引言Introduction
GDC数据库 已经是肿瘤生信研究中绕不开的核心资源。很多医学生、医生和科研人员的问题不是“要不要用”,而是“怎么用得更快、更准”。面对海量TCGA数据、临床信息和多组学结果,如果不会筛选、整理和分析,研究进度很容易卡住。
1.GDC数据库是什么,为什么重要
1.1GDC数据库的核心定位
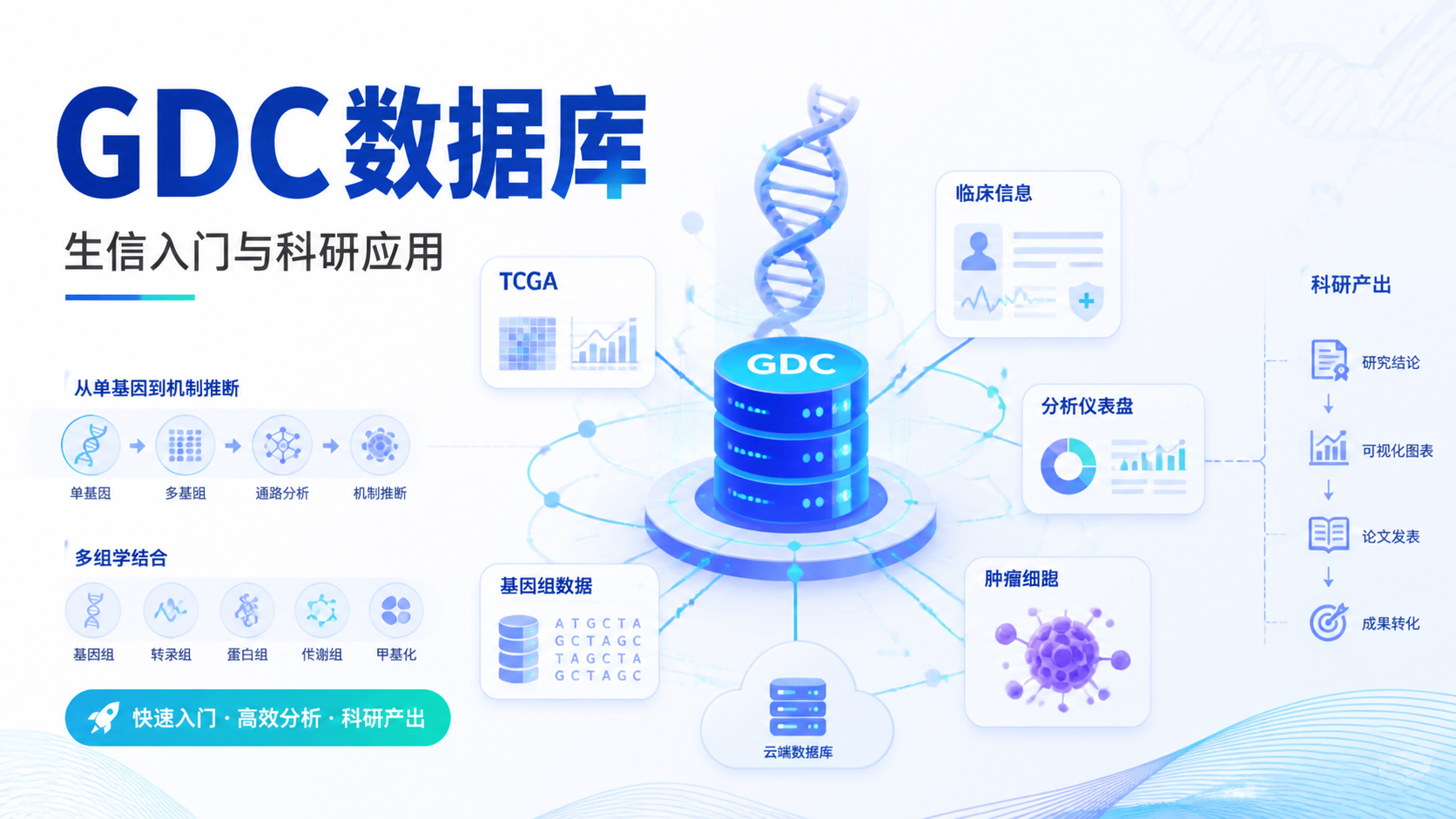
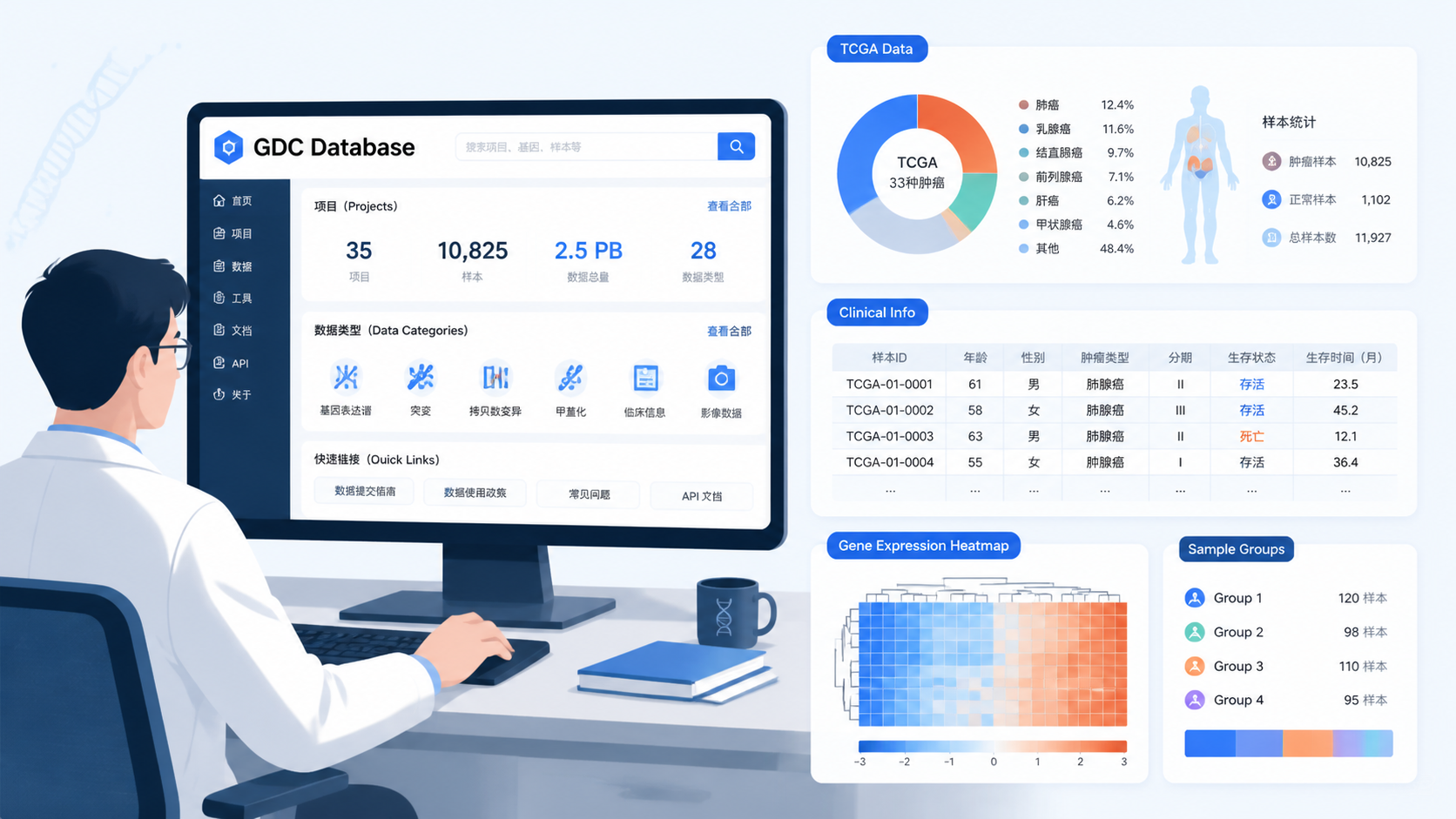
GDC数据库,全称Genomic Data Commons,是面向癌症研究的基因组数据平台。它的价值,在于把分散的肿瘤相关数据集中到统一框架中,便于检索、下载和再分析。对于生信研究者来说,这意味着更高的数据可获得性和更低的入门门槛。
GDC数据库最核心的意义,不是“有数据”,而是“数据标准化”。 统一的数据组织方式,能减少不同项目之间的处理偏差,让后续分析更可重复。这一点对医学生和科研人员尤其重要,因为发表文章时,方法学的规范性直接影响可信度。
1.2从科研效率看GDC数据库的优势
在课程内容中,生信被反复强调为一种“快速取得成果”的研究方式。GDC数据库正是这种思路的典型代表。你不必从零开始做大规模样本收集,也不必等待漫长的实验周期,就能进入真实世界级别的数据分析阶段。
对于时间有限、但需要尽快推进课题的临床科研人群,GDC数据库能显著提升效率。 它适合做差异分析、生存分析、预后建模、分型研究等常见主题。尤其在肿瘤方向,公共数据挖掘已经成为高频策略。
