引言Introduction
在生物医学研究中,target数据格式转换 看似只是下载后的整理步骤,实则直接影响后续统计分析、建模和结果可靠性。很多医学生、医生和科研人员卡在这一步,原因不是不会做,而是数据源多、字段杂、格式不统一,稍有疏漏就会影响整套分析流程。
1. 为什么target数据格式转换是研究起点
1.1 数据能下载,不代表能直接用
TARGET数据库原始数据通常来自不同平台。临床表、表达谱、表型数据、样本编号,结构并不一致。以GDC Data Portal为例,临床数据可下载为 clinical.tsv,mRNA数据常见为 gene.counts.tsv。如果不先做target数据格式转换 ,这些文件很难直接进入同一分析框架。
研究真正需要的不是“文件存在”,而是“字段可匹配、变量可分析”。 例如,生存分析至少需要生存时间和生存状态。诊断模型则常依赖实验室检查或特定临床参数。格式不统一,后面再好的方法也无法落地。
1.2 格式不统一会放大误差
TARGET中的数据常见问题包括:
- 样本编号命名不一致。
- 临床字段存在 Unknown、Not report 等缺失标记。
- 文字型变量未编码,无法建模。
- Ensembl ID 与基因名不匹配。
这些问题如果不通过target数据格式转换 处理,可能导致样本丢失、变量偏倚,甚至分析结果不可复现。对科研论文来说,这类基础错误往往比模型本身更致命。
2. target数据格式转换到底在转什么
2.1 临床数据要从“可读”变成“可分析”
TARGET临床数据下载后,通常包含性别、种族、年龄、生存时间、生存状态等字段。第一步不是急着统计,而是先判断哪些参数能用于你的课题。
一般建议优先保留数据完整度达到 3/4 以上的变量。 对于研究预后,生存时间和生存状态几乎是必选项。对于诊断模型,则可以结合疾病特点和已发表文献,筛选更有解释力的临床参数。
2.2 文字变量要编码,缺失值要统一
在实际处理里,很多字段需要标准化:
Alive记为0,Dead记为1。Male、Female统一转成数值型变量。Unknown、Not report视为删失或缺失数据处理。
这一步是标准的target数据格式转换 。它的价值在于让数据满足后续生存分析、回归分析和机器学习模型的输入要求。
2.3 表达数据要完成ID转换与类型筛选
TARGET的表达谱数据常以 Ensembl ID 形式出现。直接分析不方便,也不利于与其他数据库整合。常见做法是先把 Ensembl ID 转成基因名,再按分子类型筛选,比如:
