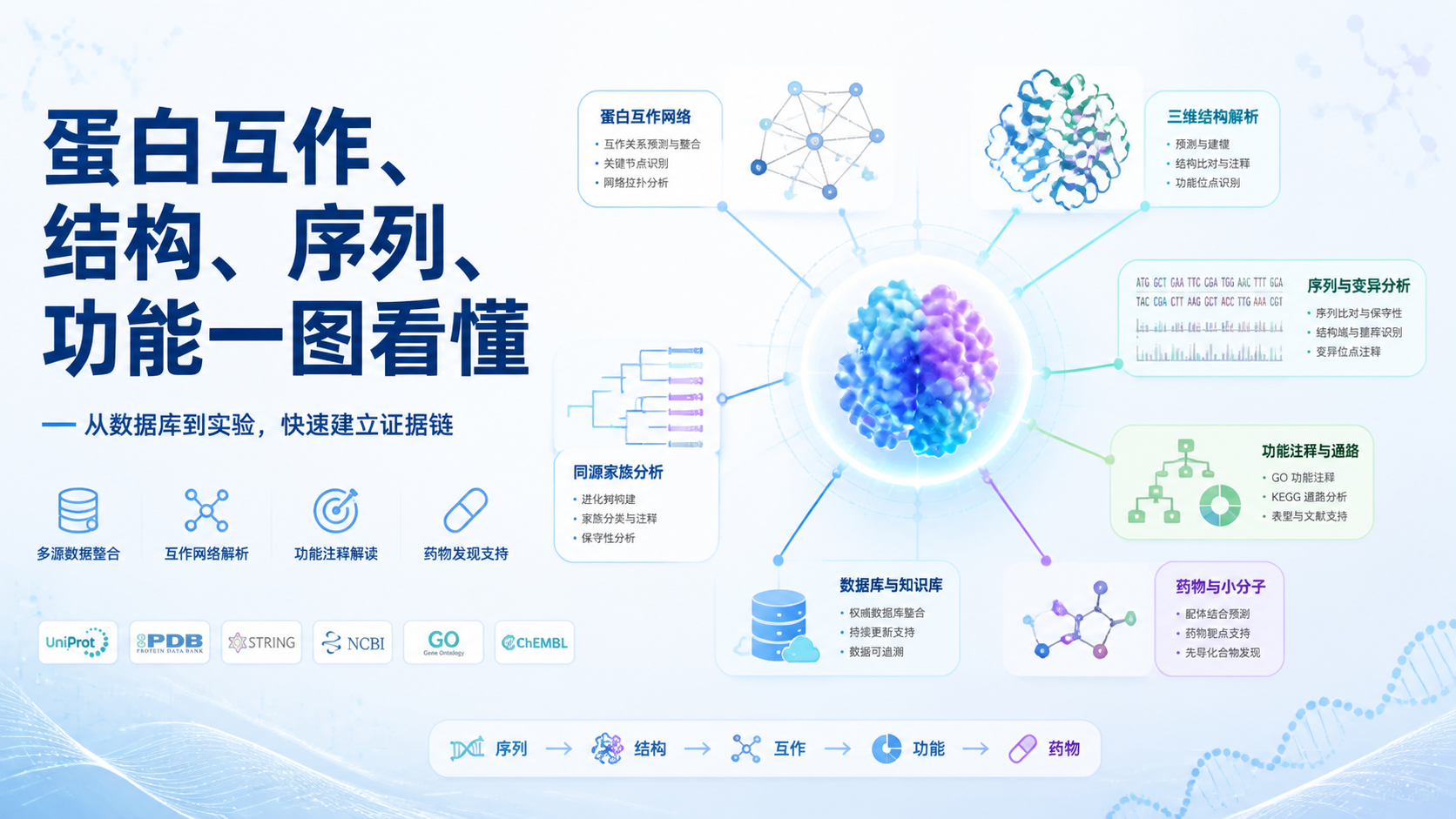
引言Introduction
蛋白组数据库 是蛋白研究的入口,也是很多医学生和科研人员最常卡住的地方。信息太多,工具太散,容易查到数据,却不知道怎么用。本文用4类常见用途,帮你快速理清蛋白组数据库 的核心价值。

1. 用于蛋白互作研究,定位功能网络
1.1 从单个蛋白扩展到互作图谱
蛋白组数据库 最常见的用途之一,是做蛋白-蛋白相互作用分析。蛋白不是孤立工作的。很多生物学过程,都是通过互作网络完成的。数据库可以帮助你快速找到已知互作和预测互作。
在互作分析中,常见资源包括 Interaction 界面、CORUM、DIP、IntAct、MINT、STRING 和 BindingDB。它们覆盖的侧重点不同。比如,CORUM强调哺乳动物蛋白复合物,且注释来自发表论文中的单个实验。DIP和IntAct更偏向实验验证互作。MINT聚焦文献挖掘的实验验证互作。STRING则整合已知和预测互作,适合先做网络框架判断。
如果你想从一个蛋白出发,快速看它可能参与哪些通路、复合物或调控模块,蛋白组数据库能显著提高效率。
1.2 如何把互作数据变成可解释结论
互作数据的关键,不是“找到很多蛋白”,而是“判断哪些证据更可靠”。例如,STRING的连接线可区分数据库证据、实验验证、文本挖掘、共表达、基因融合和同源转移等来源。这样你可以区分已知证据和预测关系。
常用分析步骤如下:
- 以目标蛋白为核心检索。
- 设置物种,避免跨物种混淆。
- 查看证据来源,而不是只看网络密度。
- 适当提高互作阈值,减少噪音。
- 结合文献和实验设计,筛选下一步验证对象。
对科研人员来说,蛋白组数据库的价值,不只是“查到互作”,而是“帮助你提出可验证的假设”。
2. 用于结构研究,辅助理解蛋白功能
2.1 从序列到三级结构的快速过渡
蛋白组数据库 的第二类用途,是结构查询与结构解释。结构信息能帮助你理解蛋白为什么有特定功能,也能提示突变位点可能带来的影响。
在结构检索中,常见数据库会提供三级和二级结构信息。部分资源支持直接查看三维结构、放大旋转、平移、重置视角和截图。对结构域的标注也很重要,因为同一蛋白中的不同结构域,往往承担不同功能。
