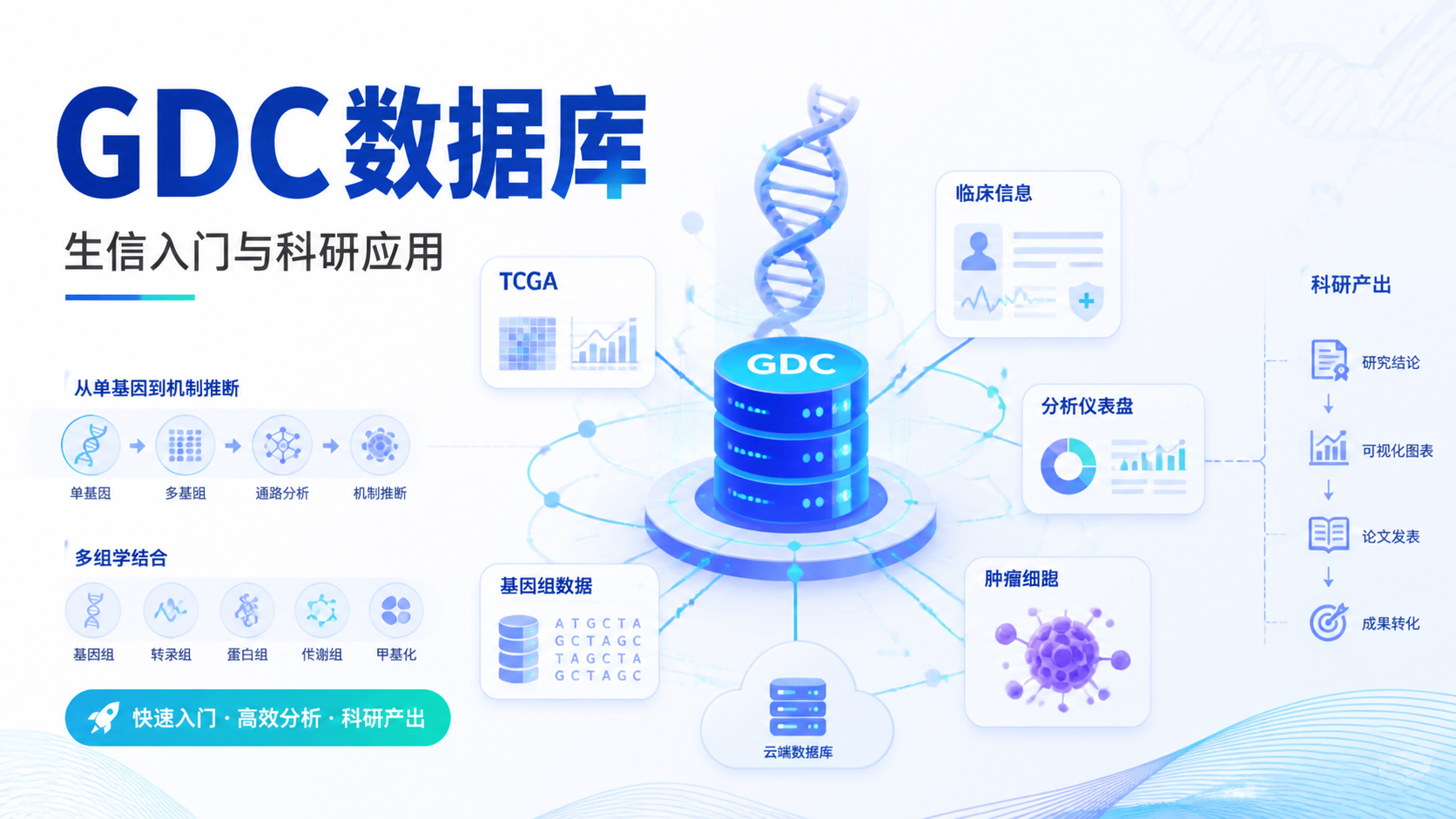
引言Introduction
CCLE数据库怎么用,是很多医学生和科研人员在做肿瘤机制、药物筛选时最先遇到的问题。数据多、入口杂、指标多,容易看不懂,也容易查偏。掌握CCLE数据库的专业检索方法,能让你更快锁定基因表达、突变和拷贝数信息。
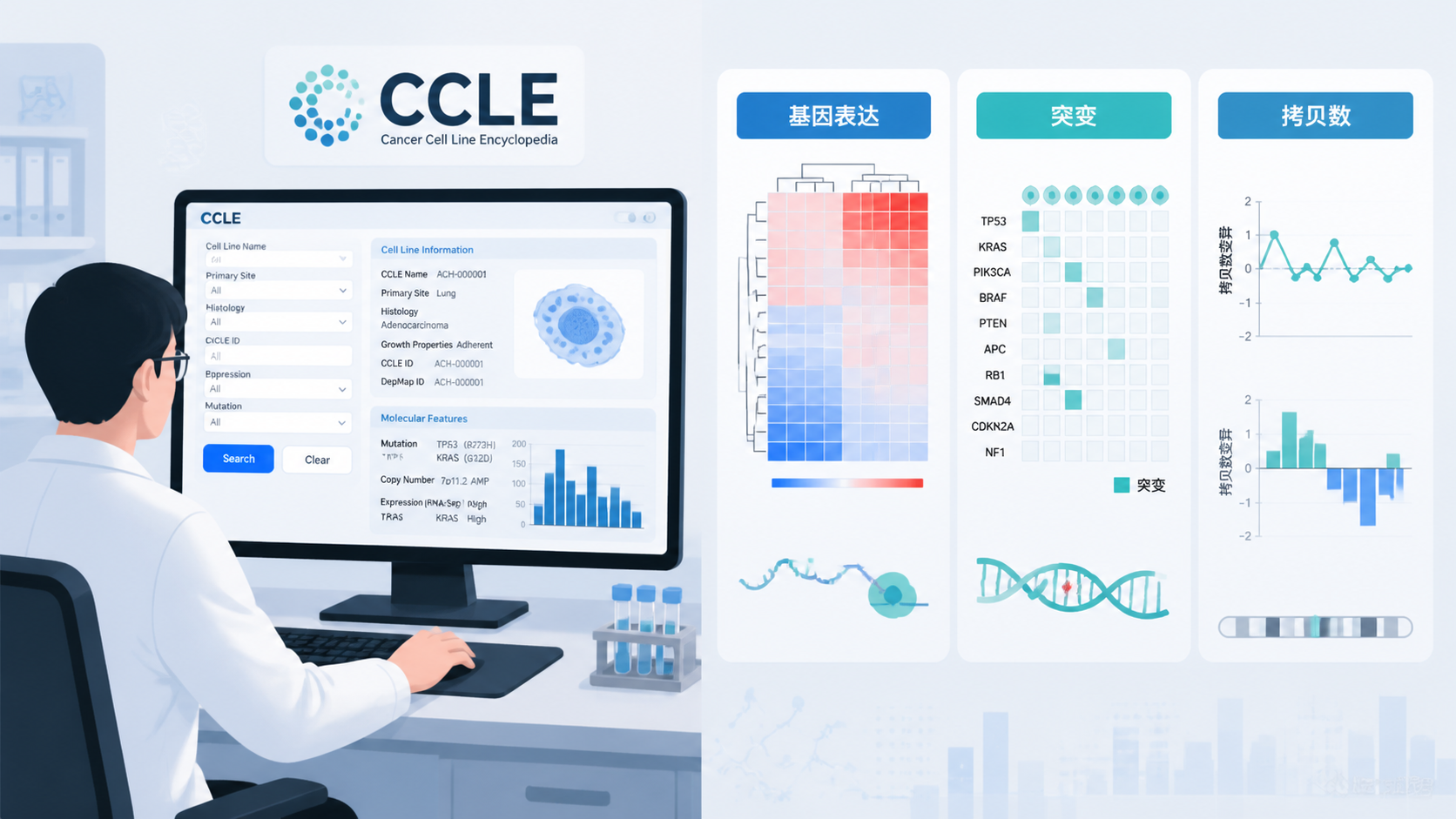
1. 先理解CCLE数据库的核心价值
1.1 CCLE数据库是什么
CCLE,全称 Cancer Cell Line Encyclopedia,中文可理解为癌症细胞系百科全书。它由 Broad 研究所、Dana-Farber 癌症研究所和 Novartis 生物医学研究所等团队合作建立,目标是系统描绘癌细胞系的遗传特征。
CCLE数据库的基础资源来自2012年对30多种组织来源、947种人类癌细胞系的大规模深度测序。 后续又不断扩展,2019年《Nature》发布的新一代百科全书进一步更新了1000多个细胞系的多组学数据,包括遗传突变、RNA剪接、DNA甲基化、组蛋白修饰、microRNA表达和蛋白质表达。
1.2 它为什么值得学
对科研人员来说,CCLE数据库的价值不只是“能查数据”。它更重要的作用是把多个层面的信息放在同一平台上,便于做横向比较和机制验证。
常见用途包括:
- 查询单个基因在不同细胞系中的表达
- 查看突变、拷贝数变异、甲基化状态
- 做结果可视化,快速生成条形图、散点图、气泡图
- 为抗癌药物靶点筛选提供基础证据
如果你的研究涉及肿瘤细胞模型选择、候选基因验证或药物敏感性分析,CCLE数据库几乎是必学工具。
2. 第一步,明确你要查什么
2.1 先定研究问题,再进库检索
很多人一开始就直接搜基因名,结果只看到一堆图,不知道该看哪一项。更有效的方法是先把问题拆成三类。
你可以先问自己:
- 这个基因在不同细胞系里表达高不高。
- 这个基因有没有突变或拷贝数异常。
- 这个基因是否存在甲基化或蛋白表达层面的变化。
CCLE数据库的专业检索,本质上是“先定指标,再定细胞系,再看数据类型”。 这样能减少无效浏览。
2.2 认识CCLE数据库里的主要数据类型
CCLE网站支持多种数据展示方式,常见的有:
- Copy Number,拷贝数
- mRNA表达(Affy),芯片数据
- RPPA,反向蛋白阵列数据
- RRBS,DNA甲基化相关数据
- mRNA表达(RNAseq),转录组测序数据
这些数据并不是重复,而是从不同层面描述同一批细胞系。同一个基因在RNA水平高表达,不一定代表蛋白水平也高。 所以做论文时,最好结合多个维度一起看。
3. 第二步,学会CCLE数据库的专业检索路径
3.1 单基因检索怎么做
CCLE数据库最常用的入口,就是查单个基因在多个细胞系中的分布。你只需要输入基因符号,就能看到该基因在不同癌细胞系中的表达、拷贝数或甲基化变化。
例如,很多研究会用 CCLE 数据查看 RUNX1、CDK1、TOP2A 等基因在不同肿瘤细胞系中的表达情况。数据库支持条形图、散点图和气泡图展示,适合快速筛选候选基因。
检索时最重要的是统一基因命名,优先使用标准基因符号。 否则很容易因别名混淆而漏掉结果。
3.2 看表达、拷贝数和突变时要注意什么
不同模块对应不同问题,不能混用。
可按下面思路判断:
- 研究转录水平,优先看 RNAseq 或 Affy
- 研究基因剂量效应,优先看 Copy Number
- 研究蛋白变化,优先看 RPPA
- 研究表观调控,优先看 RRBS 或甲基化相关图谱
- 研究结构性改变,查看单细胞系突变数据
专业检索不是把所有图都点一遍,而是让数据类型服务于研究假设。
3.3 如何提高检索效率
建议按以下顺序操作:
- 先输入目标基因。
- 再切换数据类型。
- 观察不同癌种或细胞系的分布。
- 下载或截图关键结果,进入后续分析。
如果你要比较多个基因,可以先列出候选列表,再逐个查看。对于后续文章写作,优先保留数据趋势清晰、差异明显的结果。
4. 第三步,把检索结果转化为论文证据
4.1 CCLE数据库常见应用场景
CCLE数据库之所以常被引用,是因为它能直接支撑“候选基因在细胞系中的表达或异常改变”这一类证据链。
上游知识库中的文献应用很典型:
- 用 RUNX 家族基因分析白血病细胞系表达
- 用 CDK1、CCNB1、TOP2A 等 Hub 基因分析多细胞系表达
- 用 POLR2A 结合 TCGA 和 CCLE 比较拷贝数与表达
- 用 1393 个癌细胞系数据估算遗传祖源
