






引言Introduction
如果你正在查蛋白功能、注释或序列信息,SwissProt数据库 通常是最值得先看的入口。它的问题也很明确,信息太多、界面更新后不熟、检索结果不知道怎么筛。本文用3步带你快速上手,适合医学生、医生和科研人员。
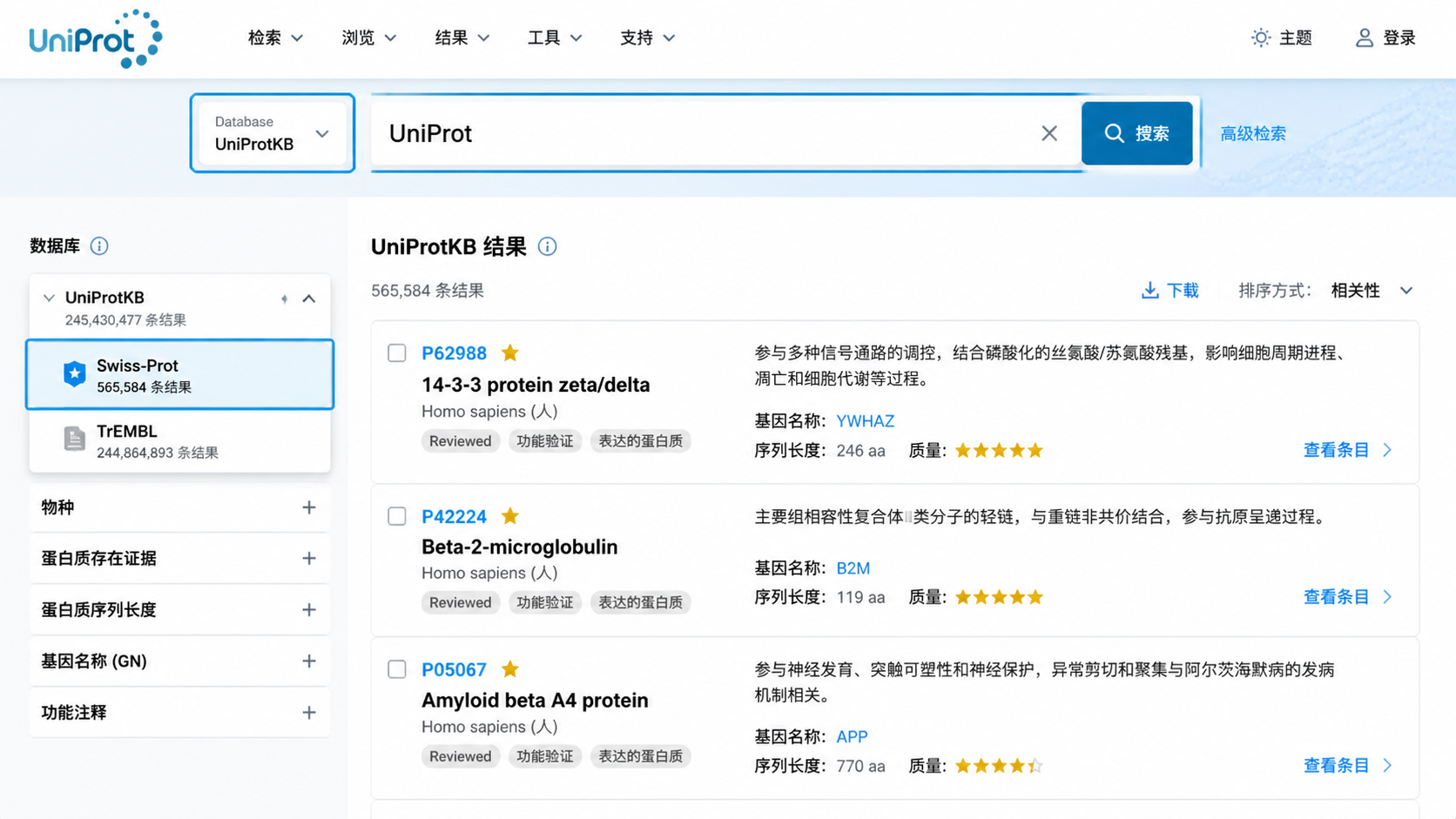
1.SwissProt数据库是什么,为什么先用它
1.1 它是人工审核过的高可信蛋白库
SwissProt数据库 是 UniProtKB 的人工审核子库。和自动注释库相比,它的优势在于条目经过人工整理,非冗余,注释更完整。对于做机制研究、靶点确认、蛋白功能梳理的人来说,这种高可信度很重要。
知识库信息显示,UniProt 是查询蛋白功能的首选数据库,而 Swiss-Prot 侧重于高质量注释。也就是说,当你需要更稳妥的蛋白信息时,SwissProt数据库 通常优先于未审核条目。
1.2 适合哪些场景
SwissProt数据库 特别适合以下任务:
- 查询蛋白功能、亚细胞定位、疾病关联。
- 追踪文献引用与交叉数据库链接。
- 进行实验设计前的蛋白背景核查。
- 为多肽、抗体或突变设计提供序列依据。
如果你面对的是基因组学、蛋白组学或转化医学项目,先查 Swiss-Prot 往往能减少后续反复核对的成本。
1.3 和 TrEMBL 的区别要先分清
UniProtKB 由 Swiss-Prot 和 TrEMBL 构成。前者是人工核对过的高质量条目,后者包含未核对蛋白数据。
简单理解,SwissProt数据库更适合优先阅读,TrEMBL更适合补充覆盖范围。
这也是很多研究者一开始就锁定 Swiss-Prot 的原因。先看高质量信息,再决定是否扩展到更大范围的条目。
2.第1步:在 UniProt 中准确找到 SwissProt数据库
2.1 新版界面先选数据库,再检索
新版 UniProt 页面上,第一步是先选择数据库,再输入检索内容。你可以输入蛋白名、基因名、UniProt ID,或物种信息,例如 Human、organism_id:9606 等。
然后点击 search 即可。
检索时建议先明确“目标对象”再搜索。 比如你想查人类胰岛素,就不要只输英文通用名,也可以结合物种限定,减少噪音结果。
2.2 用过滤条件缩小到 Swiss-Prot
检索结果出来后,要确认筛到的是 SwissProt数据库 条目。UniProt 界面中有 Swiss-Prot 子数据库入口,可帮助你直接定位人工审核条目。
实操上可以这样做:
- 输入目标蛋白或关键词。
- 在结果页面查看是否属于 UniProtKB。