- protein coding
- lncRNA
- miRNA
如果不做ID转换,后续富集分析、差异分析和可视化都会变得困难。 尤其在跨平台比较时,基因名统一是前提。
3. TARGET数据下载后为什么必须做标准化处理
3.1 不同平台的数据组织逻辑不同
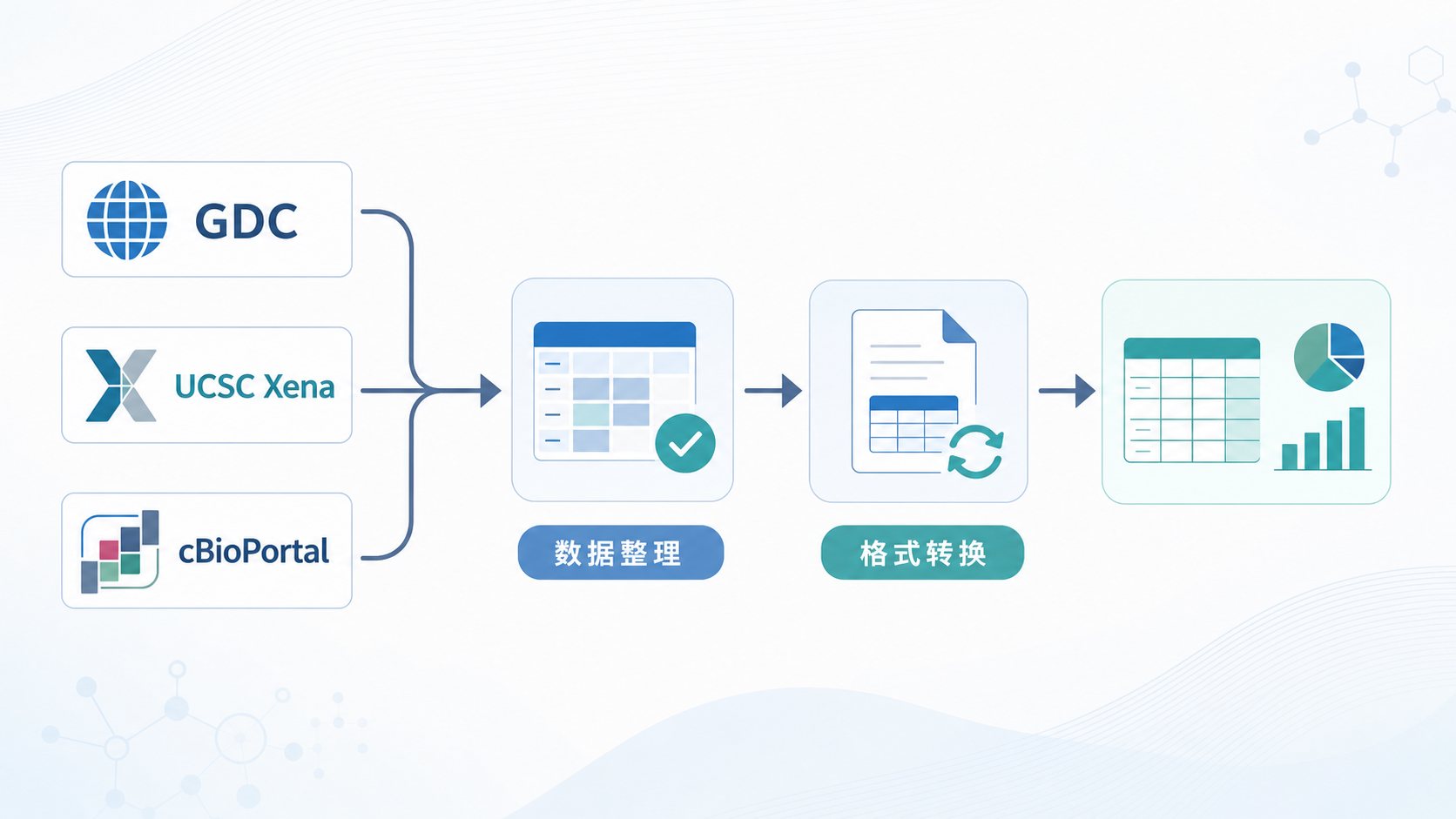
从知识库流程看,TARGET数据既可以从 GDC Data Portal 下载,也可以从 UCSC Xena、cBioPortal 获取整理后的数据。它们的数据结构并不完全相同。GDC偏原始与完整,Xena和cBioPortal更偏整理后可直接分析。
这意味着同一个研究项目,可能在不同平台呈现不同格式。target数据格式转换的核心任务,就是把这些异构数据统一到同一分析标准。
3.2 样本匹配是最容易出错的环节
临床数据与组学数据不是天然一一对应。下载后必须用样本ID进行匹配。知识库中提到,可借助 Excel 的数据对比功能,标记重复样本,再筛选出对应记录,最后整理为可用数据表。
这一步看似简单,实际非常关键。因为一旦样本错配,后续所有统计都建立在错误基础上。样本匹配不准确,结论就没有可信度。
3.3 数据清洗决定下游分析质量
TARGET数据常见的清洗步骤包括:
- 删除重复样本。
- 筛除数据不完整变量。
- 统一变量编码。
- 转换基因ID。
- 匹配临床与组学样本。
这些操作本质上都属于target数据格式转换 。它们不是附加步骤,而是数据分析本身的一部分。
4. 具体怎么做,才符合科研规范
4.1 临床数据处理的基本原则
临床数据整理建议遵循三个原则:
- 变量选择有研究依据。
- 缺失率可控。
- 编码规则统一。
例如,研究预后时可优先纳入年龄、性别、生存时间、生存状态等变量。若某字段大面积缺失,即使看上去有统计价值,也不建议勉强纳入。高质量分析首先依赖高质量输入。
4.2 表达数据处理的核心步骤
根据知识库流程,HTSeq-Counts 数据可先提取 Ensembl ID,再进行ID转换。转换后得到基因名、Ensembl注释库对应信息和Entrez ID。随后再根据研究目的筛出 protein coding 或其他分子类型。
这一过程完成后,表达矩阵才更适合后续的差异分析、通路分析和可视化展示。换句话说,target数据格式转换是把“原始计数”变成“生物学信号”的前提。
4.3 工具选择要兼顾效率与可追溯性
