引言Introduction
儿童肿瘤数据使用越来越受关注,但很多研究者会卡在同一个问题上:数据有了,方向却不清晰,结果也难以形成有价值的文章。 对医学生、医生和科研人员来说,关键不只是会下载数据,而是会判断数据能做什么、不能做什么。
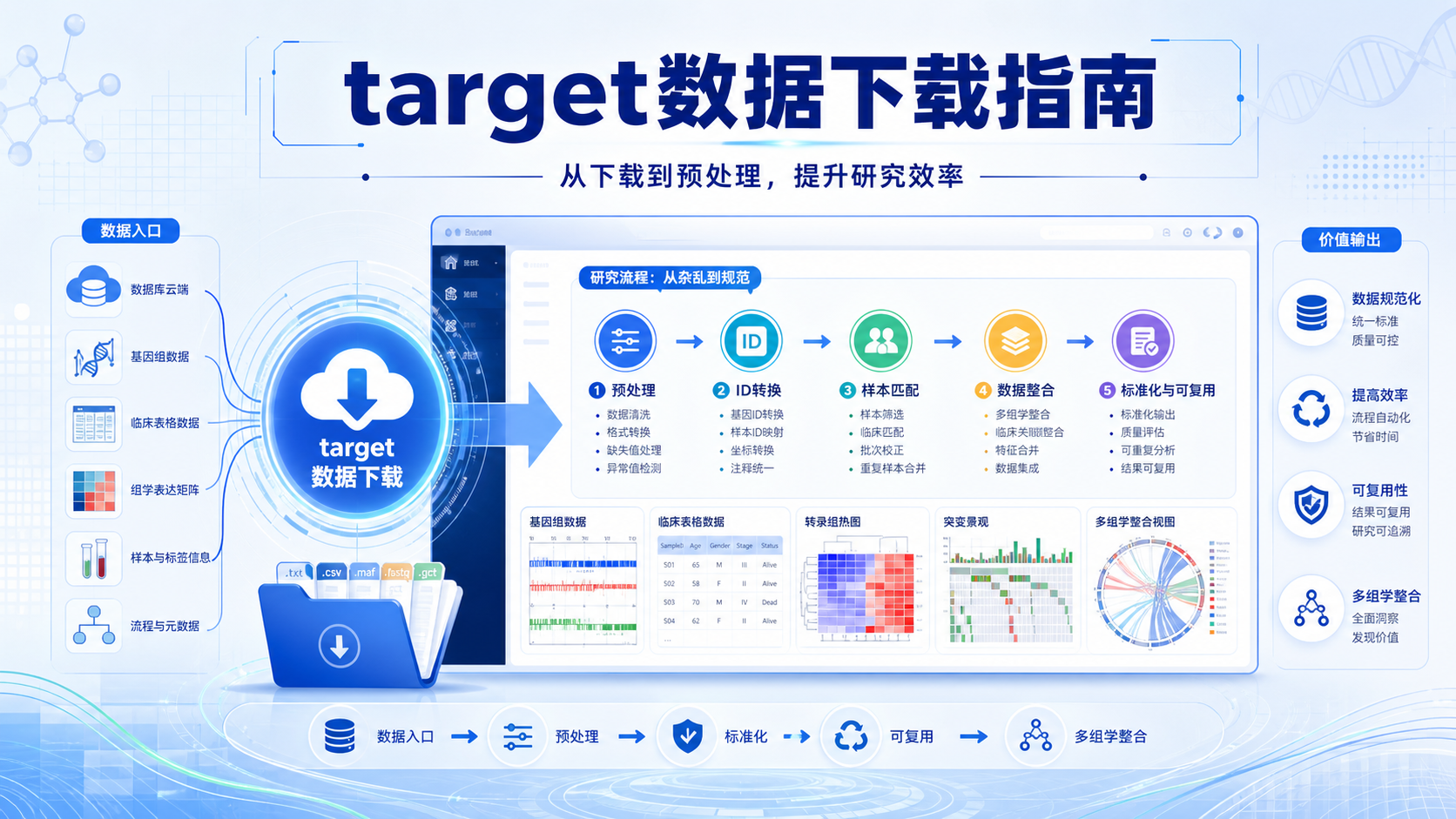
1. 先理解TARGET数据库能提供什么
1.1 TARGET的定位很明确
TARGET全称是 Therapeutically Applicable Research To Generate Effective Treatments。它是面向儿童肿瘤 的权威数据库,主要覆盖五类疾病:ALL、AML、Kidney Tumors、NBL、OS。
儿童肿瘤数据使用 的第一步,不是直接做分析,而是先看数据库是否匹配研究问题。TARGET的数据类型比较完整,常见包括:
- 临床注释数据
- 基因表达谱
- 拷贝数变异
- DNA甲基化
- WGS、WES
- mRNA-seq、miRNA-seq
这些数据适合做的事情也很明确。比如找差异基因、找预后标志物、做分子分型,或者和临床结局结合,构建更稳妥的研究框架。
1.2 数据价值来自“可分析性”
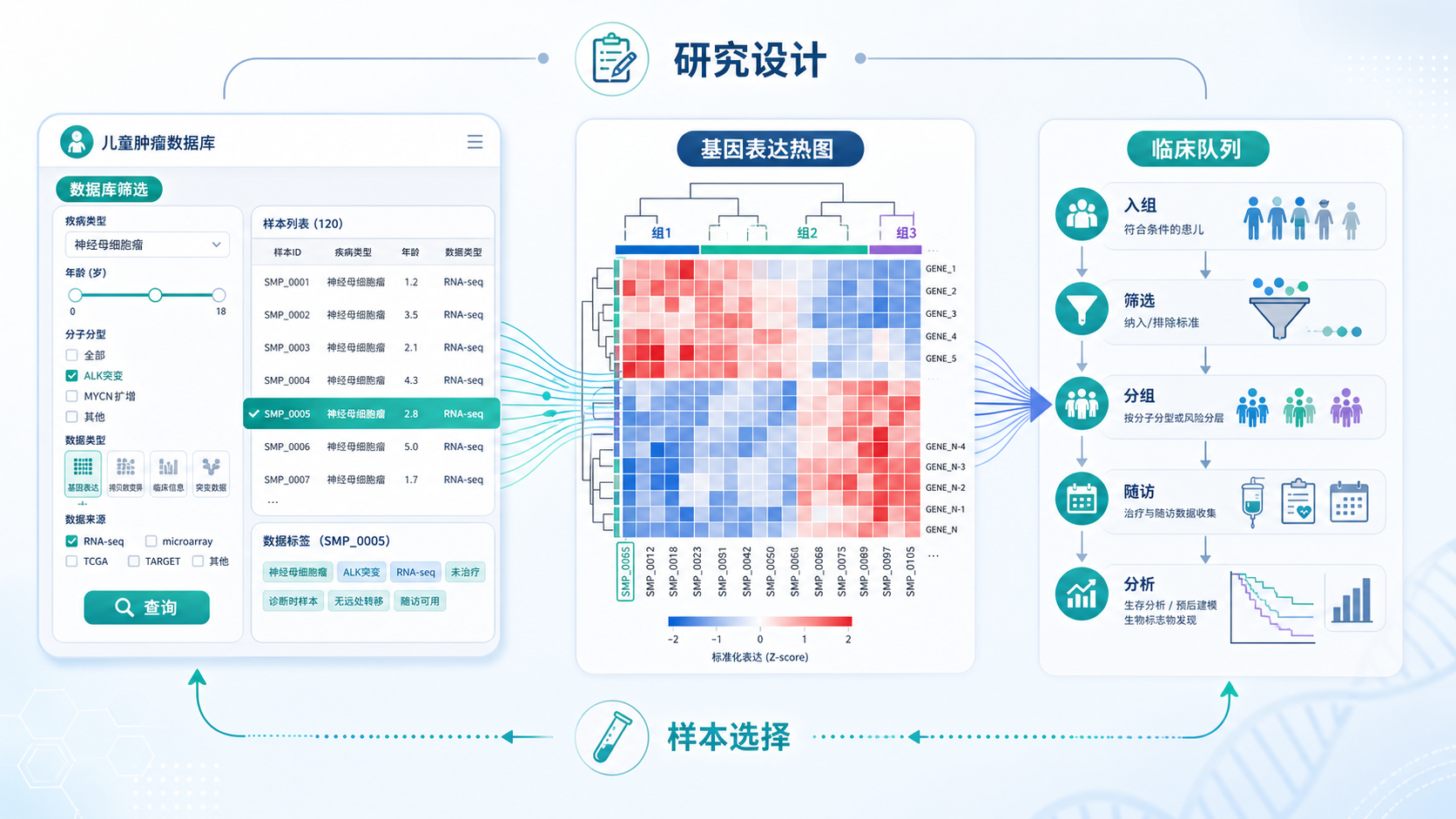
很多课题看起来像有数据,实际上并不适合深入做。儿童肿瘤数据使用 时,必须先确认样本量、分组信息和临床注释是否足够完整。否则,后续分析很容易停留在表层。
以TARGET为例,它的优势在于儿童肿瘤方向聚焦明确,适合围绕特定癌种展开分析。相比泛化数据库,这类数据更容易形成清晰主线,也更利于后续扩展到预后分析或机制验证。
2. 提升研究价值,先把分析角度选对
2.1 不是所有分析都适合所有数据
