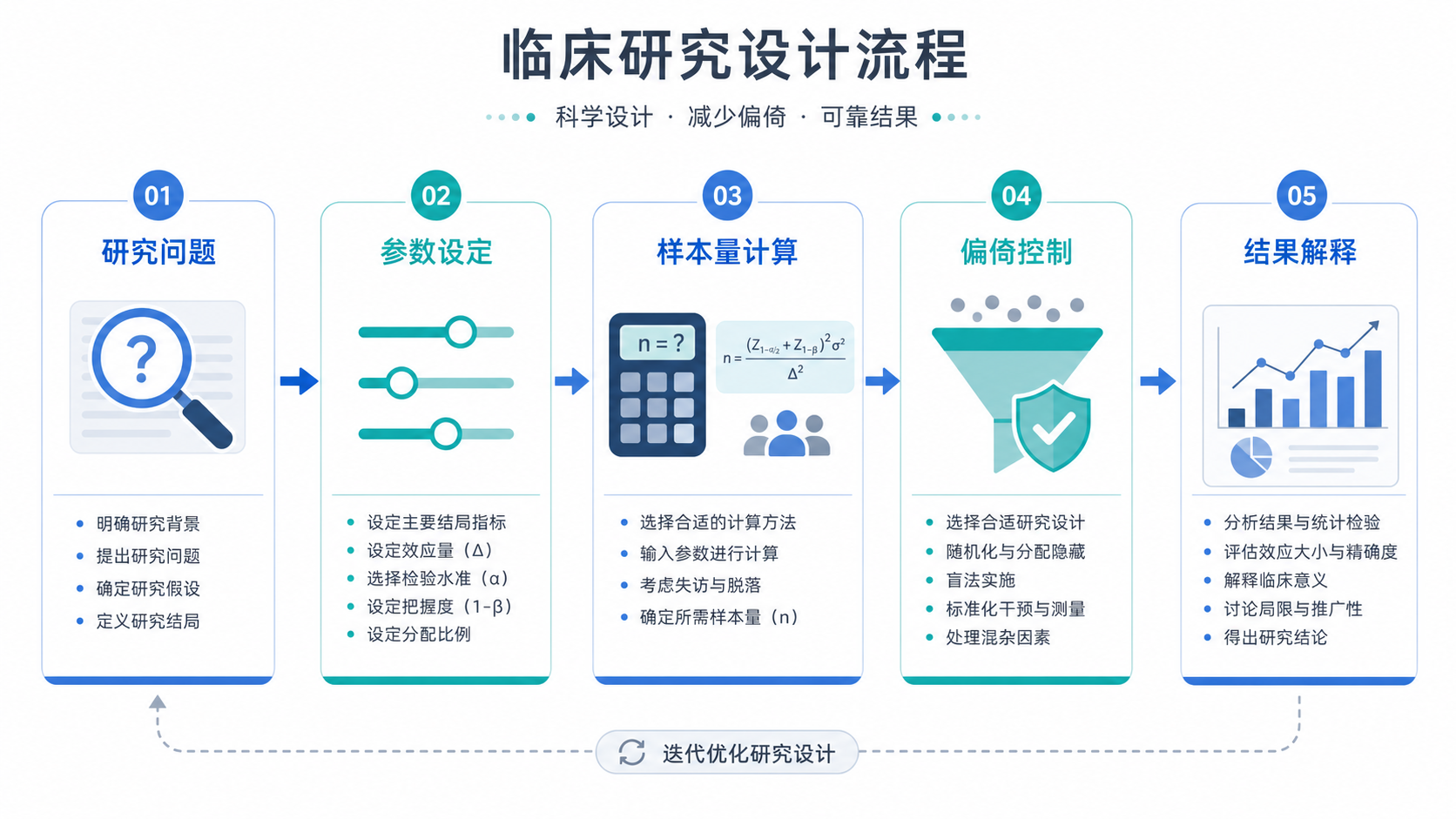
样本量算得不对,研究就可能偏倚,结论也会失真。对医学生、医生和科研人员来说,样本量计算偏倚控制 不是附加题,而是研究设计的起点。本文用7步讲清楚,如何从参数设定到软件计算,尽量把误差压到可接受范围内。
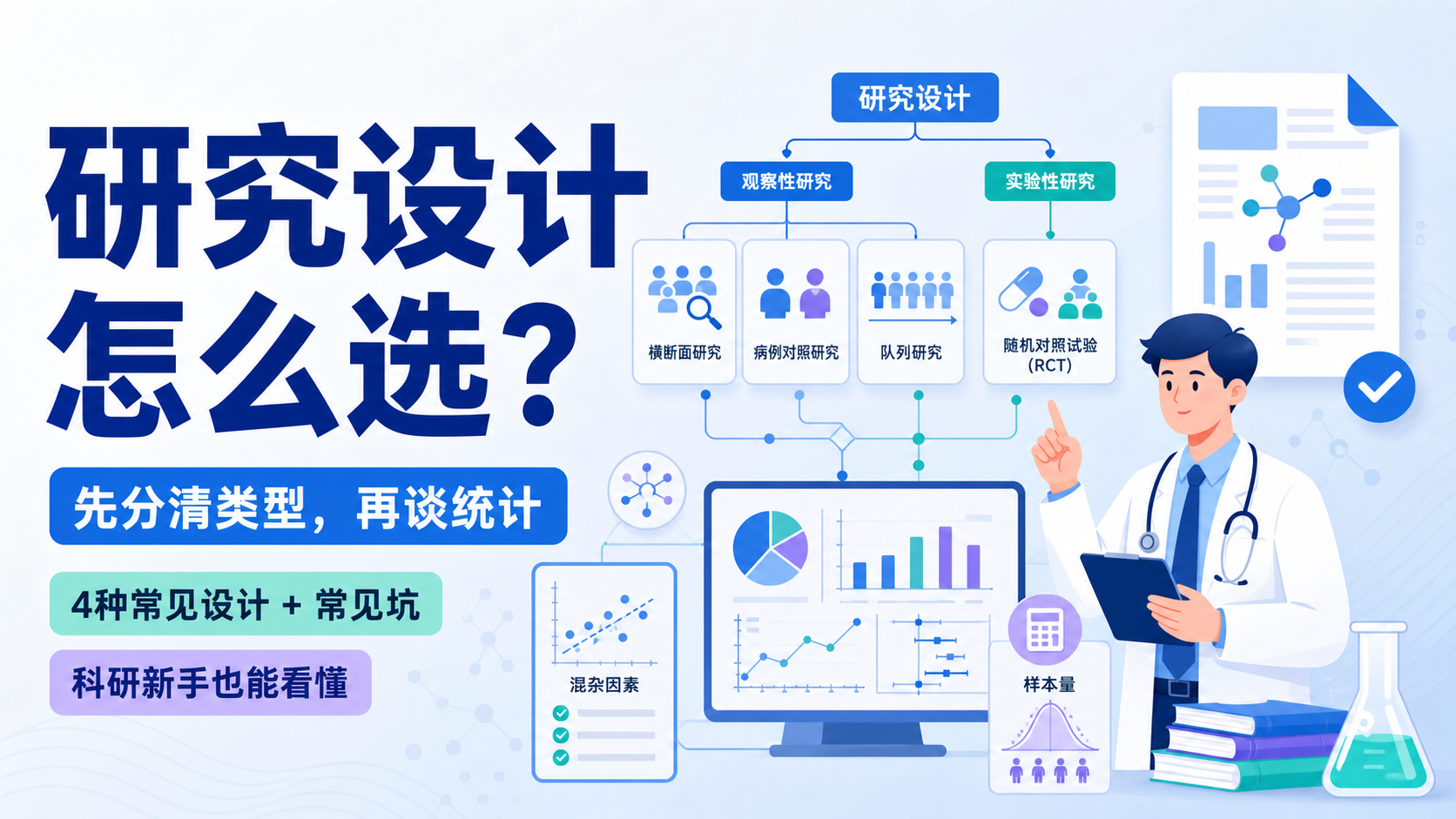
1. 先明确研究类型,再谈样本量
1.1 不同设计,参数逻辑不同
基础设计类型常见于横断面研究、病例-对照研究、队列研究等。不同设计对应的结局类型不同,样本量计算思路也不同。先定设计,再定公式,是样本量计算偏倚控制的第一步。
横断面研究里,若结局是分类变量,通常围绕总体率或患病率估计;若是计量变量,则围绕总体均数估计。病例-对照研究还要区分成组设计和配对设计。队列研究则更关注暴露组与非暴露组的结局差异。
1.2 设计不清,会直接放大偏倚
如果研究问题本身没定义清楚,后续的效应量、容许误差和检验水平均可能设错。这样得到的样本量,看似有公式支撑,实际却不满足研究目的。错误的前提,比错误的计算更危险。
2. 把效应量和容许误差定准
2.1 容许误差决定精度
在样本量计算中,容许误差越小,所需样本量越大。对计量资料,它表示样本均数与已知总体均数的最大允许误差。对计数资料,它表示样本率与已知总体率的最大允许误差。容许误差本质上是在控制精度,也是在控制偏倚风险。
知识库中给出的原则很明确。若存在专业上公认的容许误差,应优先采用。若还能通过预实验获得δ,则应比较预实验值与专业标准值,再决定最终采用哪一个。
2.2 没有标准时,按资料类型合理估计
当不存在公认容许误差时,分类资料可尝试取总体比例估计值的0.1倍或0.2倍。例如总体率预估为30%,容许误差可先取3%。计量资料的δ通常可取0.25S到0.50S。误差设得越保守,样本量越大,估计越稳。
3. 正确估计总体变异度
3.1 标准差越大,样本量越大
总体标准差反映个体差异。变异越大,研究对象越不稳定,样本量也需要相应增加。对计量资料而言,这个参数对样本量影响很大。如果标准差低估,样本量就容易被低估。
对于横断面连续变量研究,常常需要先查阅既往文献或预实验结果,估计标准差。例如知识库中提到的血清硒水平研究,就是依据既往资料中的标准差来计算样本量。这个思路适用于多数类似研究。
