引言Introduction
横断面研究指标分析怎么做,是医学生、医生和科研人员最常遇到的难题。样本已收集,却不知道先看什么指标、如何分组、怎样比较、何时用Logistic回归。指标顺序不清,结果就容易写散、写偏,甚至影响投稿。

1. 先明确研究问题,再定指标框架
1.1 先分清是描述还是关联
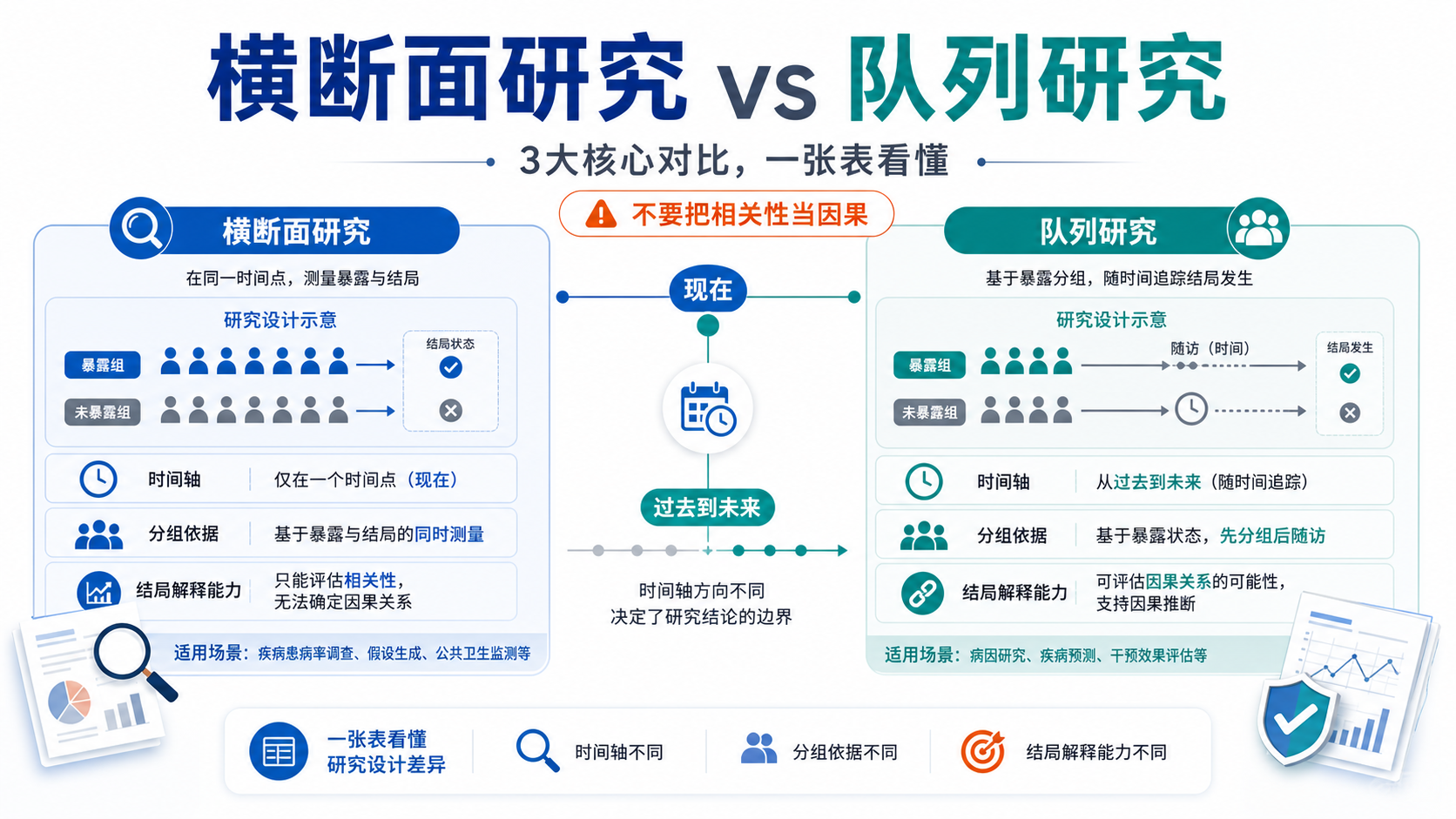
横断面研究最常见的用途有两类。一类是描述患病率、检出率和分布特征。另一类是探索暴露因素与结局的关联。横断面研究指标分析的第一步,不是跑统计,而是先定研究目的。
如果目标是描述性研究,重点看总体水平、年龄分层、性别分层、地区分布等指标。如果目标是分析性研究,就要先定义暴露变量X和结局变量Y,再看两者是否存在统计学关联。重复横断面资料也遵循这个思路,只是时间点更多,适合观察趋势变化。
1.2 先列变量,再分主次
做指标分析前,建议把变量分成三层。第一层是主要结局指标。第二层是核心暴露指标。第三层是混杂因素,如年龄、性别、BMI、吸烟、饮酒、合并症等。只有先分清主次,横断面研究指标分析才不会陷入“所有变量一起看”的混乱。
常见错误是把所有指标都当成结果。实际上,结果部分应围绕研究问题组织,而不是简单堆表。比如糖尿病研究中,患病率是核心描述指标,年龄和性别是分层指标,血糖、HbA1c、BMI可能是关联分析变量。逻辑必须清楚。
2. 计算核心指标,先把基础结果做扎实
2.1 患病率、检出率、构成比要先算清
横断面研究最基础的指标是比例类指标。常见包括患病率、检出率、阳性率和构成比。这些指标是横断面研究指标分析的地基。地基不稳,后续推断就不可靠。
写作时要明确分母。患病率一般以调查总人数为分母。检出率常用于筛查场景。构成比则用于描述某一类别在总体中的占比。需要注意的是,患病率不是发病率。横断面研究只能反映某一时点或时段的状态,不能直接说明新发风险。
