引言Introduction
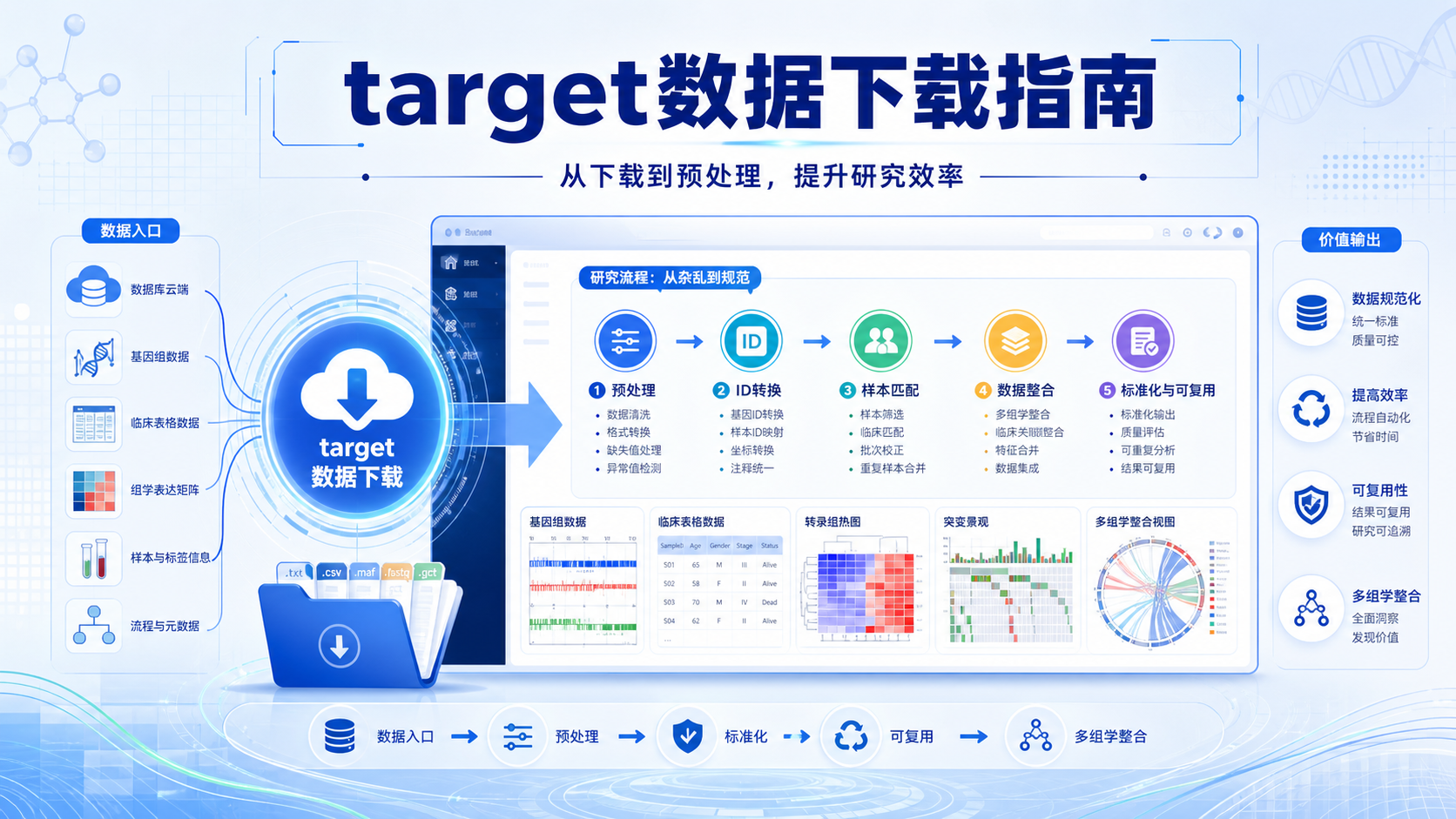
TARGET数据下载是儿童肿瘤研究中最常见的第一步,但很多人卡在“去哪下、下什么、怎么用”。如果数据来源不统一、临床字段不完整,后续分析很容易返工。理解target数据下载的逻辑,直接决定你能否快速进入可分析状态。
1. 为什么target数据下载对研究起点至关重要
1.1 数据入口决定研究效率
TARGET是面向儿童肿瘤的公开研究资源,数据类型包括临床信息、RNA-seq、miRNA、甲基化、突变等。对于医学生、医生和科研人员来说,target数据下载不是简单的取数动作,而是研究设计的入口。
如果一开始选错数据源,后续就会出现几个常见问题。
- 临床字段不全,无法做生存分析。
- 表达数据格式不统一,无法直接合并。
- 样本ID不匹配,组学和临床无法对齐。
- 原始文件太多,清洗成本大幅上升。
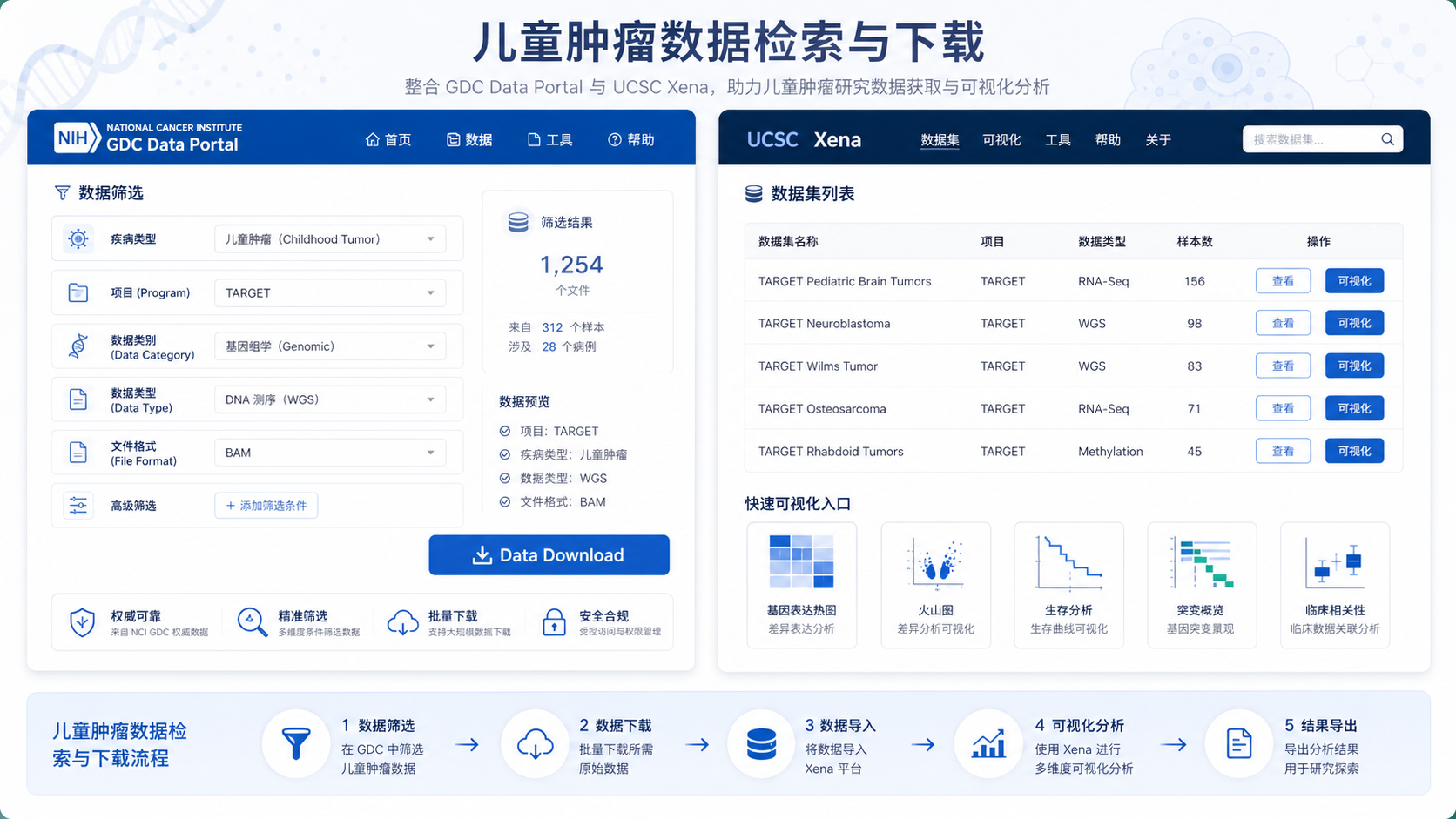
TARGET数据本身按项目组织,例如TARGET-AML。进入GDC Data Portal后,可按Project、Disease Type、Primary Site、Program、Cases、Experimental Strategy等维度筛选。这种结构化组织方式,决定了target数据下载天然适合后续做分层分析。
1.2 早期选对数据,能减少大量重复劳动
如果研究目标是预后分析,最少要保留生存时间和生存状态。如果要构建诊断模型,还需要实验室检查或其他临床变量。上游知识库已经明确提示,临床参数筛选应结合研究方向与已发表文献,并优先选择至少3/4以上数据完整的变量 。这一步非常关键。
也就是说,target数据下载的重要性,不只在于“拿到数据”,更在于“拿到能用的数据”。
2. target数据下载的核心价值:标准化、可复用、可扩展
2.1 统一来源,便于后续分析