此外,数据库还可能提供 PDB 和 AlphaFold 两类结构来源。PDB偏向实验解析结构,AlphaFold则提供高质量预测结构。AlphaFold 已公开超过 2 亿种蛋白结构预测,且向全球科学家免费开放。这让很多缺乏实验结构的蛋白,也能先获得结构线索。
2.2 结构注释能直接服务实验设计
结构数据库的实际用途,通常体现在三方面。
- 判断活性位点是否暴露。
- 评估突变是否可能破坏折叠。
- 选择标签插入、截短或纯化区域。
例如,结构域界面、螺旋、折叠和转角信息,能帮助你判断蛋白是否容易形成稳定复合物。对于做定点突变、蛋白纯化、构建表达载体的人来说,这类信息很实用。
当你把蛋白组数据库里的结构信息和互作信息结合起来看,很多“功能未知蛋白”就会变得有迹可循。
3. 用于序列和家族分析,判断保守性与进化关系
3.1 序列信息是所有分析的起点
蛋白组数据库 的第三类用途,是序列获取与序列比对。标准蛋白序列、异构体、长度、分子量、更新时间和校验和,这些看似基础的信息,实际上是后续分析的起点。
在 Sequence 界面,常见工具包括 BLAST、ProtParam、ProtScale、Compute pI/Mw、PeptideMass 和 PeptideCutter。也就是说,数据库不只是“看序列”,还可以直接接到理化性质、酶切、分子量和等电点分析。
对于做实验的人,这一步常用于:
- 设计引物或表达构建。
- 评估蛋白分子量是否符合胶图结果。
- 预测蛋白切割位点和消化片段。
- 比较不同异构体的序列差异。
3.2 家族与同源数据库帮助你看“共性”
如果你研究的是某个蛋白家族,蛋白组数据库还能连接到家族、结构域和同源性资源。例如 GeneTree、HOGENOM、inParanoid、OMA、OrthoDB、PhylomeDB、TreeFam 和 eggNOG,都可以帮助你判断一个蛋白在进化上的位置。
这一步特别适合以下场景:
- 想判断某个结构域是否保守。
- 想比较不同物种中的同源蛋白。
