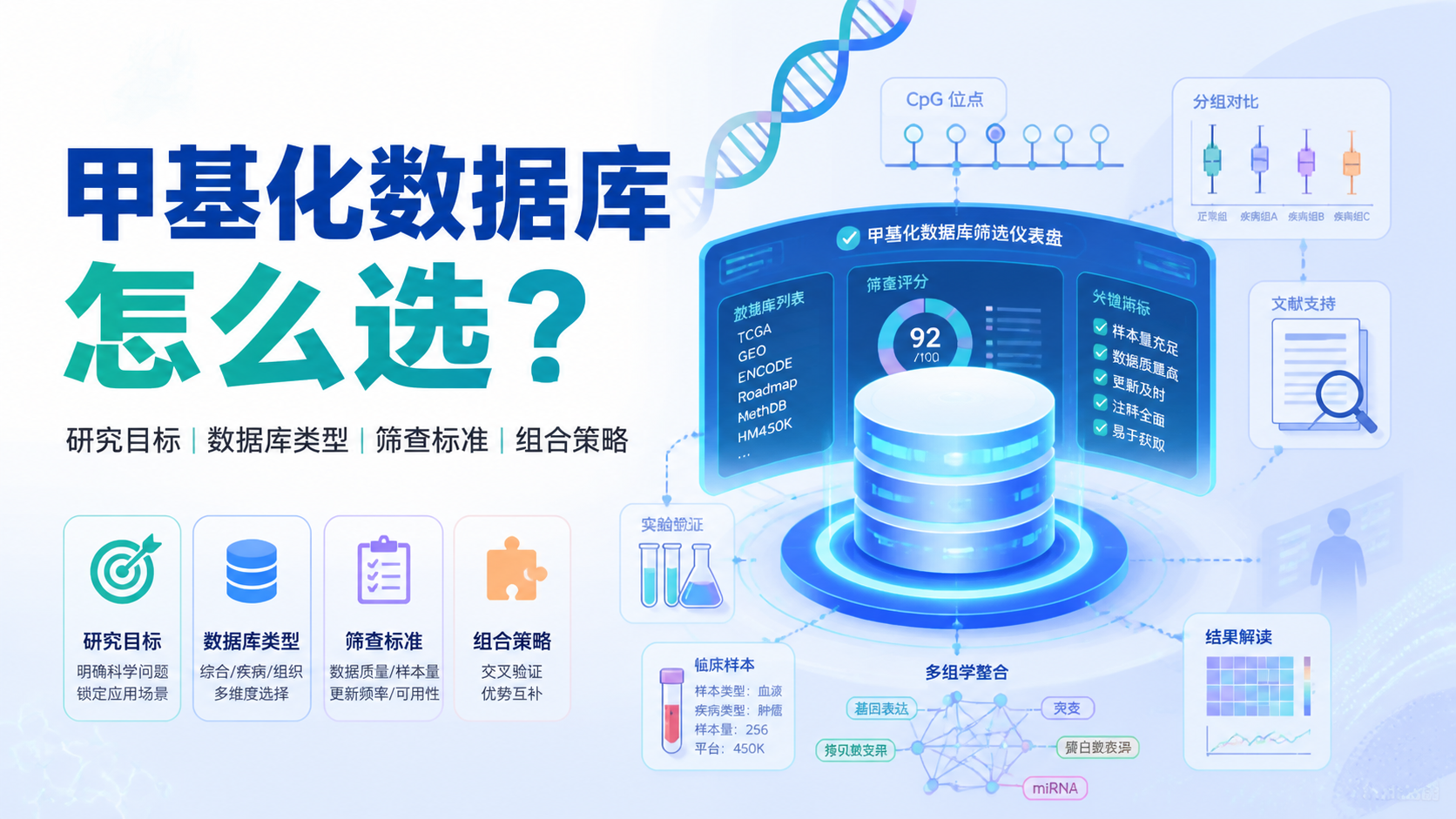
引言Introduction
表观遗传研究常卡在数据分散、样本不一致、分析门槛高。对医学生、医生和科研人员来说,表观遗传数据库 的价值,不只是“查数据”,而是快速定位可验证线索、节省实验试错成本。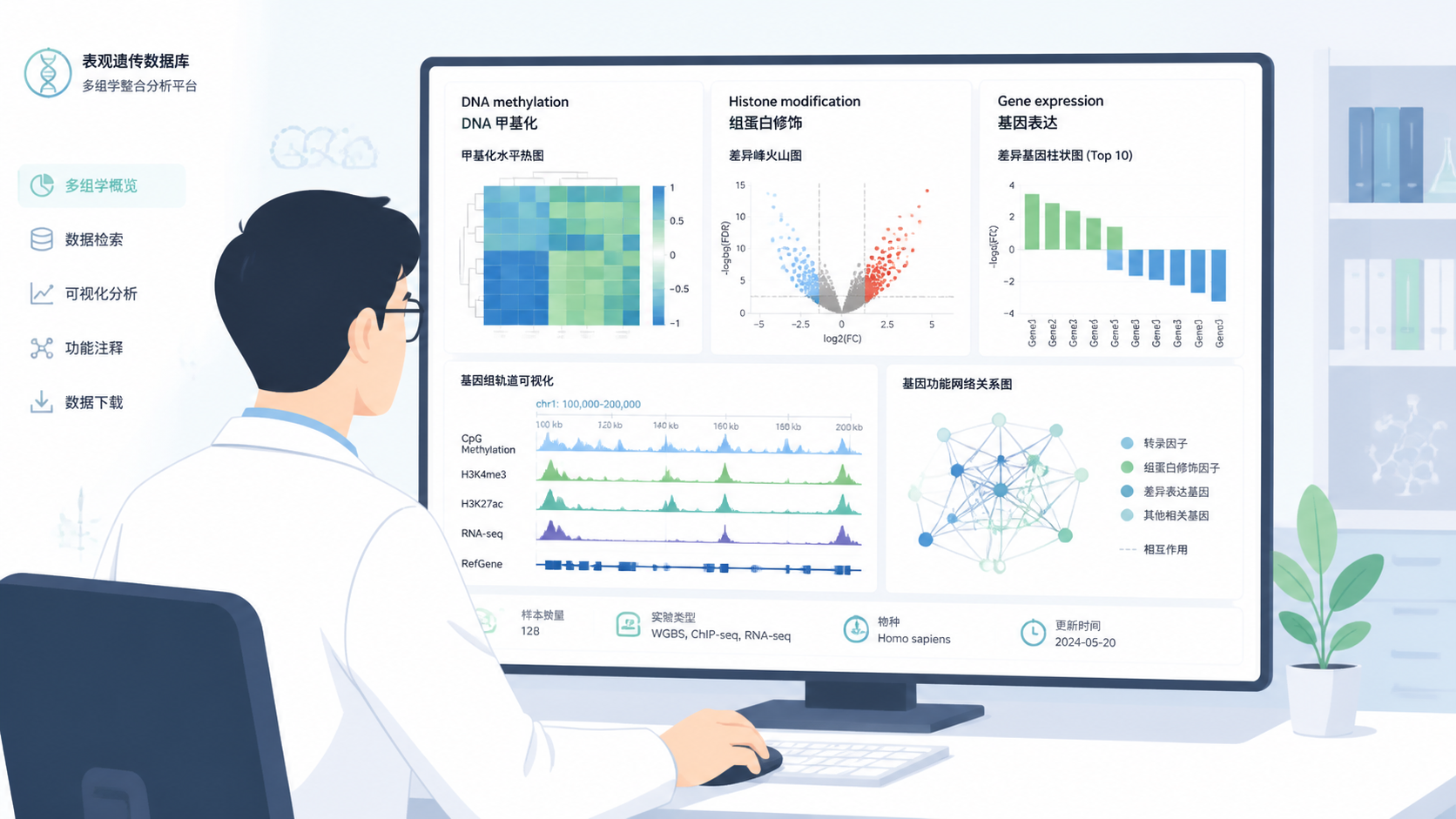
1. 表观遗传数据库能把分散信息集中到同一分析框架
1.1 从单个指标走向多维整合
表观遗传研究常见对象包括DNA甲基化、组蛋白修饰、染色质状态和相关基因表达。真正的问题不是“有没有数据”,而是数据分散在不同平台,难以统一比较。表观遗传数据库的第一大优势,是把多来源信息整合到同一入口。
以癌症研究为例,CCLE这类资源已被用于多篇顶刊工作中。研究者可以直接查看基因在不同细胞系中的表达、拷贝数变异,甚至进一步结合遗传起源信息做分析。对做机制研究的人来说,这种整合意味着可以少走很多重复建库和重复整理的弯路。
1.2 有利于快速建立研究假设
当你面对一个候选基因时,最先要回答的是它是否“值得做”。表观遗传数据库能帮助研究者先看表达分布,再看拷贝数变异,再看潜在功能背景。
这一步非常关键。它决定了后续是做机制验证,还是改题、缩小范围,避免把时间浪费在低价值靶点上。
2. 表观遗传数据库适合做“快速筛选”,提升选题效率
2.1 从3万个基因中缩小到少数候选
生信研究最忌讳的是平均用力。面对几万个基因,不可能全部深入验证。表观遗传数据库的第二大优势,是帮助你从海量分子中快速筛出候选对象。
常见做法包括单基因查询、多基因比较、差异分组分析和功能相关性分析。
例如,在CCLE中,研究者可以直接查询多个基因在不同癌细胞系中的表达差异。上游知识库中提到,RUNX1、RUNX2、RUNX3,以及CDK1、CCNB1、CCNB2、MAD2L1、TOP2A等基因,都曾被用于细胞系表达分析。这类思路非常适合前期探索。
2.2 适合做假设驱动研究
好数据库不是替代实验,而是把实验问题变得更具体。
你可以先用数据库回答以下问题:
- 候选基因在目标疾病中是否异常?