- 优先筛选 Swiss-Prot 条目。
- 再进入具体蛋白详情页。
这样做的好处是减少误读未审核条目的风险。对于需要写论文、做汇报或设计实验的人,这一步很关键。
2.3 检索时尽量用标准标识符
知识库中提到,UniProt 支持多种输入形式,包括蛋白名、物种信息和标识符。它还支持 ID 转换。
但在实际使用中,标准 UniProt ID 往往最稳定 。如果你手上是其他数据库的编号,也可以先做 ID mapping,再进入 SwissProt数据库 查看对应条目。
这对跨数据库整合非常重要。尤其是做蛋白组学、通路分析、公共数据库整合时,统一 ID 能显著减少出错率。
3.第2步:读懂 SwissProt数据库条目页的核心信息
3.1 先看功能注释,再看证据来源
进入某个蛋白条目后,先不要急着看全部内容。最该优先看的,是功能注释、蛋白名称、基因名、物种来源和证据类型。
SwissProt数据库的优势就在于注释更完整。 条目通常会包含以下内容:
- 蛋白基本信息。
- 功能描述。
- 文献引用。
- 交叉引用数据库。
- 疾病相关信息。
- 亚细胞定位。
这些信息能帮助你快速判断这个蛋白是否适合进入后续实验设计。
3.2 重点关注疾病和定位信息
知识库显示,UniProt 还提供 Human Diseases 和 Subcellular locations 等分类入口。
这意味着你在 SwissProt数据库 中不仅能看蛋白本身,还能看到它和疾病、细胞定位的关系。
对临床相关研究尤其有价值。比如你在做肿瘤、代谢病或神经疾病研究时,可以先看该蛋白是否已有疾病注释,再决定是否纳入研究重点。
3.3 看交叉引用,能快速扩展到结构和通路
条目页里的交叉引用数据库,是很实用的功能。它能直接跳到 2D 凝胶、3D 结构、化学数据库、酶和通路数据库等。
这一步能帮你把 SwissProt数据库从“查信息”变成“建研究链条”。
你可以沿着一个蛋白,继续找到结构、通路和文献证据,形成更完整的研究背景。
4.第3步:用 SwissProt数据库的实用工具提高效率
4.1 BLAST 适合查同源序列
如果你要验证某条氨基酸序列是否具有同源性,UniProt 提供 BLAST 功能。知识库明确提到,这个模块适合在设计多肽时判断物种界限和序列特异性。
使用时可直接输入 UniProt ID 或序列,运行后查看匹配结果。
对于做抗体、多肽或保守位点分析的人,这一步非常实用。
4.2 Align 适合做序列比对
Align 功能用于比较多个蛋白序列的同源性。它通常用于进一步判断保守区域、变异位点和物种差异。
如果你的研究涉及比较不同物种的同源蛋白,SwissProt数据库 配合 Align 会很高效。
