






引言Introduction
GEO芯片数据下载看似简单,真正难的是找对文件、读对格式、避免后续分析踩坑。对医学生和科研人员来说,下载后的表达矩阵、探针注释、样本分组信息是否完整,直接决定差异分析能否顺利开展。本文用3步讲清流程。
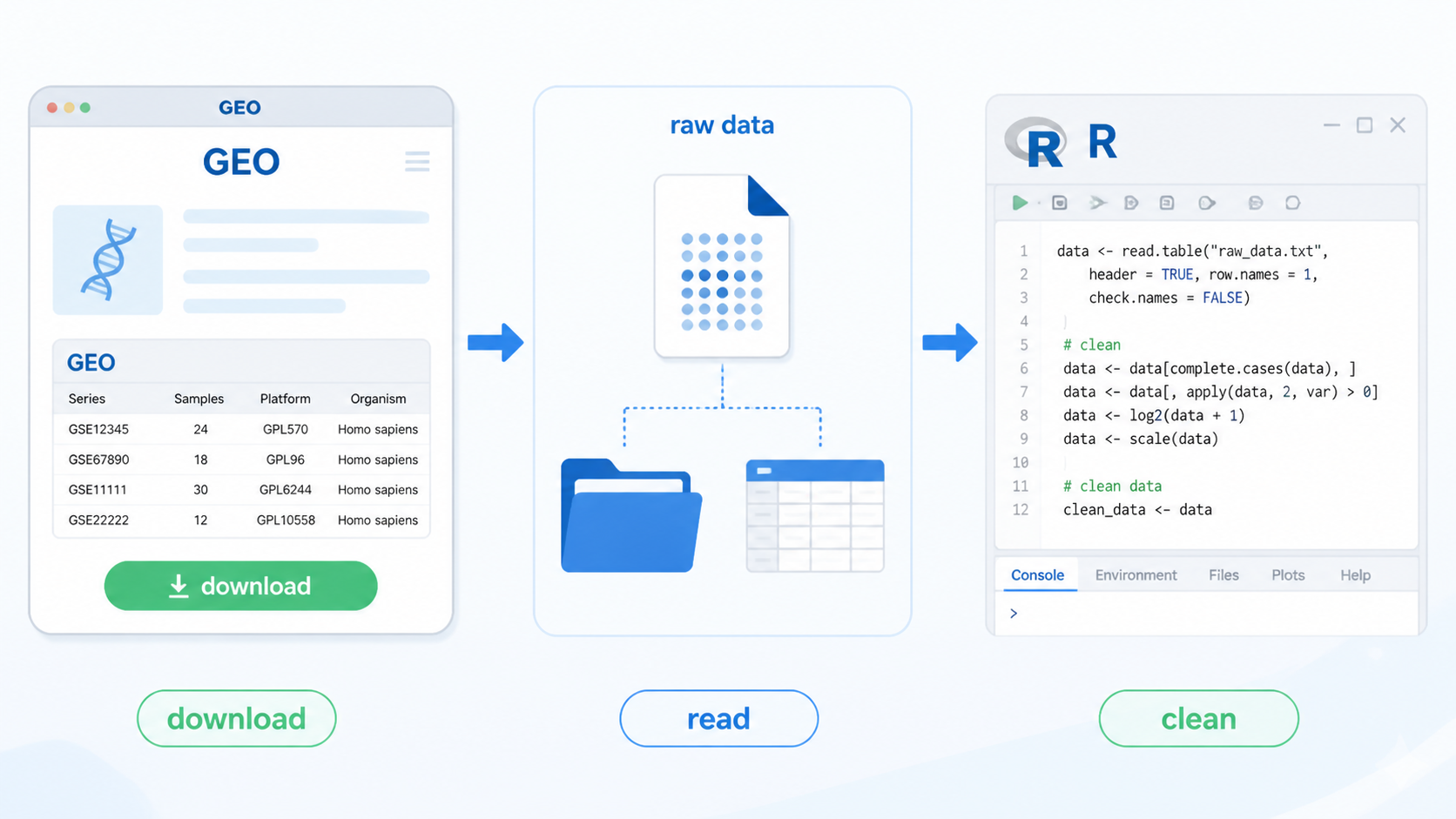
1. 先明确 GEO芯片数据下载 的目标文件
1.1 下载前先判断你要什么数据
做 GEO芯片数据下载,第一步不是点下载,而是先判断数据类型。常见需求有三类。
- 原始数据。比如 Affymetrix 的 CEL,Illumina 的 IDAT,Agilent 的 GPR。
- 已处理表达矩阵。常见于 GEO 的 Series Matrix 文件。
- 注释和分组信息。包括探针注释、样本分组、处理条件、临床信息。
如果目标是差异表达分析,最理想的组合是表达矩阵、探针注释和样本分组信息同时具备。
只有原始数据时,需要后续预处理。只有矩阵时,也要确认它是否已经做过标准化。
1.2 先看平台和文件后缀
不同平台对应不同下载策略。知识库中提到,常见芯片原始文件后缀包括 CEL、IDAT、TXT、CSV、GPR。平台不同,读取包也不同。
- Affymetrix:常用 affy 包、oligo 包。
- Illumina:常用 beadarray 包、lumi 包。
- Agilent:常用 limma 相关函数或 Agilent microarray 包。
- GEO 数据:常用 GEOquery 包。
文件格式决定了后续R包选择。 这一步判断错了,后面会浪费大量时间。
1.3 原始数据、补充文件和注释文件要分开理解
很多初学者把 GEO 页面里所有可下载内容混为一谈。实际上,至少要分清三类。
- 原始芯片文件,供重新处理。
- Series Matrix 或 soft 文件,常用于直接读取表达矩阵。
- 平台注释文件,帮助完成探针到基因的映射。
知识库明确提到,探针注释信息和样本分组信息是差异分析必需项 。表达矩阵只有一份还不够。后续还要把列名对应到样本信息,把行名对应到探针注释。
2. 用 GEOquery 完成 GEO芯片数据下载与读取
2.1 getGEO 是最常用入口
在 GEO 芯片数据下载场景中,GEOquery 是核心工具。最常见函数是 getGEO()。
它的作用有两个。
- 直接下载或读取单个数据集。
- 读取本地已经下载好的文件。
如果本地已存在文件,直接用 filename 参数读取,速度更快。
知识库中也提到,force=TRUE 常更适合处理大数据集,因为避免反复等待。
2.2 Series Matrix 文件更适合快速启动
对于大多数 GEO 芯片数据下载任务,Series Matrix 是最实用的起点。原因很直接。
- 文件比 soft 小。
- 更容易直接提取表达矩阵。
- 可快速拿到样本相关信息。
知识库中还指出,有些 GSE 下可能有多个 Series Matrix 文件,比如不同平台对应不同文件。这时不能只读一个,要分别解析。同一GSE下多平台数据,必须先确认平台编号。
2.3 读取临床和样本信息,避免只拿到表达矩阵
很多人只下载表达矩阵,结果后面无法分组。实际上,GEOquery 不只用来取矩阵,还能辅助提取样本信息。
常见可提取内容包括:
- 样本简要介绍。
- 处理方式。
- 日期信息。
- 临床相关字段。
- 样本分组线索。
