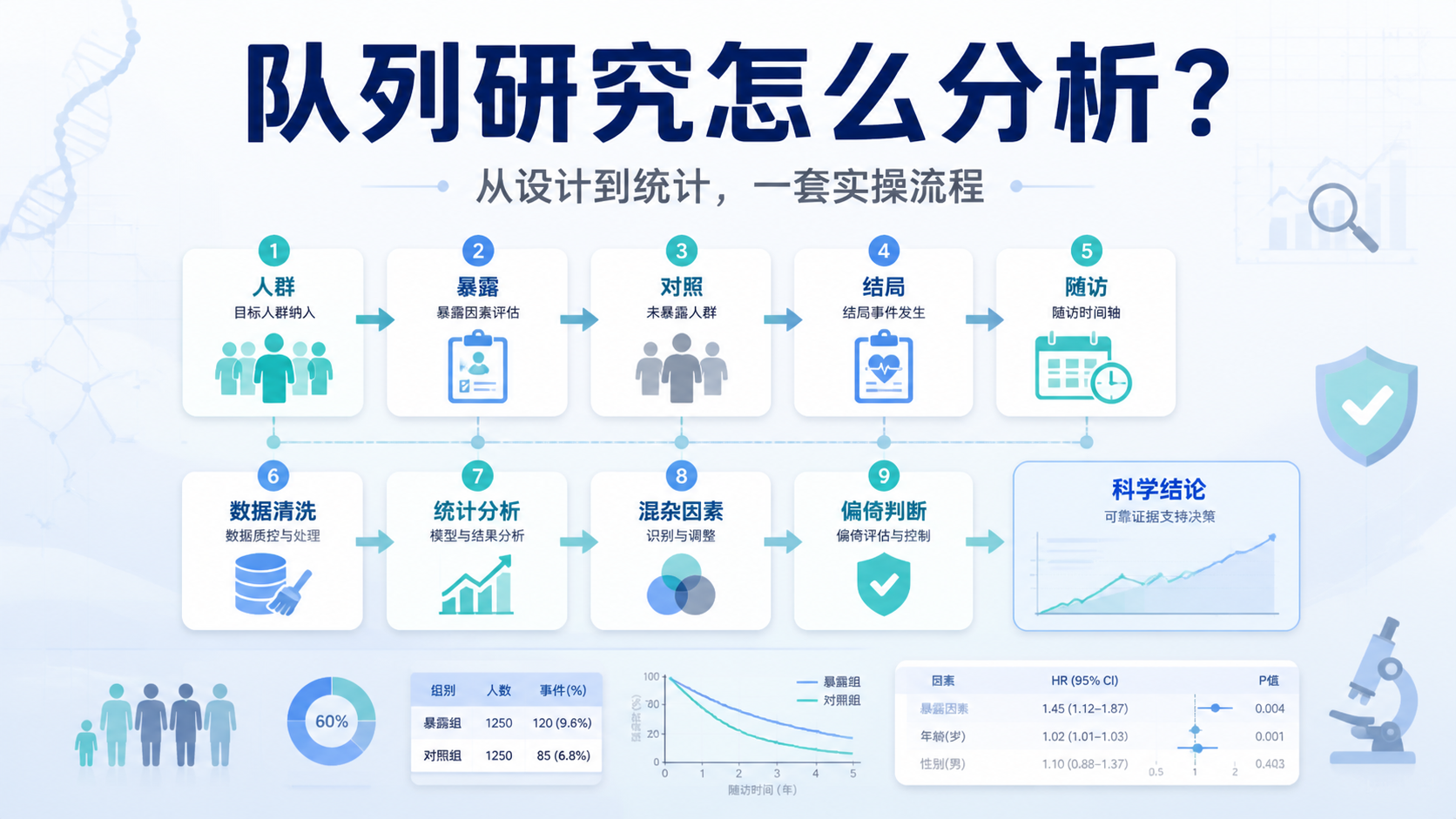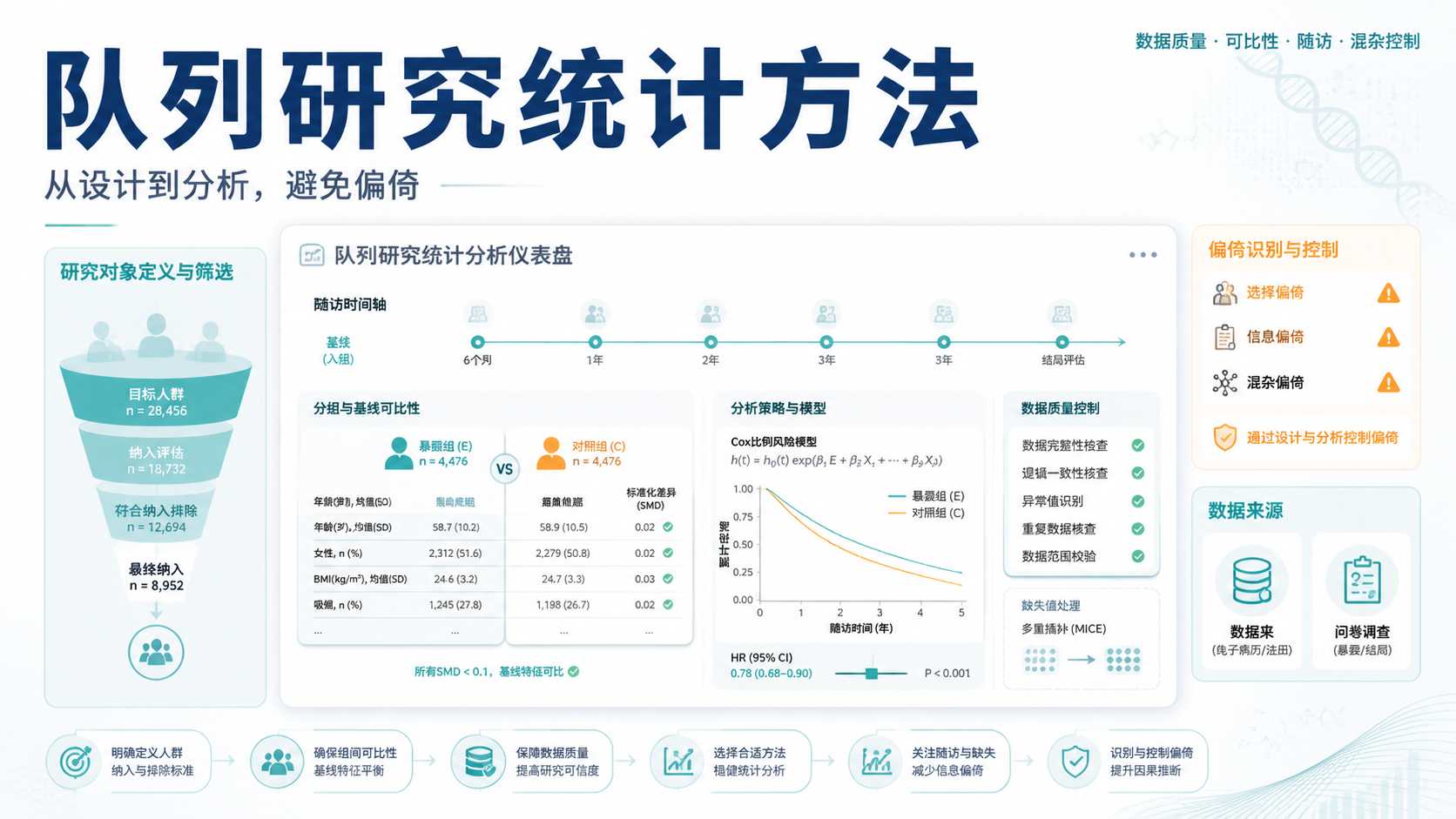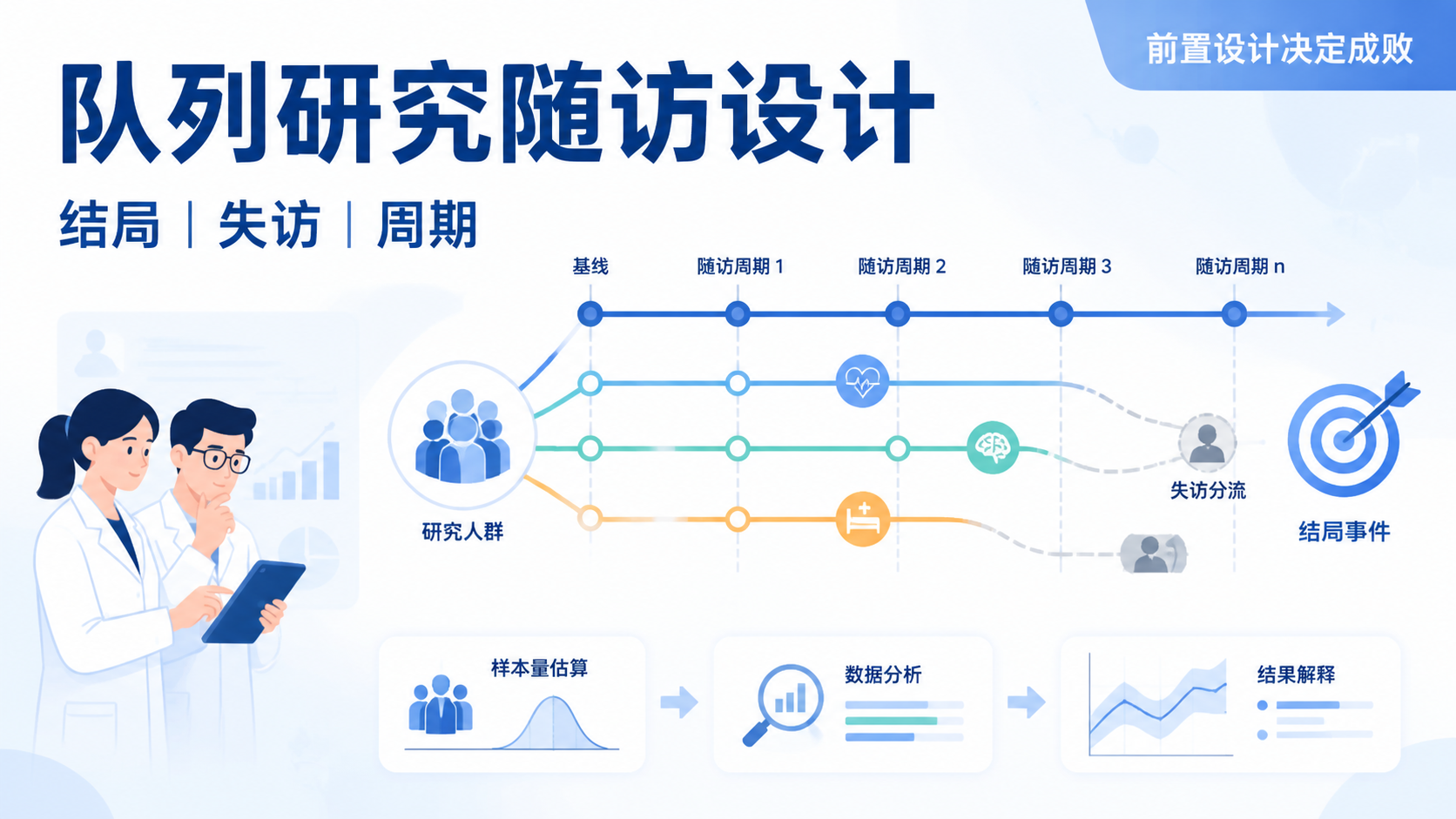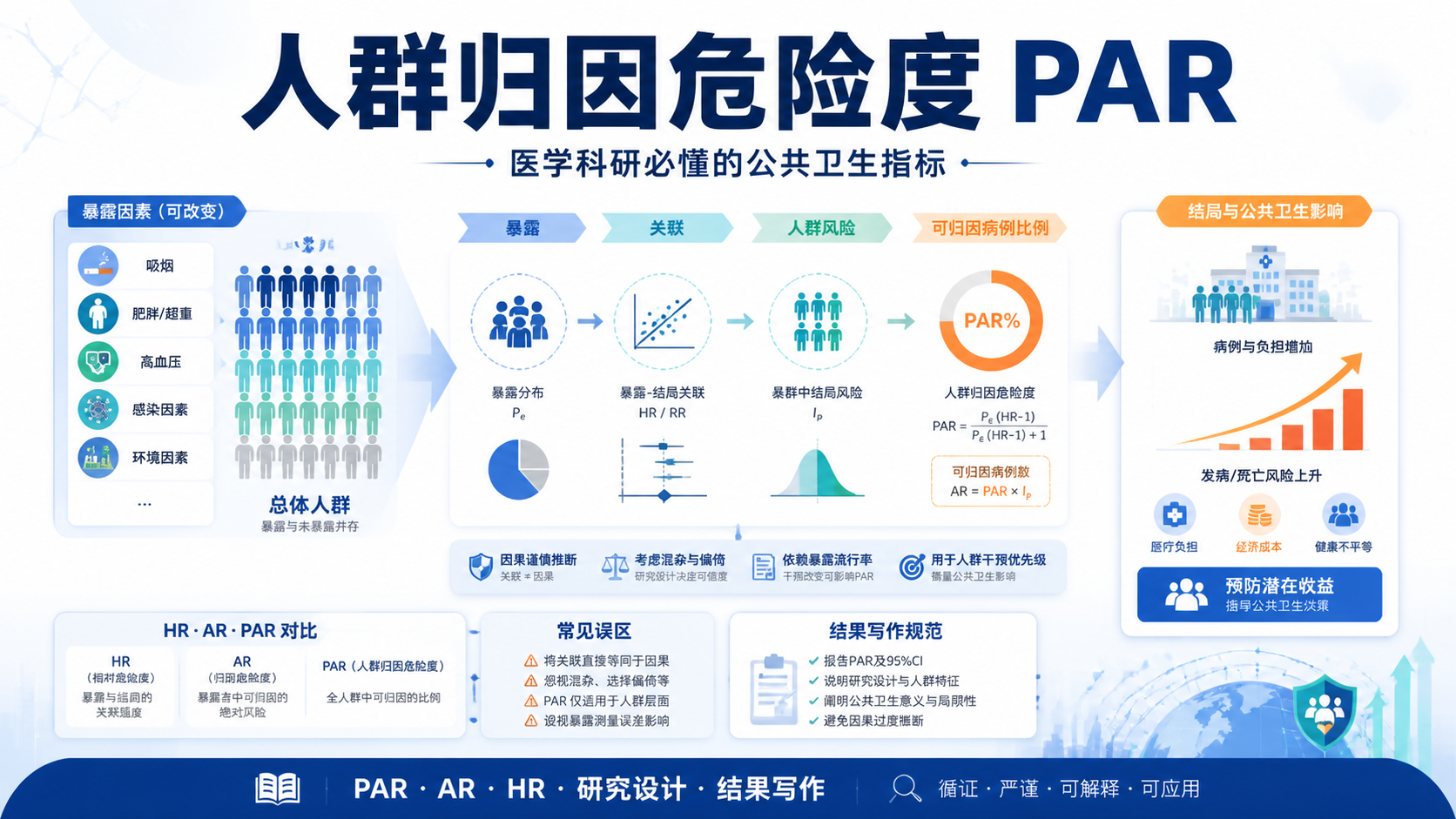
引言Introduction
队列研究失访率控制,是决定随访数据能否可信的关键。失访一旦偏高,结论就可能被歪曲。尤其在长期随访、历史性队列和多中心研究中,失访几乎不可避免。真正稳妥的做法,不是事后补救,而是从设计阶段就提前预防。

1. 先理解失访为什么会影响结论
1.1 失访本质上是系统性偏差
在队列研究中,失访属于选择性偏倚的一种。它不是随机缺数据,而是某些人更容易退出研究。如果失访组与未失访组的结局风险不同,结果就会被歪曲。
例如,暴露组失访者如果发病率高于未失访者,继续分析的人群会低估真实风险。反过来,也可能高估风险。这就是为什么队列研究失访率控制不能只看数字,还要看失访是否“有选择性”。
1.2 5%和20%是两个常用警戒线
上游知识库给出了两个实务判断。一般来说,失访率大于5%时,就应分析其偏性影响。
如果失访率达到20%以上,研究真实性就要受到严肃质疑。