TARGET数据可以从GDC Data Portal直接下载,也可以借助UCSC Xena和cBioPortal下载已整理数据。对于多数分析任务,优先使用已经标准化的数据集,能显著降低预处理难度。
例如,UCSC Xena中可直接获取:
- HTSeq-Counts
- HTSeq-FPKM-UQ
- Phenotype
- survival data
- miRNA表达数据
这些数据已按平台整理,适合快速进入统计分析和可视化阶段。对于需要更全面数据整合的场景,cBioPortal整合了更多TARGET相关数据类型,覆盖临床和组学信息,便于做交叉验证。
2.2 便于构建可重复的研究流程
科研最怕不可重复。target数据下载如果路径明确,数据版本清晰,后续论文复现就更容易。尤其在以下场景中,这一点非常重要。
- 多人协作时,大家可以使用同一数据源。
- 发表后复现时,可追溯原始文件和整理流程。
- 做队列扩展时,可直接复用相同筛选标准。
对于需要发表高质量论文的研究者,数据下载策略本身就是方法学的一部分。
2.3 为后续多组学整合打基础
TARGET不仅有表达谱数据,还可能包含甲基化、突变和拷贝数变异信息。下载时若先把项目、样本和数据类型选准,后面就能更自然地完成多组学整合。
这对机制研究、分型研究和预后模型建立尤其重要。
3. target数据下载后,真正的难点在预处理
3.1 临床数据不是拿来就能分析
下载clinical.tsv后,你会看到行名通常是sample,列中包含性别、种族、年龄、生存时间、生存状态等字段。问题在于,这些字段并不总是能直接用于统计软件。
常见处理包括:
- 删除或谨慎处理Unknown、Not report等缺失标记。
- 将文字型变量转为数值型变量,例如Alive转为0,Dead转为1。
- 只保留数据完整度足够高的字段。
- 依据研究主题筛选关键临床变量。
这一步决定了后续生存分析、回归分析和机器学习建模是否稳健。
3.2 组学数据要先解决ID转换