2.GDC数据库适合哪些生信研究场景
2.1肿瘤相关问题的高频应用
GDC数据库最常见的用途,是围绕肿瘤表达谱和临床结局展开分析。比如,研究某个基因在不同癌种中的表达差异,或评估其与生存期、分期、分级之间的关系。这些问题结构清晰,适合形成完整的文章逻辑。
课程知识库提到,单基因研究、火山图、热图、互作网络、预后分析 ,仍然是很多课题的基础骨架。若再结合临床变量和外部验证,文章的完整度会明显提升。对初学者而言,这类分析路径相对稳定,易于复现。
2.2与TCGA、临床信息联动分析
GDC数据库最实用的地方,在于它不仅有组学数据,还有对应的临床注释。你可以把表达数据与年龄、性别、分期、治疗信息等变量联动起来分析。这样得到的结果,不只是“基因变了”,而是进一步回答“它和患者结局有什么关系”。
这种“分子数据加临床数据”的组合,是GDC数据库高价值的关键。 它让生信结果更贴近临床问题,也更符合医学生和临床医生的研究逻辑。很多高质量文章,本质上就是把公共数据做深、做透,再加上合理的临床解释。
3.GDC数据库研究常用的分析思路
3.1从单基因到机制推断
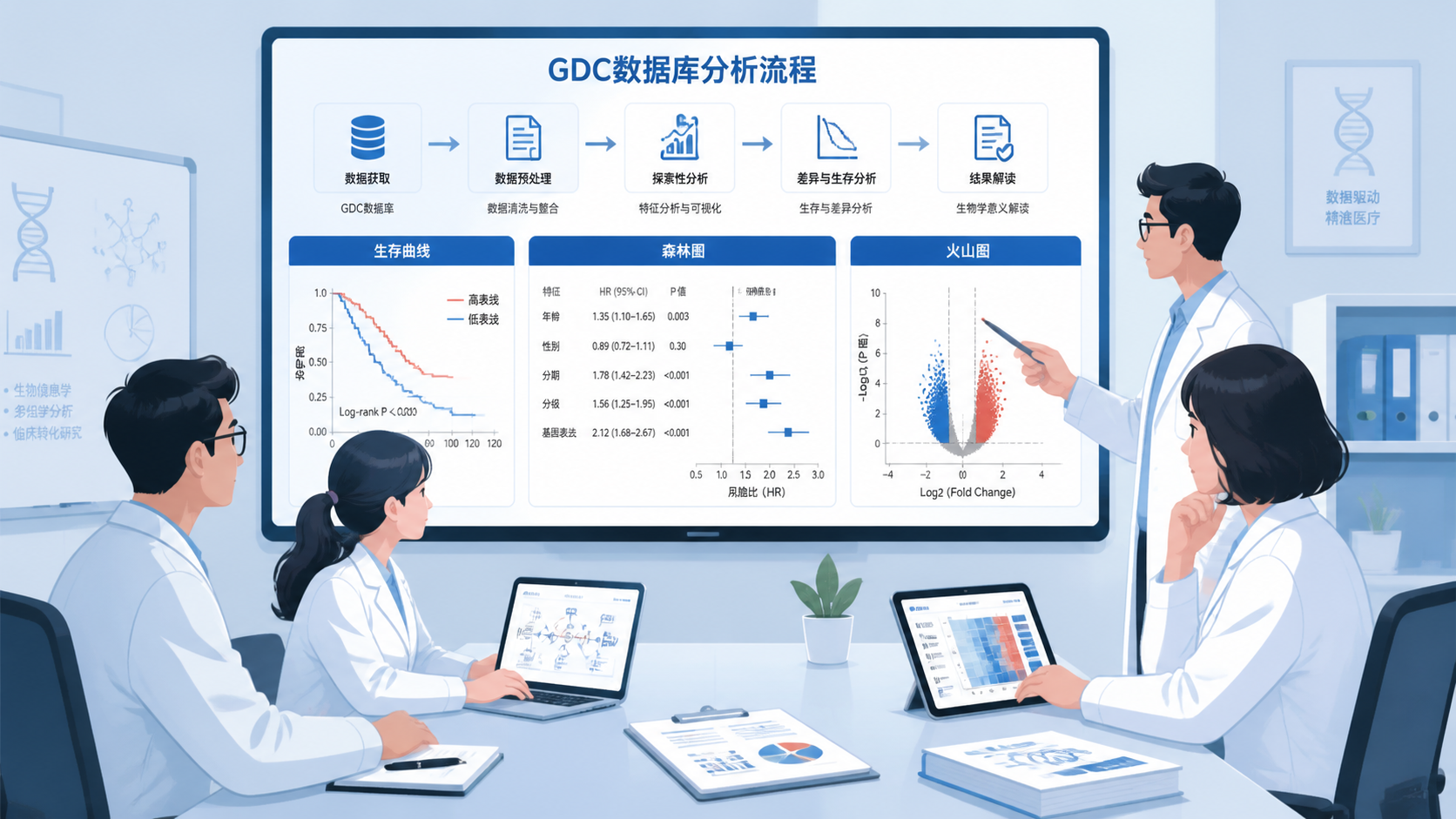
做GDC数据库分析时,常见流程通常包括几个步骤。先看表达差异,再做生存分析,然后结合富集分析和网络分析,最后尝试解释潜在机制。这个流程看似基础,但如果每一步都严谨,文章的逻辑会很完整。
常见的分析顺序可以概括为:
- 数据下载与清洗。
- 目标基因表达差异分析。
- 生存和临床相关性分析。