2.2 分层计算更能体现价值
单纯报总体患病率,信息量有限。更有价值的做法,是按年龄、性别、地区、职业或时间分层。知识库中的做法也强调了时间、空间和人三维分布。分层后的横断面研究指标分析,才真正能看出疾病分布规律。
例如,同样是糖尿病患病率,30至39岁、40至49岁、60岁以上的差异往往很明显。若再加上南北方、城乡分层,文章的解释力会更强。对临床研究来说,这一步也能为后续干预建议提供依据。
3. 做好分组比较,找出指标差异
3.1 先看组间差异是否存在
横断面研究常把样本按是否患病、是否暴露、不同时间点或不同地区分组,再比较指标差异。组间比较是横断面研究指标分析的核心步骤之一。
如果变量是分类变量,常用卡方检验。若是连续变量,通常看t检验或非参数检验。关键不是机械套方法,而是先判断数据类型,再选择合适的统计工具。结果部分建议先报描述统计,再报检验结果,这样读者更容易理解。
3.2 注意比较的是“差异”,不是“因果”
横断面研究是同一时间点收集信息。即便发现暴露组和非暴露组差异明显,也不能直接推出因果关系。横断面研究指标分析只能提示关联,不能证明先后顺序。
这是写作时必须反复强调的边界。比如吸烟与哮喘、湿度与过敏、BMI与高血糖之间可能存在统计学关联,但仅凭横断面资料不能证明谁先谁后。能做的是提出假设,为后续队列研究或实验研究提供线索。
4. 处理混杂因素,避免结论失真
4.1 为什么不能只看单因素
横断面研究里,单因素结果常常不够。因为年龄、性别、基础疾病、生活方式等都可能影响结局。如果不控制混杂,横断面研究指标分析很容易出现假关联。
例如,高血压与BMI看似相关,但年龄可能是共同影响因素。若老年组本身BMI和高血压都更高,单因素比较就可能夸大关联。因此,在结果解读前,应先确认是否进行了分层或多变量校正。
4.2 多因素分析常用Logistic回归