TARGET下载后的表达数据常涉及Ensembl ID。若直接进入分析,会出现注释不清、基因名混乱的问题。知识库中给出的流程很清楚:可使用仙桃学术生信工具进行简易ID转换,再结合Excel筛选protein coding、lncRNA或miRNA等类型。
标准流程通常包括:
- 提取HTSeq-Counts中的Ensembl ID。
- 转换为基因名与对应注释信息。
- 筛选目标分子类型。
- 对比原始表达矩阵并保留有效条目。
如果不做这一步,后续差异分析、富集分析和模型构建都会受到影响。
3.3 样本匹配是关键中的关键
临床数据和组学数据必须对上同一个样本。知识库明确提到,可以借助Excel对比TARGET USI进行重复标记,再筛出匹配样本。
这看似简单,但实际非常容易出错。样本不一致会导致:
- 生存信息错配。
- 表达矩阵与临床表格无法合并。
- 统计结果失真。
- 论文复现失败。
因此,target数据下载之后,样本匹配是不能省略的标准步骤。
4. 不同下载渠道,决定不同研究效率
4.1 GDC Data Portal适合获取原始数据
GDC Data Portal是TARGET数据的核心来源。适合需要更细粒度控制的研究者。你可以按项目进入,下载临床数据表和RNA-seq文件。
优点是数据来源明确,适合做严格的方法学研究。缺点是后期整理工作较多。
4.2 UCSC Xena适合快速获取整理后数据
UCSC Xena内置TCGA、ICGC、TARGET等项目数据,且提供下载功能。对于希望快速分析的人来说,它非常实用。
尤其当研究目标明确、时间紧张时,下载已整理好的Counts、FPKM-UQ、Phenotype和survival data,能显著提升效率。
4.3 cBioPortal适合做综合查看与补充分析
cBioPortal整合了大量肿瘤研究项目数据,也包含TARGET。它适合先快速浏览数据结构,再决定下载策略。对于临床与组学联合分析,它是很好的补充工具。
换句话说,target数据下载并不是只有一个入口,而是要根据研究目标选择最合适的入口。