- 它在不同细胞系或样本中是否一致?
- 它是否伴随拷贝数变异或表达改变?
- 它是否可能属于某个功能模块?
这些问题一旦明确,后续的qPCR、WB、IHC、ChIP-seq或甲基化实验就更有方向。
3. 表观遗传数据库能支持多层次验证,提高结论可信度
3.1 从“单点观察”升级到“交叉验证”
科研结论最怕只靠一个证据。表观遗传数据库的第三大优势,是能把表达、拷贝数、祖源、通路和细胞系背景串联起来做交叉验证。
这比单独看一个差异表达结果更稳妥。
知识库中提到,Nature 2015 年的研究曾同时在 TCGA 和 CCLE 中查询 POLR2A 的拷贝数变异和RNA表达情况。这个例子说明,表观遗传相关分析并不是只看“修饰”本身,而是把基因组、转录组和功能背景一起看。
3.2 更接近真实研究场景
临床科研里,很多表型不是由单一因素决定。甲基化变化可能影响表达,表达变化又可能与细胞周期、凋亡或药物敏感性相关。表观遗传数据库的价值在于,它允许研究者先在公开资源中构建“证据链”,再进入实验验证。
这对医学生和临床科研人员尤其重要。因为很多课题并不具备完整多组学实验条件。数据库分析可以作为前期证据,帮助课题立项、基金申请和论文写作。
4. 表观遗传数据库降低分析门槛,适合非代码或低代码场景
4.1 不会编程也能完成基础分析
表观遗传数据库的第四大优势,是操作门槛相对低。
很多平台已提供可视化查询、结果导出和图形展示功能。对临床医生、研究生和跨学科研究者来说,这种设计能显著缩短学习曲线。
上游知识库提到,像cBioPortal、UALCAN、PRA two等平台,都能支持不同层面的数据分析。虽然它们不完全等同于表观遗传数据库,但它们体现了同一个趋势。也就是把复杂数据分析做成可视化、可复现、可直接使用的工具。
4.2 有利于标准化展示
数据库平台通常会输出标准化图形。比如箱线图、热图、分组比较图、相关性图和生存图等。这类图形最大的好处,是方便论文呈现,也方便同行复核。
对于投稿而言,标准化输出能减少“图不够规范”“方法不清楚”的问题。对做课题的人来说,规范比复杂更重要。
5. 表观遗传数据库能直接服务于论文、课题和转化研究
5.1 适合论文选题和机制铺垫
表观遗传数据库的第五大优势,是能直接服务于发文和课题设计。
上游知识库明确提到,公共数据挖掘可用于省级课题申请,也可为病理切片和后续实验提供依据。对于科研人员来说,这意味着数据库不仅是“检索工具”,还是“选题工具”和“证据工具”。
如果你想做一篇机制文章,数据库能先帮你回答三件事:
- 这个分子是否值得研究。
- 它可能和什么功能相关。
- 它在不同样本中的变化是否有一致性。
这三步完成后,文章框架会清晰很多。
5.2 更容易形成“数据库筛选+实验验证”的完整链条
当前较受认可的研究路径,往往不是单纯的数据库描述,而是“公开数据库筛选,实验验证补强”。
表观遗传数据库正好位于这个链条的前端。
它帮助你先筛假设,再做验证,再补机制。这样更符合E-E-A-T逻辑,也更符合高质量论文的证据层级。
总结Conclusion
表观遗传数据库的5大核心优势,可以概括为:整合数据、快速筛选、交叉验证、降低门槛、服务转化。
对于医学生、医生和科研人员而言,它的意义不只是“查一查”,而是把复杂的表观遗传问题变成可操作、可验证、可发表的研究路径。
如果你正在寻找更高效的数据库检索、图形分析和课题设计支持,可以进一步借助解螺旋 的科研服务与资源体系,把公开数据真正转化为选题、文章和课题成果。
- 引言Introduction
- 1. 表观遗传数据库能把分散信息集中到同一分析框架
- 2. 表观遗传数据库适合做“快速筛选”,提升选题效率
- 3. 表观遗传数据库能支持多层次验证,提高结论可信度
- 4. 表观遗传数据库降低分析门槛,适合非代码或低代码场景
- 5. 表观遗传数据库能直接服务于论文、课题和转化研究
- 总结Conclusion