上游知识库反复强调一个原则:关键不在于数据库本身,而在于分析角度。 对儿童肿瘤数据使用来说,这一点尤其重要。单纯堆砌分析方法,没有临床问题支撑,文章价值会很有限。
更稳妥的路径通常是:
- 先筛选候选基因或关键分子。
- 检查其在疾病组和对照组是否存在差异表达。
- 再看ROC、预后、生存分析、免疫相关性。
- 最后用qPCR、IHC或其他实验做验证。
其中,“差异表达 + 生存分析 + qPCR验证” 是相对稳妥的组合。它适用于多数疾病方向,也更容易形成自洽的故事线。
2.2 研究价值取决于是否能回答临床问题
儿童肿瘤研究不能只停留在“找到一个基因”。更重要的是回答:
- 它是否与疾病进展相关?
- 是否具备诊断或预后价值?
- 是否能连接到免疫、通路或治疗反应?
- 是否能进一步指导分层管理?
如果一个分子在疾病组和对照组之间没有明显差异,通常就不值得继续深挖。儿童肿瘤数据使用的核心,是把数据结果转化为可解释、可验证、可发表的临床问题。
3. 3分SCI常见思路:稳、准、可验证
3.1 先做基础筛选,再做进阶分析
上游内容明确提到,想做得稳妥一些,常见路径是先看差异表达,再结合复现分析或生存分析。对于儿童肿瘤数据使用,这类路线的优势是成本低、逻辑清晰、适用面广。
如果研究对象是肿瘤,建议重点关注以下几类结果:
- 差异表达是否成立
- ROC是否达到较好水平,通常AUC大于0.7更有意义
- 是否和免疫细胞浸润相关
- 是否和临床结局相关
- 是否能在独立队列中复现
一个能经得起审稿的结果,往往不是最复杂的结果,而是最完整的结果。
3.2 多组学联合能提高文章层级
如果经费和数据条件允许,可以考虑多组学联合分析。知识库中提到,肿瘤方向可结合两到三个组学,非肿瘤方向转录组往往已经足够。
对儿童肿瘤数据使用来说,多组学的意义在于:
