引言Introduction
人群归因危险度 PAR 是流行病学和临床研究中常被误用的指标。很多人会算,却不一定会解释,更容易把“相关”说成“因果”。如果你在做危险因素筛选、公共卫生评估或论文解读,先弄清 PAR 的前提、公式和适用边界,远比直接套公式重要。

1. 什么是人群归因危险度 PAR
1.1 PAR 的核心含义
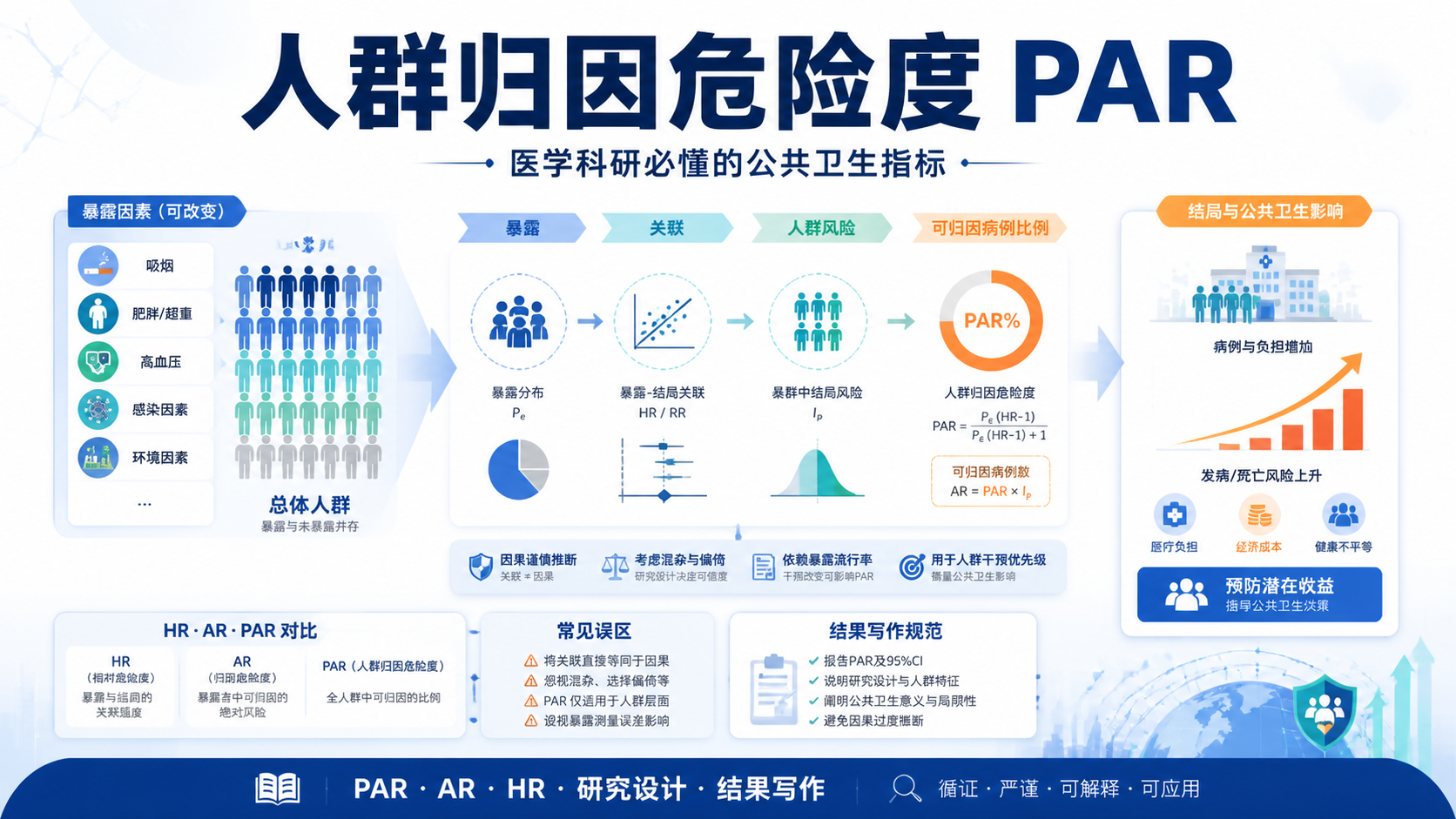
人群归因危险度 PAR,指的是某个暴露在全人群中导致的疾病负担中,有多少比例可以归因于该暴露 。它关注的是“如果去除这个暴露,人群层面的疾病负担能减少多少”。
这和单个个体的风险不同。PAR 不是回答“某个人会不会得病”,而是回答“人群中有多少病例与这个因素有关”。因此,它更适合做公共卫生决策、干预优先级排序和资源配置评估。
1.2 PAR 和 AR 的区别
AR 是归因危险度,关注暴露组内部的超额风险。PAR 则是在总体人群中计算,同时受暴露率和暴露效应大小影响 。
也就是说,某因素即使相对危险度很高,如果在人群中暴露率很低,PAR 也可能不大。反过来,暴露率很高、效应中等的因素,PAR 可能更大。
2. PAR 为什么在危险因素研究中重要
2.1 它连接了“统计关联”和“公共卫生意义”
在观察性研究中,很多暴露都能得到显著 HR、OR 或 RR,但并不意味着它们对人群健康的实际影响相同。PAR 的价值在于把效应量与暴露频率结合起来 ,帮助研究者判断哪个危险因素更值得优先干预。
例如,某研究中如果暴露因素与肺癌风险增加相关,但暴露分布集中在少数人群,PAR 可能有限。若一个常见暴露对风险的影响中等,PAR 反而可能更高。
2.2 它适合用于病例预防负担估计
PAR 常用于估计可预防病例数。前提是暴露与结局关系成立,且暴露具有可干预性。
这也是人群归因危险度 PAR 最容易被误用的地方。 如果暴露不可逆、不可避免,或者关系未被混杂充分控制,直接解释为“可避免比例”就不严谨。
3. 计算 PAR 之前必须确认的前提
3.1 暴露与结局之间要有可靠关联
PAR 的基础是暴露和结局存在稳定关联,且最好有足够的混杂控制。
在观察性研究里,常见做法包括:
- 多因素回归校正年龄、性别、BMI、吸烟等混杂因素。
- 做敏感性分析,检查结果是否稳健。
- 做亚组分析,观察不同人群中的一致性。
如果主效应本身不稳定,PAR 的解释就会很脆弱。
3.2 研究设计要支持因果解释的谨慎推断
PAR 常被写进论文讨论,但它并不自动等于因果效应。
