引言Introduction
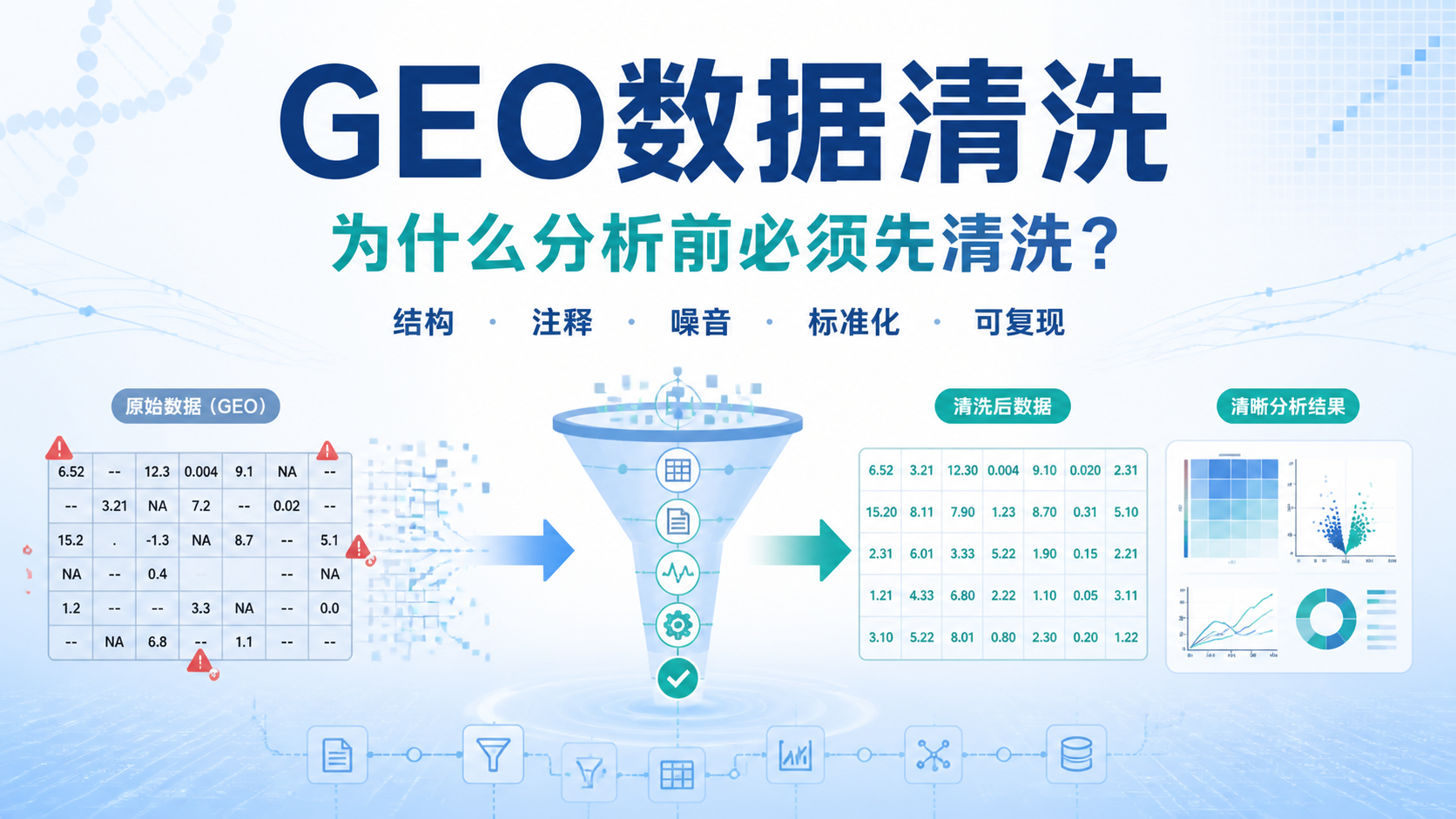
geo数据注释 是很多生信分析卡在第一步的地方。原始矩阵看似完整,但探针ID、基因名、平台注释常常分离,稍有疏忽就会导致后续差异分析和富集分析出错。下面用5个关键步骤,帮你把GEO数据从“能下载”变成“能直接分析”。
1. 先明确数据类型和注释对象
1.1 先分清是GEO DataSets还是GEO Profiles
GEO数据库主要有两个常用子库。GEO DataSets以数据集为单位,GEO Profiles以基因为单位,存储的是基因表达谱。做geo数据注释 时,绝大多数场景都围绕GEO DataSets展开,因为你需要的是某个数据集中的表达矩阵和平台信息。
先看清楚你注释的对象是什么。 如果是Series、Sample,重点是样本分组和表达矩阵。如果是Platform,重点是探针与基因的对应关系。不同对象,对应的注释方法不同。
1.2 明确平台决定注释方式
GEO衍生出platform、samples、series、datasets、profile五类数据。平台信息通常决定注释文件怎么读。常见情况有两类。
- 平台注释表直接给出gene symbol。
- 平台注释表只给出探针ID、gene assignment或序列,需要进一步提取。
没有先识别平台,就谈不上规范的geo数据注释。 这是后续所有步骤的基础。
2. 获取表达矩阵和平台注释文件
2.1 优先下载Series Matrix
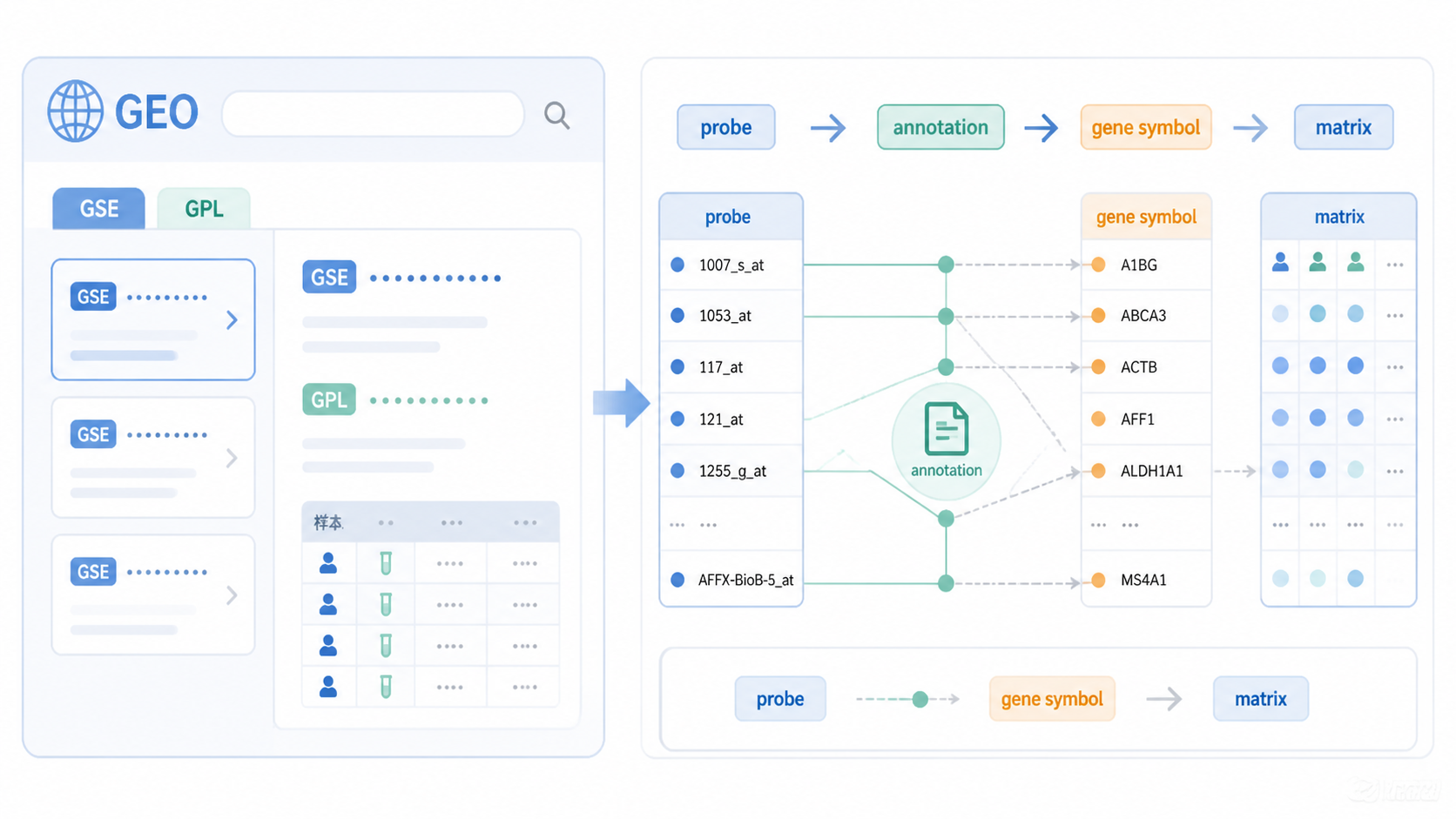
在实际分析中,最常用的是Series Matrix File(s)。它通常是txt格式,包含数据集基本信息和标准化后的表达矩阵。第一列多为探针ID,第一行是样本编号。对于大多数geo数据注释 流程来说,这个文件是核心输入。
Series Matrix的好处是结构相对统一,适合快速进入分析。它往往比原始文件更适合初学者和临床科研人员直接使用。
2.2 同步下载平台注释文件
只拿表达矩阵还不够。你还需要平台注释文件。常见下载方式包括完整注释表和SOFT、MINiML等格式文件。课程内容指出,多数情况下下载第一个完整表格就足够 ,无需额外下载更复杂的SOFT格式。
如果注释表中gene symbol不是单独一列,而是藏在gene assignment里,就需要进一步拆分。比如用双斜杠分隔后提取第2个元素,才能得到gene symbol。这个动作是geo数据注释 中最容易出错的一步。
