引言Introduction
横断面研究统计基础决定了结果是否可信。很多医学生和科研人员在做问卷、量表或门诊调查时,最容易忽视偏倚控制,导致相关性被高估或低估。如果抽样、测量和分析一环出错,结论就会失真。 
1. 横断面研究统计基础的核心:先理解偏倚从哪里来
1.1 横断面研究为什么容易出现系统误差
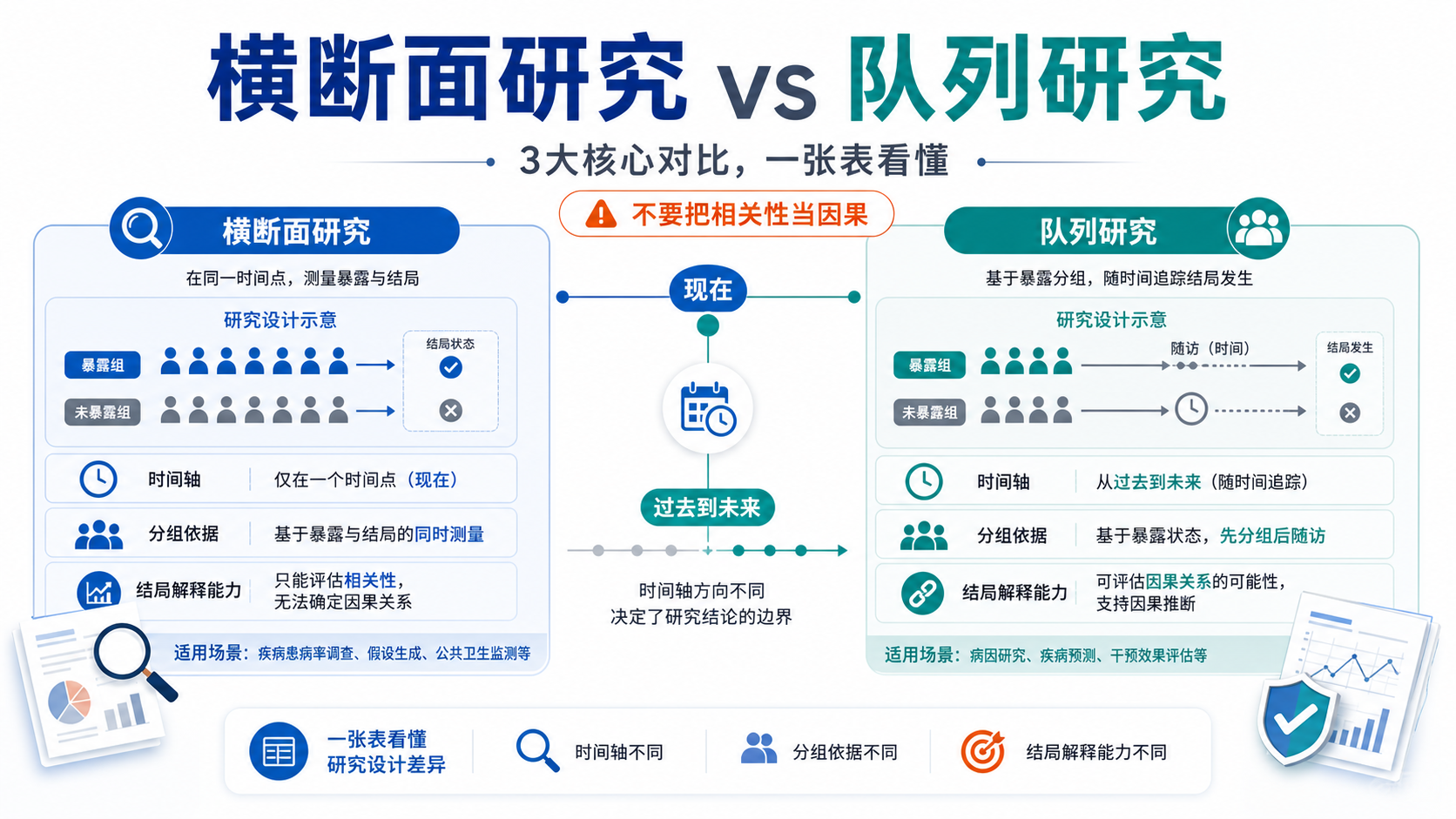
横断面研究通常在同一时间点收集暴露和结局信息。它的优点是快、成本低,适合描述患病率和探索相关性。
但正因为“同一时间点”收集信息,它天然更容易受到选择偏倚、信息偏倚和混杂偏倚影响。 这也是横断面研究统计基础中最需要掌握的部分。
在写论文或做课题时,不能只报告P值和OR值,还要说明研究对象怎么来、变量怎么测、混杂怎么控。否则结果再显著,也可能只是偏倚造成的假相关。
1.2 横断面研究最常见的4类偏倚框架
严格说,横断面研究中最常讨论的是3类偏倚。但在实操中,常会把无应答偏倚、选择偏倚、信息偏倚、混杂偏倚 分开处理,便于设计和写作。
这4类问题,基本覆盖了横断面研究统计基础中的主要风险点。
记住一个原则:抽样阶段防选择偏倚,测量阶段防信息偏倚,分析阶段防混杂偏倚,调查执行阶段防无应答偏倚。
2. 选择偏倚:样本代表性不足,结论就会偏
2.1 无应答偏倚是横断面研究里最常见的问题之一
横断面调查常见的错误,是“发了很多,回了很少”。如果发放5000份问卷,只回收2000份,应答率只有40%,那么未应答者是否与应答者不同,就会直接影响结果。
应答率越低,样本越可能偏离总体。 这会削弱研究的外推性。
写作时要报告三个数字。发放数、回收数、应答率。
如果应答率较低,还应讨论未应答者可能带来的方向性影响。这是横断面研究统计基础里很重要的报告规范。
2.2 特殊研究人群会限制外推
另一类选择偏倚来自样本特殊性。比如研究只纳入某一家三甲医院的住院患者,或者只纳入符合非常严格排除标准的人群。
这可以提高内部同质性,但也会降低代表性。研究结论未必适用于社区人群、其他医院人群,甚至不同民族或地区。
因此,横断面研究统计基础不仅是“算出结果”,还包括判断结果能不能推广。
如果研究对象限定过窄,讨论部分必须明确说明外推受限。
3. 信息偏倚:测量不准,相关性会被扭曲
3.1 回忆偏倚和报告偏倚最常见
横断面研究常用问卷和自报信息。问题在于,受试者对过去行为的记忆并不可靠。
例如,询问过去一年的饮食、睡眠、吸烟或运动情况,很多人会出现回忆不完整或选择性报告。这就是典型的信息偏倚。
如果是敏感问题,如饮酒、吸烟、体重管理失败,报告偏倚更明显。
受试者可能为了迎合社会期待而少报,导致暴露水平被低估。
3.2 测量工具不统一,会直接影响数据质量
横断面研究统计基础还要求测量一致。
如果不同调查员用不同话术提问,或者量表没有经过良好信度、效度验证,结果就会产生系统误差。
实验室指标也一样。仪器型号、校准状态、检测流程不同,都会增加测量偏差。
可操作的做法有3点。
- 使用经过验证的量表或标准化工具。
- 统一培训调查员,减少诱导性提问。
- 采用客观记录替代主观回忆,能不用问卷回忆就尽量不用。
在横断面研究中,信息偏倚往往比统计学显著性更值得警惕。
4. 混杂偏倚:看起来有关联,实际可能是第三因素在起作用
4.1 横断面研究最难直接推断因果
