






引言Introduction
做分子对接时,很多人卡在第一步。PDB数据库条目多,筛选条件杂,稍不注意就会选错蛋白结构,影响后续建模和结果可靠性。掌握PDB数据库的高效检索方法,是分子模拟入门的关键。
1. 先明确检索目标,避免无效搜索
1.1 先锁定蛋白名称和物种
使用PDB数据库前,第一步不是直接搜索,而是先明确三个信息:蛋白名称、物种、用途。比如是人源c-src,还是其他物种同源蛋白。同名蛋白在不同物种中的结构差异,可能直接影响后续对接结果。
如果目标蛋白有多个结构,建议先从文献或UniProt确认标准名称,再回到PDB数据库检索。这样能减少检索噪音,也更容易筛到与研究问题匹配的结构。
1.2 了解PDB检索字段
PDB数据库支持按关键词搜索,也支持按结构编号、作者、分辨率等条件筛选。对科研人员来说,最常用的是:
- 蛋白名称搜索
- 物种筛选
- 分辨率筛选
- 结构状态筛选
分辨率越小,通常结构越清晰。 例如1.31 Å的结构一般优于2.5 Å的结构,但是否可用,还要看是否包含你需要的结合位点。
1.3 先看结果数量,再决定筛选策略
以“c-src”为例,PDB数据库可能返回数百个结构。此时不要逐个点开。应先用左侧筛选栏缩小范围,再查看候选结果。常见做法是先限定物种为Homo sapiens,再按分辨率排序。这样效率更高,也更符合分子对接前的结构选择逻辑。
2. 按标准筛选高质量结构
2.1 优先看分辨率和物种一致性
在PDB数据库中,分辨率是最基础的质量指标之一。通常建议优先考虑高分辨率结构。对于人源药靶,最好选择物种一致的条目,避免跨物种结构带来的偏差。
但分辨率不是唯一标准。 有些结构分辨率很高,却缺少关键残基,或者结合口袋不完整。研究者必须结合功能位点一起判断。
2.2 检查结构是否包含目标结合位点
很多人只看分辨率,不看位置编号和序列覆盖区间,这是常见误区。PDB数据库中的“Positions”或序列区段信息,能告诉你该结构覆盖了哪些氨基酸残基。
如果结构中没有包含目标活性位点,即使整体分辨率很好,也未必适合分子对接。此时应优先选择:
- 覆盖更完整的结构
- 已结合过类似配体的结构
- 文献已验证可用于对接的结构
2.3 下载前先判断是否需要处理配体和水分子
很多PDB数据库结构会带有原始配体、水分子或重复链。对接前通常需要清理这些内容。常规做法是:
- 保留目标蛋白链
- 删除无关水分子
- 删除重复链或无关小分子
- 视需要保留关键金属离子
去水并不是绝对规则。 如果某些水分子参与关键氢键网络,就不应直接删除。是否保留,应结合文献和位点功能判断。
3. 下载与预处理,直接进入后续分析
3.1 在PDB数据库下载标准格式文件
筛选到合适结构后,可直接进入条目页面下载PDB格式文件。这个文件是后续PyMOL、Discovery Studio、AutoDock等软件处理的基础输入。