5. 目标明确时,target数据下载能直接提升论文质量
5.1 研究问题越清晰,数据选择越精准
如果你做的是预后分析,就要优先保证生存时间、生存状态和核心临床变量完整。
如果你做的是诊断模型,就要关注样本量、分组标签和实验室指标。
如果你做的是机制研究,就要保证表达矩阵、注释信息和样本一致性。
研究问题决定数据字段,数据字段决定分析框架。
5.2 规范下载能提高结果可信度
高质量论文往往不是“分析方法更复杂”,而是起点更规范。
当你能清楚说明数据来自哪里、如何筛选、如何清洗、如何匹配,读者和审稿人会更容易信任结果。
这也是为什么target数据下载在科研流程中如此重要。它不仅影响效率,更影响可信度。
5.3 解螺旋式的数据路径更适合初学者
对于刚接触生信分析的人,最常见的问题不是不会画图,而是不知道从哪一步开始。此时,借助解螺旋这类规范化工具和流程,可以更快完成从下载到预处理的衔接。
当数据下载、ID转换、临床筛选和样本匹配都被标准化后,研究者就能把更多精力放在问题设计和结果解释上。
总结Conclusion
TARGET是儿童肿瘤研究的重要数据资源,而target数据下载之所以重要,核心在于它决定了研究是否能顺利进入可分析状态 。从GDC Data Portal到UCSC Xena,再到cBioPortal,不同平台对应不同研究需求。临床筛选、ID转换、样本匹配,这些预处理步骤都建立在正确下载的基础上。
如果你希望更高效地完成从下载到预处理的全过程,可以结合解螺旋品牌提供的规范化流程与工具,减少重复劳动,把时间留给真正有价值的分析。

- 引言Introduction
- 1. 为什么target数据下载对研究起点至关重要
- 2. target数据下载的核心价值:标准化、可复用、可扩展
- 3. target数据下载后,真正的难点在预处理
- 4. 不同下载渠道,决定不同研究效率
- 5. 目标明确时,target数据下载能直接提升论文质量
- 总结Conclusion