3. 完成探针到基因名的映射
3.1 将探针ID与注释表对应
表达矩阵的第一列通常是探针编号。平台注释表也会包含探针编号。你需要做的,是把两张表按探针ID合并,得到每个探针对应的基因信息。这样才能把原始矩阵转成可读性更高的基因矩阵。
这一步的本质,是把“平台语言”翻译成“基因语言”。 没有这一步,后面的差异分析结果往往只能停留在探针层面,不利于解释。
3.2 处理不同平台的注释差异
并非所有平台都提供标准gene symbol。有些平台只有探针序列,尤其是非编码RNA平台。这时就不能直接硬套现成注释,需要借助blast等比对工具去获得基因名称。
课程中也强调了这一点。不同平台,注释逻辑不同。 因此在做geo数据注释时,不能只看文件名,要先看平台注释说明和列名定义。
4. 核对样本信息与分组含义
4.1 读懂Series和Sample页面
注释基因只是第一层。真正能不能用于分析,还要看样本分组是否清楚。GEO数据并不总是规范。某些数据集的分组说明很简短,单看summary无法完全判断,这时要结合样本名称、描述、处理条件一起确认。
样本分组错误,后续统计分析会整体失真。 这是很多人做完geo数据注释后仍然报错或结果不可信的原因。
4.2 重点检查样本数量和处理信息
筛选GEO数据时,课程建议低于6个样本的数据集通常不纳入优先候选。原因很直接,样本太少,稳定性差,差异分析容易受个体波动影响。
另外,还要看样本是否经过中位数中心化处理,或者是否存在明显异常值。页面中的热图和样本中位数位置,能帮助你判断数据是否适合继续分析。geo数据注释不是单纯改列名,而是同步完成数据可用性审核。
5. 交叉验证并沉淀可复用数据表
5.1 通过多轮检索避免漏数
GEO检索不是一次完成的。合理做法是至少经历5个过程。先普筛,再查漏,再加限定词,再查缺补漏,最后去PubMed核对文献中实际使用了哪些GSE编号。
举例来说,肝细胞癌可以用HCC、liver cancer、hepatocellular carcinoma等不同关键词重复检索。同一个研究方向,检索词不同,结果会明显不同。 这一步能显著提升geo数据注释的完整性。
5.2 建立自己的注释与数据清单
当你把可用的GSE编号、平台编号、表达矩阵、表型矩阵和注释文件整理成Excel后,后续项目会轻松很多。课程明确建议把数据集Excel保存好,并尽量提取表达矩阵和表型矩阵备用。