只有当研究设计、变量控制和时间顺序都足够清晰时,PAR 才更接近“可归因”的含义。
在回顾性队列、医保数据库或临床登记数据中,尤其要注意:
- 暴露定义是否准确。
- 结局定义是否一致。
- 是否存在选择偏倚和信息偏倚。
- 是否有未测量混杂。
4. 人群归因危险度 PAR 的常见计算思路
4.1 最常见的基本公式
如果已知暴露组相对危险度 RR 和全人群暴露比例 Pe,常用的 PAR 公式为:
PAR = Pe × (RR - 1) / [1 + Pe × (RR - 1)]
这个公式的直观含义是,暴露越常见,效应越强,PAR 越大。
但要注意,RR 更适合队列研究;病例对照研究里常会用 OR 近似替代,但前提是疾病不罕见时要更加谨慎。
4.2 当研究使用 HR 时要小心
很多临床队列研究报告的是 HR,而不是 RR。
HR 反映的是随访期间的瞬时风险比,不能机械等同于 RR 。如果直接把 HR 套进 PAR 公式,得到的值只能作为近似估计,解释时必须说明方法限制。
对于医学生和科研人员来说,最稳妥的做法是先确认:
- 研究终点是否是时间结局。
- 是否有足够随访。
- 是否采用 Cox 回归。
- 是否有时间依赖性风险变化。
5. 人群归因危险度 PAR 容易犯的4个错误
5.1 把相关性当成因果
这是最常见的问题。
PAR 不是因果证明。 即使某暴露的 PAR 很高,也不能直接说“去掉它就一定能减少这么多病例”。如果混杂因素没有控制好,PAR 可能高估真实影响。
5.2 忽略暴露分布差异
不同人群、不同地区、不同时间段,暴露率可能差异很大。
因此,同一个危险因素在一个队列中的 PAR 很高,在另一个队列里可能明显下降。发表论文时,必须明确样本来源和适用范围。
5.3 混淆个体风险和人群风险
个体层面看的是“这个人暴露后风险增加多少”。
人群层面看的是“这个因素在总体疾病负担中占多少”。
这两个层面不能互相替代。 临床决策更关注个体风险,公共卫生更关注 PAR。
5.4 直接解释为可完全消除的病例比例
真实世界里,很少有暴露可以被完全移除。
因此,PAR 更适合解释为“理论上可减少的比例”,而不是现实中必然能达到的结果。研究讨论中应避免绝对化表述。
6. 做 PAR 研究时,结果该怎么写才专业
6.1 先报告关联效应,再报告归因比例
写作顺序很重要。建议先交代暴露与结局的关联强度,再给出 PAR。这样读者能先判断基础证据,再理解人群层面的意义。