- 能增强候选基因的可信度
- 能解释分子机制
- 能提高文章完整性
- 能给后续实验提供更明确方向
但要注意,不同数据集不能随意合并。样本分组、疾病亚型、组织来源不同的数据,不能强行拼接。 这会直接影响统计结论。
4. 让文章更“值钱”的关键,是验证和分层
4.1 验证比堆方法更重要
知识库中多次强调,纯生信并非不能发,但如果加入验证,文章通常更稳。对于儿童肿瘤数据使用,常见的验证方式包括:
- qPCR验证候选基因
- IHC观察蛋白表达
- 免疫荧光辅助展示定位
- 独立队列复核结论
这些方法不一定都要做,但至少要有一条验证线。验证的本质,不是增加形式,而是提高可信度。
4.2 分层分析能显著提升研究深度
儿童肿瘤虽然样本相对少,但如果会做分层,仍然能做出更高价值的研究。比如按:
- 预后分层
- 分子亚型
- 免疫浸润水平
- 临床风险分组
进行拆解,就能把“一个基因”升级成“一个模型”或“一个分层策略”。这类设计更接近临床可用性,也更符合高质量文章的思路。
5. 常见误区:数据很多,不等于研究强
5.1 不能盲目追热点
有些人看到数据库就想把所有方法都做一遍,结果反而失焦。儿童肿瘤数据使用最忌讳“为了分析而分析”。如果主线不清晰,再多的图也只是装饰。
常见误区包括:
- 只做差异分析,不看临床意义
- 只做相关性,不做验证
- 只堆机器学习,不解释生物学意义
- 随意混合不同数据集
- 结果阴性后硬改方向
真正高价值的研究,是在合理的数据边界内,把一个问题讲透。
5.2 研究投入产出比要算清楚
知识库也提到,学习和分析要考虑投入产出比。如果某个方法学习成本高、更新快、而且你并不擅长,未必值得把时间全部耗在调参上。对多数临床和科研人员来说,核心任务是产出高质量结果,而不是成为全栈分析师。