知识库中提到,Series Matrix 里通常包含几十列信息。其中“数据如何处理”尤其重要。 如果样本已经做过标准化,分析时通常不建议重复标准化,否则可能造成矫枉过正。
2.4 GEO页面表格信息也能直接抓取
有些 GEO 页面除矩阵外,还会提供网页表格。比如临床分组、病人信息、样本说明等。知识库中提到,可以通过 GEOquery 的相关函数直接提取表格信息。
这类表格适合用于:
- 补充分组信息。
- 整理样本表型。
- 核对样本名称和平台信息。
对科研人员来说,下载后第一件事不是画图,而是核对样本是否能一一对应。
3. GEO芯片数据下载后的整理与质控
3.1 下载只是开始,整理才决定能不能分析
真正可用的 GEO芯片数据下载结果,不是一个孤立文件,而是一套可分析对象。最少要整理出三类数据。
- 表达矩阵。
- 探针注释。
- 样本信息表。
知识库明确提到,数据清洗的核心目标就是把原始数据转成整洁的基因表达矩阵,同时整理列名和行名相关信息。没有这一步,后面的 limma 差异分析无法规范开展。
3.2 读入R后先做基础预处理
数据导入R之后,建议先检查以下内容。
- 样本数是否与元数据一致。
- 是否存在重复样本名。
- 基因名是否被Excel改写。
- 是否存在明显缺失值。
- 是否已经做过平台标准化。
知识库特别提醒,不建议把表达矩阵反复用 Excel 打开和另存。因为 Excel 可能自动修改基因名,例如把日期样式字符串改写成日期格式。这会直接破坏基因名的准确性。
3.3 质量评估贯穿整个流程
芯片数据处理不是“下载完就完事”。从背景校正、标准化、批次效应去除,到最终差异分析,每一步都应检查数据质量。
常见检查重点包括:
- 标准化前后分布是否更一致。
- 批次效应去除前后是否改善聚类。
- 样本间是否存在异常点。
- 表达矩阵是否符合预期维度。
质量评估不是附属步骤,而是 GEO芯片数据下载 后能否进入正式分析的前提。
3.4 选择正确的工具能减少返工
知识库中给出的思路很明确。下载速度慢时,可以先获取链接,再用本地工具下载。读取时则根据数据类型选择对应R包。
常见实践是:
- 原始文件下载后,再用对应包解析。
- Series Matrix 先读取,再整理分组。
- 注释表单独提取,便于后续ID转换。
对需要批量处理多个数据集的团队来说,这种方法更稳。先下载、再读取、再整理,是最不容易出错的工作流。
3.5 解螺旋可以帮助你少走弯路
如果你在 GEO芯片数据下载 后还要继续做差异表达分析、ID转换、可视化,工作量会迅速上升。解螺旋的生信课程与代码流程,已经把下载、读取、整理、质控和后续差异分析拆成清晰步骤。
它的价值在于把零散操作变成可复用流程,减少反复试错。对于医学生、医生和科研人员,这意味着更快完成数据整理,更快进入结果验证。
总结Conclusion
GEO芯片数据下载的核心,不是“把文件下载下来”,而是下载到正确的数据、读出正确的结构、整理成可分析的矩阵 。只要按“确认文件类型、用GEOquery读取、完成整理和质控”这3步走,后续差异表达分析会顺很多。
如果你希望进一步把 GEO芯片数据下载、表达矩阵提取、样本整理和差异分析串成完整流程,建议直接跟随解螺旋的实战内容继续学习。
- 引言Introduction
- 1. 先明确 GEO芯片数据下载 的目标文件
- 2. 用 GEOquery 完成 GEO芯片数据下载与读取
- 3. GEO芯片数据下载后的整理与质控
- 总结Conclusion