这两个数字不是绝对标准,但对科研设计很有参考价值。对医学生、医生和科研人员来说,真正重要的是:
- 失访是否均衡分布在各组
- 失访者和未失访者基线特征是否相似
- 是否会影响主要结局判断
2. 设计阶段就把失访率控制住
2.1 选择稳定人群,比事后追人更重要
最好的队列研究失访率控制,发生在入组之前。
优先选择居住稳定、可持续联系、依从性较好的研究对象。比如长期居住在本地、联系方式稳定、门诊随访路径清晰的人群。
相反,下列对象更容易失访:
- 流动性高的人群
- 依从性差的人群
- 对研究兴趣低的人群
- 长周期、跨地区研究中的自然流失人群
2.2 纳入标准要现实,排除标准要明确
如果研究目标人群本身就难以随访,再完美的统计方法也很难弥补。设计时应明确:
- 随访周期是否真的可执行
- 研究对象是否有持续接触医疗系统的机会
- 结局是否能通过可靠渠道获取
对于历史性队列研究,还要优先选择档案完整、记录连续的资料来源。
档案丢失、记录不全,会把“数据缺失”变成“系统性缺失”。
3. 现场执行阶段,重点是提高依从性
3.1 让研究对象愿意继续参与
失访率控制的核心,不只是“找得到人”,还要“留得住人”。知识库强调,提高依从性非常关键。可操作的方法包括:
- 研究前做好预试验,评估流程可行性
- 设置合理的随访间隔
- 提高研究沟通质量
- 争取受试者主动配合
- 必要时优化服务条件和就诊便利性