当结局变量是二分类变量时,Logistic回归是横断面研究中最常见的方法。结果通常报告OR值和95%置信区间。当95%CI不跨1时,提示该关联具有统计学意义。
写作时要注意,OR值表示优势比,不等同于风险比。尤其在高患病率场景下,OR可能高估关联强度。因此,解读时应结合研究设计和结局发生率,保持谨慎。若研究对象是重复横断面数据,也可按年份分层后再做回归分析,观察指标变化趋势。
5. 规范呈现结果,让读者一眼看懂
5.1 表格顺序要符合逻辑
横断面研究结果最常见的呈现顺序是,先描述总体特征,再分层比较,最后做关联分析。表格不是越多越好,而是越有逻辑越好。
通常可按以下顺序组织。
- 基线特征表。
- 主要指标分层表。
- 组间比较表。
- 回归分析表。
如果是重复横断面研究,还可以增加不同年份的比较表,突出时间趋势。这样写,结果部分会更完整,也更符合审稿人阅读习惯。
5.2 图表要服务于结论
横断面研究中,地图、柱状图、森林图都很常用。地图适合展示地区差异。柱状图适合展示不同年龄或性别的患病率。森林图适合展示回归结果。图表的作用不是装饰,而是把横断面研究指标分析的重点可视化。
图表要避免信息过载。一个图尽量只表达一个重点。图注要写清样本量、指标定义和统计方法,减少歧义。
6. 解释结果时,紧扣研究边界
6.1 结果要和设计匹配
横断面研究的优势是快、成本低、适合大样本。局限也很明确,就是无法证明因果关系,容易受选择偏倚和信息偏倚影响。因此,横断面研究指标分析的结论必须和研究设计一致。
如果研究是描述性横断面,结论应强调“分布特征”“现况”和“差异”。如果是分析性横断面,结论应强调“相关性”“关联”和“提示意义”。不要把“相关”写成“导致”,这是常见的论文错误。
6.2 结合三间分布来写讨论
讨论部分建议围绕时间、空间、人群三条线展开。时间上看趋势变化,空间上看地区差异,人群上看年龄、性别、职业差异。这会让横断面研究指标分析更像“研究”,而不是简单“报数”。