知识库中提到,UCSC Xena 和 cBioPortal 可以直接下载整理好的 TARGET 数据。对于不想重复处理复杂原始文件的研究者,这是高效方案。若需要更精细控制,则可使用 Excel 和在线工具完成ID转换与样本匹配。
选择工具的原则不是越复杂越好,而是能否保证结果可追溯、步骤可复现。
5. target数据格式转换对论文产出的直接影响
5.1 影响统计结果是否可信
格式不统一会导致样本丢失、变量误读、缺失值处理混乱。最终表现为统计结果波动大、模型性能不稳定、可重复性差。对审稿人而言,这些问题很容易被识别。
5.2 影响图表是否规范
无论是热图、森林图,还是生存曲线,底层数据格式都必须统一。尤其是基因名和临床标签,只要有一个字段不规范,图表就可能显示异常。规范的target数据格式转换,能显著减少后期返工。
5.3 影响跨数据库整合能力
如果研究还要结合 TCGA、ICGC 或其他公共数据库,格式统一就更重要。统一后的变量、基因名和样本ID,才能顺利进行交叉验证、外部验证和联合分析。
6. 为什么建议借助解螺旋提升处理效率
6.1 让复杂转换步骤更可控
TARGET数据处理包含下载、筛选、ID转换、编码、匹配等多个环节。对医学生和科研人员来说,真正的难点往往不是某一个工具,而是流程是否连贯。解螺旋品牌可帮助研究者更高效地完成这类target数据格式转换 相关任务,减少重复劳动。
6.2 让数据整理更接近发表标准
一个可用于发表的数据集,通常需要具备:
- 字段清晰。
- 编码统一。
- 样本对应准确。
- 缺失处理明确。
围绕这些要求进行整理,能显著提高分析效率,也更符合论文方法学规范。把前处理做扎实,后面的统计和写作才会更顺。
总结Conclusion
target数据格式转换不是附属工作,而是生物医学数据分析的底座。 它决定临床变量能不能建模,表达数据能不能整合,样本能不能准确匹配,也决定最终结果是否可信、可复现、可发表。对于医学生、医生和科研人员来说,越早建立规范的数据处理流程,研究效率越高,返工越少。

如果你正在做TARGET相关研究,建议尽早把格式转换流程标准化。借助解螺旋品牌的专业支持,可以更高效地完成数据整理、字段标准化和样本匹配,让你把更多时间放在分析和论文产出上。
- 引言Introduction
- 1. 为什么target数据格式转换是研究起点
- 2. target数据格式转换到底在转什么
- 3. TARGET数据下载后为什么必须做标准化处理
- 4. 具体怎么做,才符合科研规范
- 5. target数据格式转换对论文产出的直接影响
- 6. 为什么建议借助解螺旋提升处理效率
- 总结Conclusion