例如,研究可以先说明某暴露与结局的 HR、95% CI 和 P 值,再说明其在人群中的归因比例。
6.2 结果部分要交代清楚数据来源和校正变量
专业写法至少应包括:
- 数据来源,如医保数据库、前瞻性队列、医院队列。
- 暴露定义和随访时间。
- 结局事件的判定方式。
- 校正变量清单。
- 敏感性分析结果。
没有这些信息,PAR 的可信度会明显下降。
6.3 讨论部分要体现边界
讨论时要说明:
- PAR 依赖研究假设。
- 结果受混杂和偏倚影响。
- 不同模型和不同暴露定义可能改变估计值。
- 该结果更适合用于风险管理,而不是个体诊断。
7. 医学生和科研人员如何高效理解 PAR
7.1 先抓住三个问题
读到人群归因危险度 PAR 时,先问自己:
- 这个暴露在人群中常见吗?
- 它与结局的关联稳定吗?
- 结果能否用于公共卫生干预?
只要这三点不清楚,PAR 的结论就不应写得太满。
7.2 把 PAR 放回研究设计中理解
在危险因素筛选类研究里,常见流程是:
先明确人群、暴露和结局,再用回归模型控制混杂,最后讨论其人群意义。
PAR 是最后一层推断,不是起点。 如果前面的设计不稳,最后的归因比例也不稳。
7.3 借助工具提升论文写作效率
对于正在写作或做课题的人,难点往往不在公式,而在于如何把统计结果写得规范、可发表、可复核。此时可以结合解螺旋的科研写作与数据分析支持,帮助整理变量、规范结果表述,并将风险因素研究更清晰地转化为论文语言。这样能减少公式误用,也更利于把 PAR 结果放进 E-E-A-T 导向的专业叙述中。
总结Conclusion
人群归因危险度 PAR 的核心,是把“暴露效应”与“人群暴露率”结合起来,回答公共卫生层面的可归因负担问题。它很有价值,但前提是暴露关联稳定、混杂控制充分、解释边界清楚。对于医学生、医生和科研人员来说,真正重要的不是会不会套公式,而是会不会判断 PAR 是否适用、是否可信、是否能用于决策。

如果你正在整理危险因素研究、撰写结果段落或解读 PAR 指标,建议结合解螺旋的专业支持,把统计结论转化为更规范、更易发表的论文表达。
- 引言Introduction
- 1. 什么是人群归因危险度 PAR
- 2. PAR 为什么在危险因素研究中重要
- 3. 计算 PAR 之前必须确认的前提
- 4. 人群归因危险度 PAR 的常见计算思路
- 5. 人群归因危险度 PAR 容易犯的4个错误
- 6. 做 PAR 研究时,结果该怎么写才专业
- 7. 医学生和科研人员如何高效理解 PAR
- 总结Conclusion