- 想从进化角度推测功能保守性。
- 想为功能注释提供间接证据。
同源性越强,功能推测通常越可靠,但仍需结合实验和文献。
4. 用于功能注释、药物发现与知识整合
4.1 把分散信息整合成可用证据链
蛋白组数据库 最容易被忽视的用途,是功能注释。一个蛋白的功能,不一定能靠单一实验完全说明。数据库会把互作、结构域、序列、复合物、同源性和文献证据放在一起,形成证据链。
这种整合对以下问题尤其有帮助:
- 一个新蛋白是否可能参与某条信号通路。
- 一个突变是否可能影响复合物组装。
- 一个靶点是否存在可成药结构区域。
- 某个蛋白是否与已知疾病机制相关。
特别是在药物发现中,BindingDB这类数据库可用于分子识别、靶点-配体关系和药理学研究。它能帮助研究者从“蛋白”进一步走向“可干预分子”。
4.2 从数据库到实验,减少试错成本
数据库给出的不是最终答案,而是实验优先级。真正高效的做法,是把数据库信息转成实验路径。
推荐顺序如下:
- 先查序列和结构域。
- 再看互作网络和复合物。
- 然后核对实验验证证据。
- 最后结合文献设计验证实验。
这样可以减少盲目试错,也能提高课题的逻辑完整度。对医学生和科研人员来说,这种路径尤其重要,因为它直接影响课题推进速度。
当你需要把碎片化蛋白信息整合成课题线索时,蛋白组数据库就是最稳妥的起点。
总结Conclusion
蛋白组数据库的4类常见用途,分别是互作研究、结构分析、序列与家族分析,以及功能注释与药物发现。 这四类用途彼此衔接,能把一个蛋白从“名字”变成“功能、结构和机制”。
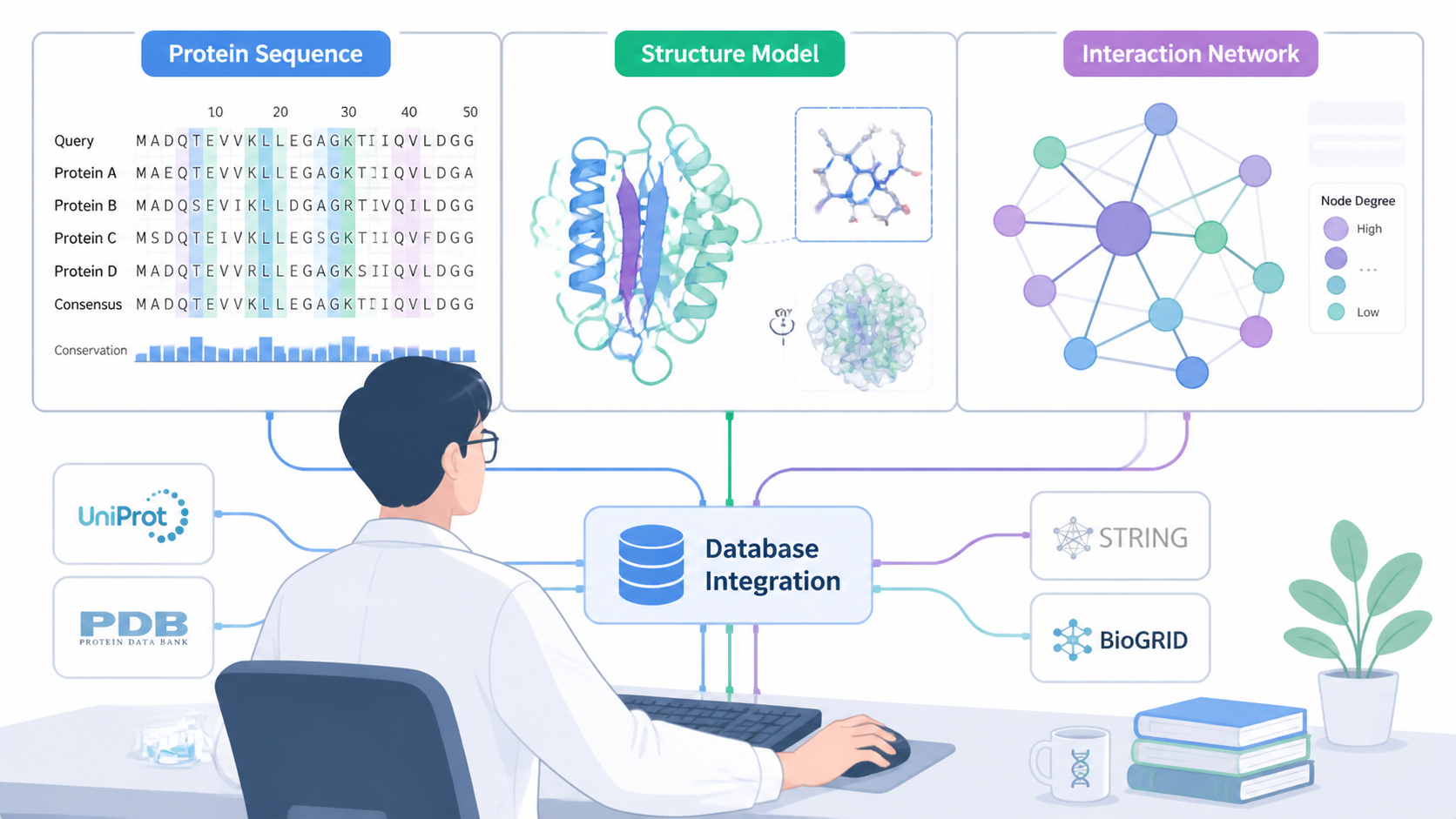
如果你正在做蛋白互作、结构注释或靶点筛选,建议直接用解螺旋整理好的工具和课程体系,减少检索成本,提升分析效率。想更快上手蛋白组数据库,选择解螺旋,会更接近真正可用的科研流程。
- 引言Introduction
- 1. 用于蛋白互作研究,定位功能网络
- 2. 用于结构研究,辅助理解蛋白功能
- 3. 用于序列和家族分析,判断保守性与进化关系
- 4. 用于功能注释、药物发现与知识整合
- 总结Conclusion