- 功能富集分析。
- 互作网络或核心基因筛选。
- 外部队列或实验验证。
关键不是步骤多,而是每一步都能回答一个明确问题。 这也是E-E-A-T中“专业性”和“可信度”的体现。
3.2与其他组学或工具结合
课程知识库还提到,单细胞转录组、空间转录组、多组学联合分析,已经成为热门方向。虽然GDC数据库本身更偏向癌症基因组和转录组资源,但它完全可以作为基础数据源,再与其他数据库或工具联合使用。
例如,你可以基于GDC数据库发现候选基因,再通过单细胞数据判断其在细胞亚群中的定位;或者用WGCNA、GSEA等方法进一步解释其功能关联。这类“公共数据库联用”的思路,往往比单纯做表达差异更容易形成创新点。
4.GDC数据库为什么适合生信学习者快速入门
4.1降低门槛,但不降低要求
很多人以为,使用GDC数据库就是“下载数据做图”。实际上不是。真正有价值的分析,必须同时考虑数据来源、样本筛选、分组标准和统计方法。否则即便图做出来,也很难通过同行评审。
GDC数据库之所以适合入门,是因为它的数据框架清晰,研究对象明确,便于学习者建立标准流程。它降低的是技术门槛,不是科研门槛。 这对培养规范的生信思维很有帮助。
4.2适合医生做转化研究
对临床医生来说,GDC数据库特别适合做转化型课题。因为研究起点往往来自临床问题,而不是单纯的算法兴趣。你可以从某种癌种的预后差异、分层治疗、免疫微环境等问题出发,再用数据库验证假设。
课程中提到,生信的优势之一就是“快”,尤其适合需要在较短周期内形成成果的科研环境。GDC数据库提供了一个现实可行的路径:先用公共数据找到方向,再决定是否继续做实验验证。 这能有效节省时间和成本。