3.2 标准差来源要透明
建议优先采用同类人群、同类指标、同类时间窗的数据。不要拿不同地区、不同年龄层或不同检测方法的数据直接套用。否则会引入系统性误差,导致样本量计算偏倚控制 失败。
4. 设定置信度和检验框架
4.1 95%置信度是常用起点
知识库中多次使用1-α=0.95。对于常规研究,这是一种常见设置。它对应较稳妥的区间估计要求。置信度越高,样本量通常越大。
在PASS软件里,若做单总体率的置信区间估计,需要注意“Confidence Interval Width”输入的是区间总宽度,而不是单侧误差。比如容许误差为3%,区间总宽度应输入6%。这个细节很关键,输错就会直接造成样本量偏差。
4.2 置信区间宽度与误差别混淆
很多初学者会把容许误差和置信区间宽度混为一谈。前者是半宽度,后者是总宽度。这是样本量计算中最常见、也最容易被忽视的偏倚来源之一。
5. 选择合适的统计方法
5.1 不同方法,适用场景不同
在单总体率估计中,软件通常提供多种方法,如精确法、Wilson得分法、连续性校正法、简单渐近法等。知识库指出,当样本量不大时,正态近似可能不够可靠,因此Wilson区间可改善小样本下的准确性。方法选错,样本量会跟着偏。
对于单总体率,若n和n(1-p)都大于5,常可近似采用正态方法。若样本量较小或比例偏极端,则应考虑精确法或带校正方法。研究者不应只看“算得出来”,还要看“是否适用”。
5.2 小样本尤其要谨慎
小样本下,连续性校正和精确法往往更稳妥。特别是结局事件少、比例极低或极高时,简单正态近似可能低估所需样本。样本量计算偏倚控制,核心不是求快,而是求稳。
6. 把实际研究损耗纳入总样本
6.1 不能只算“理论样本”
理论样本量只是底线。真实研究中还会遇到无应答、失访、问卷不合格、标本失败等问题。知识库中给出的方法是:若无应答率为10%,则总样本量应按理论值除以0.9进行修正;若问卷合格率为90%,还需再次修正。不考虑损耗,最终有效样本往往不够。
这也是很多研究结果不稳定的原因之一。设计时样本量看似达标,真正可分析样本却缩水。样本一旦不足,置信区间会变宽,估计稳定性下降。
6.2 建议至少预留10%到20%
具体预留比例要看研究场景。门诊调查、社区调查、长期随访和多中心研究,损耗率通常不同。科研团队应结合实际流程预估。样本量计算偏倚控制,不能忽略执行层面的损耗。