横断面研究的数据是同步收集的,所以很难判断“先有暴露还是先有结局”。
例如,同时发现高血压与吸烟有关,不能仅凭这一张横断面数据就判断因果方向。
时间顺序不清,是横断面研究统计基础的天然限制。
更现实的问题是混杂。
比如年龄、性别、疾病严重程度、生活方式,都可能同时影响暴露和结局。如果不控制,关联强度就会被放大或压低。
4.2 混杂控制要放在设计和分析两端
控制混杂,不能只靠回归分析。设计阶段就应该考虑。
常见方法包括:
- 限制纳入范围,如限定年龄层或性别。
- 匹配关键变量,如年龄、性别。
- 分层分析,看不同层内效应是否一致。
- 多因素模型,调整已知混杂因素。
如果研究变量很多,但样本量有限,就要避免过度调整。
横断面研究统计基础要求的是“合理控制”,不是“把所有变量都塞进模型”。
5. 如何把4类偏倚控制写进研究设计和论文
5.1 设计阶段先把偏倚风险降到最低
高质量的横断面研究,通常从设计开始就控制偏倚。
建议按以下顺序检查:
- 目标人群是否定义清楚。
- 抽样方法是否尽量随机。
- 纳入排除标准是否过于狭窄。
- 问卷、量表、检测方法是否标准化。
- 调查员是否统一培训。
- 是否预设混杂因素和统计方案。
这些步骤看起来基础,但恰恰是横断面研究统计基础最容易被忽略的地方。
很多“结果不稳”的论文,问题并不在模型,而在前面的设计。
5.2 结果报告要写清局限性,但不能空泛
讨论局限性时,建议直指问题来源。
可以写:应答率有限,可能存在无应答偏倚。
也可以写:部分暴露信息依赖自报,可能存在回忆偏倚。
还可以写:研究为横断面设计,暴露与结局同时测量,因果推断受限。
这种写法比笼统地说“本研究存在局限性”更专业,也更符合E-E-A-T要求。
6. 给医学生和科研人员的实操建议
6.1 做横断面研究前,先问自己4个问题
- 样本能代表目标人群吗。
- 问卷和指标可靠吗。
- 关键混杂因素控制了吗。
- 这个设计能回答因果问题吗。
如果这4个问题答不清,说明你的横断面研究统计基础还不够稳。
这时候先改设计,再收数据,远比后期补救更有效。
6.2 写作时优先突出“控制过程”,不是只报“结果显著”
审稿人通常更关注以下内容。
- 是否说明应答率。
- 是否说明抽样方法。
- 是否说明量表来源和信效度。
- 是否说明调整了哪些混杂因素。
- 是否承认了横断面设计的因果局限。
真正成熟的横断面研究,不是没有偏倚,而是知道偏倚在哪里,并且尽量把它控制住。
总结Conclusion
横断面研究统计基础的关键,不只是会做描述统计和回归分析,而是能系统识别4类偏倚,并在设计、测量、分析和写作中逐一控制。选择偏倚决定代表性,信息偏倚决定测量真实性,混杂偏倚影响关联解释,无应答偏倚则直接影响样本质量。把这些问题提前处理,研究结论才更可信。
如果你正在撰写横断面论文、课题设计或投稿讨论部分,建议结合解螺旋的科研写作与统计支持工具,快速完成偏倚梳理、方法优化和局限性表述,让你的横断面研究更规范、更容易通过审稿。
- 引言Introduction
- 1. 横断面研究统计基础的核心:先理解偏倚从哪里来
- 2. 选择偏倚:样本代表性不足,结论就会偏
- 3. 信息偏倚:测量不准,相关性会被扭曲
- 4. 混杂偏倚:看起来有关联,实际可能是第三因素在起作用
- 5. 如何把4类偏倚控制写进研究设计和论文
- 6. 给医学生和科研人员的实操建议
- 总结Conclusion