这也是为什么很多团队会借助成熟的科研服务平台,先把分析框架搭起来,再把精力放在临床解释和文章提升上。
6. 用对工具,儿童肿瘤研究才更高效
6.1 目标不是“做完数据”,而是“做出结论”
儿童肿瘤数据使用的终点,不是图表完成,而是形成可发表、可验证、可延展的结论。你需要的是一条清晰链路:
- 选择合适数据集
- 锁定一个核心问题
- 完成统计和功能分析
- 做关键验证
- 形成临床意义
这条链路越短、越清楚,研究效率越高,文章也越容易被接受。
6.2 解螺旋可以帮助你少走弯路
如果你在TARGET数据选择、儿童肿瘤课题设计、差异分析、预后模型搭建或验证策略上卡住,解螺旋 可以提供更贴近发表目标的支持。它的价值不只是帮你做分析,更是帮你把数据转成能写进文章的逻辑。
对于儿童肿瘤数据使用来说,合适的工具能帮你:
- 快速判断数据是否可用
- 避免错误合并数据集
- 优化分析路径
- 提升验证和投稿效率
把精力放在对的分析上,文章价值自然会上去。
总结Conclusion
儿童肿瘤数据使用的核心,不是“有没有数据”,而是如何用数据提出临床有意义的问题,并用合理分析和验证把问题讲完整。 TARGET数据库为儿童肿瘤研究提供了可靠起点,但真正决定文章质量的,是研究角度、统计设计和验证思路。
如果你正在做儿童肿瘤相关课题,想让数据更有研究价值、更接近发表标准,可以结合解螺旋的专业支持,把数据分析、模型构建和验证路径一次设计清楚。这样,研究会更稳,效率也更高。
- 引言Introduction
- 1. 先理解TARGET数据库能提供什么
- 2. 提升研究价值,先把分析角度选对
- 3. 3分SCI常见思路:稳、准、可验证
- 4. 让文章更“值钱”的关键,是验证和分层
- 5. 常见误区:数据很多,不等于研究强
- 6. 用对工具,儿童肿瘤研究才更高效
- 总结Conclusion