这一步的价值很高。因为geo数据注释不是一次性动作,而是可复用的数据资产建设。 你可以在同一疾病方向下持续更新列表,减少重复劳动。
6. 实操中最容易出错的3个点
6.1 只下载矩阵,不下载平台注释
很多人拿到Series Matrix就直接开始分析,结果发现列名还是探针ID。这样得到的差异基因列表解释性很差。没有平台注释,就没有完整的geo数据注释。
6.2 误把SOFT和MINiML当成不同内容
课程说明,SOFT和MINiML本质上是内容相同、格式不同的文件。下载其中一种即可,没必要重复占用时间。对于实操而言,Series Matrix和平台完整表格通常更关键。
6.3 忽略平台版本和注释字段
有的平台存在不同版本,还有的平台注释列并不统一。注释时要看列名说明,不能想当然。否则容易把gene symbol、gene assignment、gene sequence混为一谈。字段理解错误,会直接影响结果质量。
7. 为什么这5步对科研分析很重要
7.1 提升分析效率
当你掌握了标准化的geo数据注释流程,后续就能快速形成自己的数据清单,减少反复找数据、重复整理的时间。对临床医生和科研人员来说,这比单纯学会下载更有价值。
7.2 提升结果可信度
GEO数据本质上是公共数据库资源。它的优点是样本成本低、可复用,但前提是你必须正确理解平台和样本信息。注释准确,结果才有解释力。 这直接关系到差异分析、通路富集和图表展示的可信度。
7.3 提升可复用性
把表达矩阵、平台注释、样本分组和GSE编号整理成统一表格后,后续做同一疾病方向时可以直接调用。长期看,这比每次临时搜集更高效,也更符合科研工作流。
总结Conclusion
geo数据注释的核心,不只是把探针改成基因名,而是完成“数据识别、文件下载、探针映射、样本核对、结果沉淀”这一整套流程。 对于医学生、医生和科研人员来说,真正有价值的是建立可复用的GEO数据清单,并让每一次分析都站在可靠注释之上。
如果你想把这套流程做得更快、更稳,建议直接使用解螺旋 的科研实操资源和工具支持,减少重复整理时间,把精力放在结果解读和论文产出上。

- 引言Introduction
- 1. 先明确数据类型和注释对象
- 2. 获取表达矩阵和平台注释文件
- 3. 完成探针到基因名的映射
- 4. 核对样本信息与分组含义
- 5. 交叉验证并沉淀可复用数据表
- 6. 实操中最容易出错的3个点
- 7. 为什么这5步对科研分析很重要
- 总结Conclusion