如果是重复横断面研究,还能进一步比较不同年份的变化,增强讨论深度。比如某指标连续上升,可能提示筛查强化、人口老龄化或生活方式变化,但要避免过度解释,最好用已有文献支持。
7. 用标准化流程,提高写作和投稿效率
7.1 一套实用的7步流程
横断面研究指标分析可以按以下流程执行。
- 明确研究目的。
- 定义主要结局和暴露变量。
- 统计总体特征。
- 计算核心比例指标。
- 做分层比较。
- 进行多因素分析。
- 按结论逻辑组织表图和讨论。
只要按这7步走,横断面研究指标分析就不会乱。 这套流程适合论文初稿、结果整理和投稿前自查。
7.2 解螺旋如何帮助你少走弯路
如果你正在写横断面研究论文,最常见的痛点不是没有数据,而是不知道怎么把指标讲清楚。解螺旋可以帮你把变量框架、结果表格、统计表达和论文结构串起来,减少返工。对医学生、医生和科研人员来说,这种标准化支持能明显提升写作效率,也更利于形成可投稿的结果表达。
总结Conclusion
横断面研究指标分析,核心不是“多做统计”,而是“按研究目的选指标、按变量类型选方法、按结果逻辑选呈现”。先明确描述还是关联,再完成患病率、分层比较和回归分析,最后回到研究边界做解释。把这7步走顺,文章就更清晰,结论也更可信。
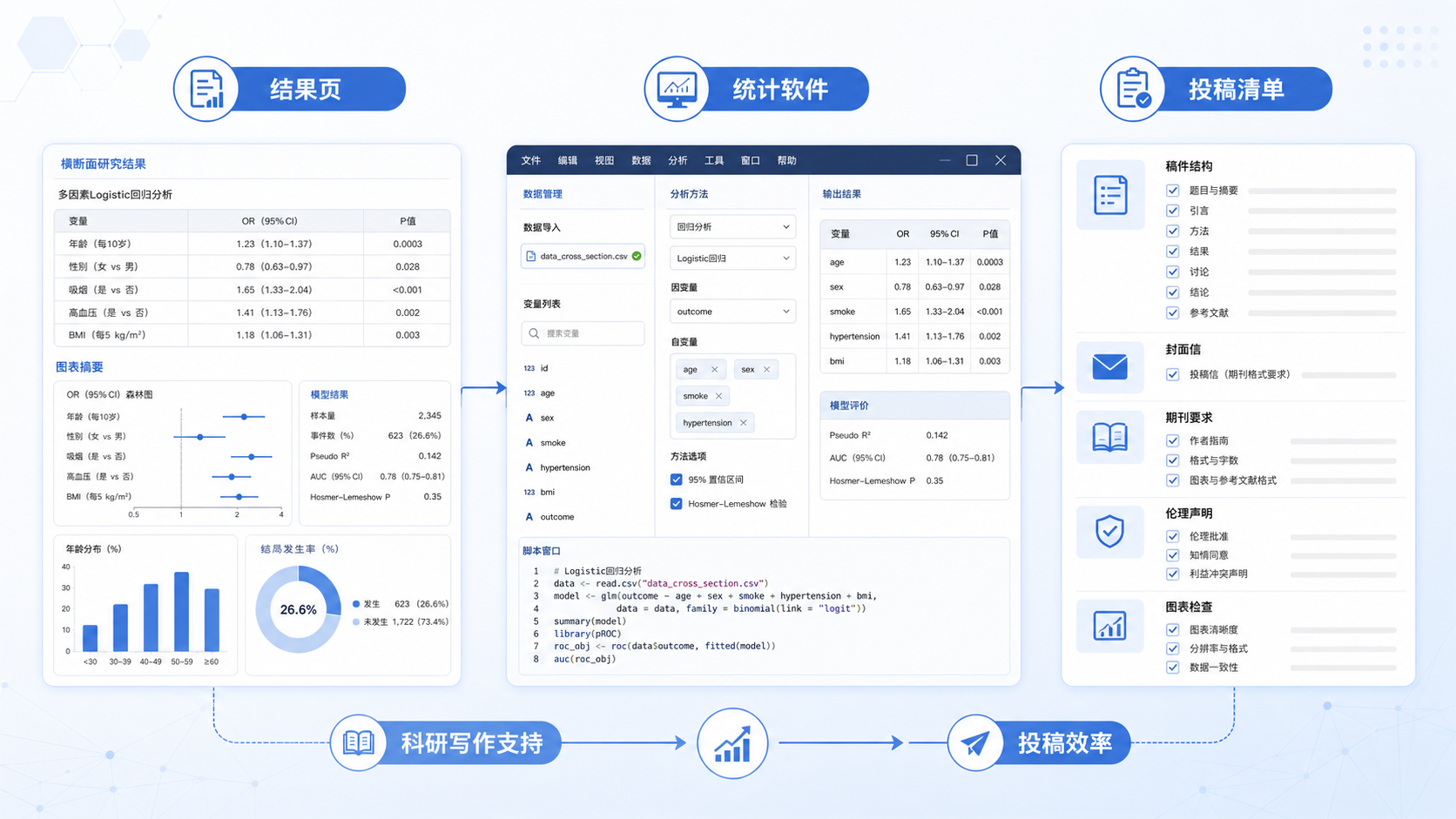
如果你希望把横断面研究指标分析真正写成一篇能投稿的论文,建议直接使用解螺旋的科研写作支持服务,从变量梳理到结果表达,一步到位。
- 引言Introduction
- 1. 先明确研究问题,再定指标框架
- 2. 计算核心指标,先把基础结果做扎实
- 3. 做好分组比较,找出指标差异
- 4. 处理混杂因素,避免结论失真
- 5. 规范呈现结果,让读者一眼看懂
- 6. 解释结果时,紧扣研究边界
- 7. 用标准化流程,提高写作和投稿效率
- 总结Conclusion