随访体验越好,退出概率通常越低。
这对长期队列尤其重要。
3.2 建立固定的随访节奏
随访不能完全靠临时通知。建议提前规划:
- 固定随访时间点
- 固定随访方式
- 固定责任人
- 固定记录模板
这样做的好处是,团队对每个时间点的任务清晰,受试者也更容易形成习惯。对于多中心队列,更要统一操作标准,避免不同中心的随访质量差异过大。
3.3 多渠道保留联系方式
上游知识库提到,降低失访率的常见措施包括留下多种联系方式。实际执行中,通常应尽量收集:
- 手机号码
- 备用联系人
- 家庭住址
- 电子邮箱
- 常用社交工具信息
联系方式越完整,失访率控制越稳。
同时,要定期更新联系方式,避免因号码更换导致失联。
4. 研究团队层面,流程管理决定成败
4.1 专人管理比“谁有空谁跟”更可靠
失访率高的研究,常常不是因为方法不对,而是执行松散。建议设置专人负责随访管理,明确每一步责任:
- 谁发起随访
- 谁核实结局
- 谁记录失访原因
- 谁做二次追踪
专人管理能显著减少遗漏。
4.2 记录失访原因,不能只记“联系不上”
失访不是单一事件。要尽量记录具体原因,例如:
- 拒绝继续参与
- 搬迁外地
- 身体原因无法配合
- 联系方式失效
- 结局数据缺失
这些信息后续有助于判断是否存在差异性失访。对论文撰写和偏倚分析也很重要。