这些案例说明,CCLE数据库非常适合做从“筛选”到“验证”的第一步。
4.2 论文里怎么写才更规范
写作时建议注意三点:
- 说明所用数据类型,如 RNAseq、Copy Number 或 RPPA
- 说明所分析的细胞系范围
- 说明结果用途,是筛选、验证还是比较分析
这样写比简单写“我们使用CCLE数据库分析基因表达”更专业。方法部分越清楚,结果越可信。
4.3 与其他数据库联合使用
CCLE数据库和 TCGA 是互补关系。TCGA 更偏向临床样本,CCLE 更适合细胞模型。两者联合使用时,可以形成“临床发现—细胞验证”的闭环。
对于做机制研究和精准医学方向的团队来说,这种组合比单独使用一个数据库更有说服力。
5. 进阶建议:把CCLE数据库用得更像“科研工具”
5.1 不只看结果,也要看数据来源
CCLE数据库的优势在于公开共享和多组学整合,但科研使用时仍要关注数据来源和更新时间。知识库显示,网站会不定期更新,最近一次更新时间为2020年。
这意味着你在写文章时,最好注明所用版本或检索时间。时间点清楚,结果才更容易复现。
5.2 结果解释要避免过度推断
CCLE数据库提供的是细胞系层面的组学信息,不等同于临床结论。它能帮助你提出假设,但不能直接替代实验验证。
更稳妥的表述是:
- “提示该基因在某些细胞系中存在高表达”
- “支持该基因可能与拷贝数变化相关”
- “为后续功能实验提供依据”
这样更符合科研写作规范,也更符合 E-E-A-T 原则。
总结Conclusion
CCLE数据库怎么用,核心就是三步。先明确研究问题,再选择合适的数据类型,最后把结果转化为可用于论文和实验设计的证据。 对医学生、医生和科研人员来说,CCLE数据库最有价值的地方,是帮助你快速完成肿瘤细胞系层面的基因表达、突变、拷贝数和甲基化检索。
如果你希望把检索做得更快、更稳、更适合论文产出,建议直接结合解螺旋的数据库与科研内容服务,减少无效试错,把时间用在真正的机制分析和实验设计上。
- 引言Introduction
- 1. 先理解CCLE数据库的核心价值
- 2. 第一步,明确你要查什么
- 3. 第二步,学会CCLE数据库的专业检索路径
- 4. 第三步,把检索结果转化为论文证据
- 5. 进阶建议:把CCLE数据库用得更像“科研工具”
- 总结Conclusion