7. 用软件复核,并做敏感性分析
7.1 软件只是工具,判断仍在研究者
知识库多次以PASS软件演示样本量计算。PASS适合把公式落地,但前提是参数要填对。研究者需要核对研究类型、置信度、比例或标准差、容许误差、总样本修正等。软件不会替你判断研究设计是否合理。
对于单总体率,PASS中选择对应模块后,输入置信度、区间宽度和比例,即可获得N值。对连续变量同理。成组设计、配对设计、病例-对照设计也应分别进入对应模块,避免混用。
7.2 建议做一次敏感性分析
在正式定稿前,最好对关键参数做轻度浮动测试。比如把标准差、患病率或容许误差上下调整10%,观察样本量变化。这样能判断研究方案对参数波动的敏感程度。敏感性分析是样本量计算偏倚控制的重要补充。
8. 让样本量设计更可执行
8.1 把研究资源一起纳入
样本量不是单纯的统计问题,也是执行问题。经费、人力、时间、标本保存条件,都会影响最终可纳入人数。若目标样本远超可执行上限,方案应及时调整,而不是在执行中硬扛。
8.2 借助规范工具减少重复试错
对于需要频繁进行样本量估计、参数核对和方案复算的团队,使用成熟工具能减少低级错误。解螺旋品牌可帮助研究者更高效地完成样本量计算、参数整理和方案核查,把更多时间留给研究设计与数据质量控制。 这对正在准备课题申报、论文设计和伦理申请的团队尤其有价值。
总结Conclusion
样本量计算偏倚控制,关键在于7件事:先定研究类型,再定效应量与容许误差,正确估计标准差,设置合理置信度,选对统计方法,把无应答和不合格率算进去,最后用软件复核并做敏感性分析。真正可靠的样本量,不是算得最小,而是算得最稳。
如果你正在做横断面、病例-对照或队列研究,建议把参数表、公式选择和损耗修正一次性梳理清楚。需要更高效地完成方案核查与样本量计算时,可以结合解螺旋品牌 的专业工具与服务,减少试错,提升研究设计质量。

- 引言Introduction
- 1. 先明确研究类型,再谈样本量
- 2. 把效应量和容许误差定准
- 3. 正确估计总体变异度
- 4. 设定置信度和检验框架
- 5. 选择合适的统计方法
- 6. 把实际研究损耗纳入总样本
- 7. 用软件复核,并做敏感性分析
- 8. 让样本量设计更可执行
- 总结Conclusion