4.3 失访者与未失访者要做基线比较
知识库明确指出,补救失访偏倚的常用办法之一,是比较失访者和未失访者的基线特征。比如:
- 年龄
- 性别
- 暴露状态
- 既往病史
- 主要危险因素
两者越相似,失访造成的偏倚越可能较小。
如果差异明显,就要谨慎解释结果。
5. 数据分析阶段,别把失访当成“简单缺失”
5.1 先判断失访是否影响主要结局
如果各组失访人数相当,且失访者与未失访者的发病率相同,失访对结果影响可能较小。
但一旦失访集中在某一组,或失访者风险明显不同,分析结果就可能被扭曲。
因此,队列研究失访率控制不仅是现场工作,也包括统计判断。
5.2 失访率较高时,要考虑生存分析
对于截尾数据,知识库提到可采用生存分析方法处理。
这在长期随访、结局发生时间不一致的队列中很常见。合理使用生存分析,可以更准确地利用部分随访信息,而不是简单删掉。
5.3 不要轻易把高失访研究结论写得太满
如果失访率接近或超过20%,即使统计结果显著,也要谨慎。因为这时结论可能更多反映“留下来的人”,而不是全部研究对象。高失访会直接削弱研究外推性和真实性。
6. 实操中最稳妥的做法有哪些
6.1 一套更稳妥的控制清单
如果你在做队列研究,可以直接按下面思路检查:
- 入组前先筛选可长期随访人群
- 设定清晰的纳入和排除标准
- 收集多种联系方式