推荐下载前再次确认:
- 结构编号
- 物种来源
- 分辨率
- 是否含配体
- 是否含突变信息
下载前多看30秒,能少返工30分钟。
3.2 常用的预处理流程
拿到PDB文件后,通常要进行以下处理:
- 删除水分子
- 删除多余链
- 检查是否有缺失残基
- 加氢
- 转换为对接所需格式,如PDBQT
以AutoDock流程为例,蛋白晶体结构通常缺少氢原子,但静电作用计算又需要氢信息,因此加氢是必要步骤。随后再导出为PDBQT文件,才能进入对接计算。
3.3 配合UniProt和文献,提高结构选择准确率
如果PDB数据库里同一蛋白有多个条目,不要只看标题。可先到UniProt确认蛋白信息,再回到PDB数据库比对结构来源和功能区段。必要时结合文献判断哪个条目更适合当前研究。
这一步对医学生、医生和科研人员都很重要。因为结构选错,会影响后续:
- 配体结合位点判断
- 分子对接打分
- 结果解释
- 论文结论可信度
4. 提升PDB数据库使用效率的实战技巧
4.1 用“筛选+验证”代替“盲搜”
高效使用PDB数据库的核心,不是搜索速度,而是筛选逻辑。建议按以下顺序处理:
- 搜索蛋白名称
- 限定物种
- 按分辨率排序
- 查看序列覆盖和位点
- 结合文献确认可用性
这样能快速缩小候选范围,避免在低质量条目上浪费时间。
4.2 和其他数据库联动使用
PDB数据库并不是独立工作的。实际研究中,常和UniProt、PubChem、SwissTargetPrediction等数据库联动。比如:
- 用UniProt确认蛋白标准名称
- 用PDB数据库获取三维结构
- 用PubChem获取配体结构
- 用对接软件验证相互作用
单一数据库只解决“找得到”,联动使用才能解决“用得对”。
4.3 关注结构是否适合你的研究目的
不同目的,对PDB数据库结构的要求不同。比如:
- 机制研究,重视结合位点和构象完整性
- 药物筛选,重视分辨率和口袋可用性
- 发表论文,重视结构来源和文献支持
因此,不存在“最好”的统一结构,只有“最适合当前问题”的结构。
总结Conclusion
PDB数据库的使用并不复杂,关键在于方法。你只要记住三步就够了:先明确目标蛋白和物种,再用分辨率、位点和覆盖区间筛选,最后下载并完成标准化预处理。 对分子对接和结构生物学研究来说,这套流程能显著提高效率和结果可信度。
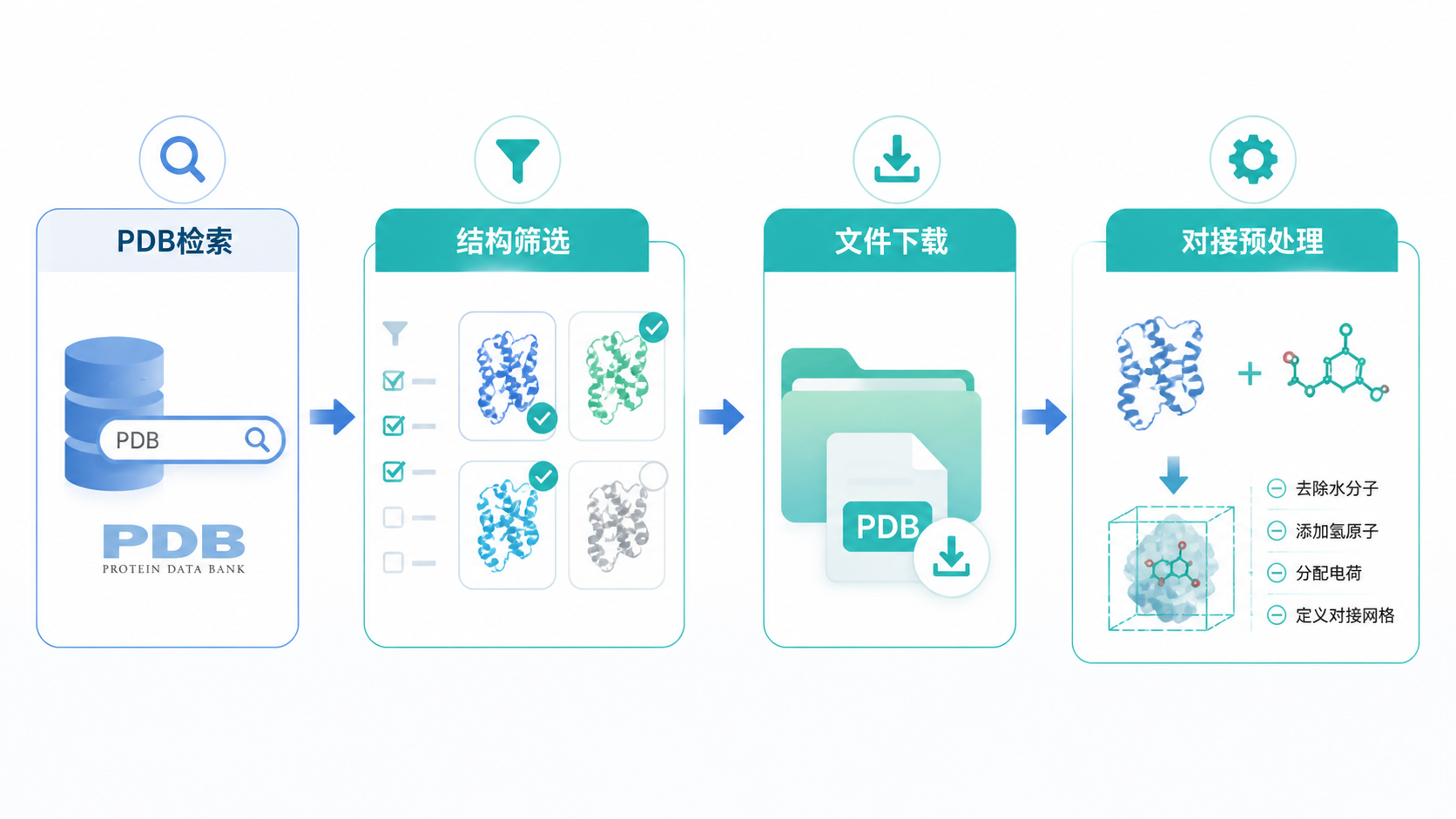
如果你希望更快上手PDB数据库,并把结构筛选、靶点确认、对接准备串成一套完整流程,可以进一步使用解螺旋 的专业工具与内容支持,减少重复操作,提高研究效率。
- 引言Introduction
- 1. 先明确检索目标,避免无效搜索
- 2. 按标准筛选高质量结构
- 3. 下载与预处理,直接进入后续分析
- 4. 提升PDB数据库使用效率的实战技巧
- 总结Conclusion