这类分析适合用于:
- 保守结构域筛选。
- 进化关系比较。
- 突变位点设计。
- 物种间功能保守性判断。
4.3 Peptide Search 和 ID mapping 也很常用
Peptide Search 可以输入一段肽序列,查找可能包含该肽段的蛋白。知识库提示,单个序列至少包含 2 个氨基酸。
这对蛋白组学、质谱结果验证非常有帮助。
ID mapping 则用于不同数据库标识符之间转换。
如果你正在整理多源数据,SwissProt数据库配合 ID 转换能显著减少人工对照时间。
5.实战建议:让 SwissProt数据库真正服务于科研
5.1 先筛高质量条目,再扩展范围
推荐的流程是:
- 先在 SwissProt数据库 中查人工审核条目。
- 再查看相关文献和交叉数据库。
- 如果需要更大覆盖面,再补充 TrEMBL。
- 最后用 BLAST、Align 或 ID mapping 做验证。
这个顺序更稳妥,也更适合论文写作和实验设计。
5.2 记录检索路径,方便复现
科研场景里,检索不是一次性动作。
建议保留你在 SwissProt数据库中的检索词、过滤条件、UniProt ID 和结果截图。 这样后续写方法部分、做补充材料或答辩时都能快速复现。
5.3 常见误区要避免
很多人使用 UniProt 时,会忽略以下问题:
- 只看蛋白名,不看物种。
- 不区分 Swiss-Prot 和 TrEMBL。
- 不做 ID 转换,直接跨库比对。
- 只看一条结果,不核对注释来源。
这些错误会影响结果可靠性。对于医学生和科研人员来说,SwissProt数据库的价值就在于“先查准,再查全”。
总结Conclusion
SwissProt数据库是 UniProt 中最适合优先使用的高质量蛋白资源。 只要掌握“检索、阅读、扩展”这3步,你就能快速找到可靠的蛋白功能、疾病、定位和同源信息。对于需要做文献核查、实验设计和数据整合的医学生、医生和科研人员来说,它能明显提升效率。
如果你希望把 SwissProt数据库用得更快、更规范,可以进一步借助解螺旋 提供的生信学习与研究支持,帮助你把数据库检索真正转化为科研产出。

- 引言Introduction
- 1.SwissProt数据库是什么,为什么先用它
- 2.第1步:在 UniProt 中准确找到 SwissProt数据库
- 3.第2步:读懂 SwissProt数据库条目页的核心信息
- 4.第3步:用 SwissProt数据库的实用工具提高效率
- 5.实战建议:让 SwissProt数据库真正服务于科研
- 总结Conclusion