- 建立固定随访时间表
- 指定专人负责追踪
- 记录每一次失访原因
- 定期比较失访者与未失访者特征
- 在分析阶段处理截尾和缺失问题
这套流程的核心,不是追求零失访,而是把失访对结论的伤害降到最低。
6.2 常见误区要避免
很多研究者以为,只要最后把样本量做大就够了。其实不然。
常见误区包括:
- 只关注总样本数,不管随访质量
- 只统计失访人数,不分析失访机制
- 只做一次电话联系,不做多轮追踪
- 只报总体失访率,不报各组失访率
这些做法都会削弱队列研究失访率控制的效果。
总结Conclusion
队列研究失访率控制,核心是提前设计、过程管理和分析判断三步并行。先选稳定人群,再建稳定流程,最后看失访是否真正影响结论。
对于医学生、医生和科研人员来说,稳妥的随访不是靠运气,而是靠规范。若你希望在队列研究设计、随访管理和偏倚控制上进一步提升效率,可以借助解螺旋品牌的科研支持工具与方法体系,把失访风险尽量前移、前置、前控。
- 引言Introduction
- 1. 先理解失访为什么会影响结论
- 2. 设计阶段就把失访率控制住
- 3. 现场执行阶段,重点是提高依从性
- 4. 研究团队层面,流程管理决定成败
- 5. 数据分析阶段,别把失访当成“简单缺失”
- 6. 实操中最稳妥的做法有哪些
- 总结Conclusion