5.使用GDC数据库时要注意什么
5.1样本筛选和分组必须严谨
GDC数据库虽好,但并不代表可以直接套模板。样本纳入和排除标准,往往决定结果是否可靠。比如,是否排除随访缺失样本,是否统一癌种亚型,是否控制批次效应,这些都会影响分析结论。
如果分组不清,统计再漂亮也可能是伪结果。 这是做GDC数据库研究时最常见的问题之一。建议在分析前先明确研究终点,再定义变量,再做统计,而不是先出图再找解释。
5.2结果解释要回到临床问题
生信结果的价值,不在于图多,而在于能否解释临床意义。对于医学生、医生和科研人员来说,最终都要回到“这个发现对疾病机制、诊断、预后或治疗有什么帮助”。只有这样,文章才更容易被认可。
数据库分析只是起点,不是终点。 如果条件允许,最好结合独立队列、免疫组化、qPCR或功能实验做验证。即便不做实验,也应尽量通过外部数据和多维统计增强可信度。
6.如何把GDC数据库用出科研产出
6.1从热门问题切入
课程知识库显示,公共数据库挖掘的高分文章,往往不是因为技术最复杂,而是因为切入点好。比如左右位点差异、特定细胞亚群、临床相关分层,这些都是问题导向很强的选题。GDC数据库同样如此。
你可以优先考虑这些方向:
- 单基因在特定癌种中的表达与预后。
- 免疫浸润与分子标志物的相关性。
- 风险评分模型构建。
- WGCNA筛选关键模块。
- 临床分层和亚组分析。
选题越贴近临床,GDC数据库的价值就越容易被体现。
6.2借助规范工具提升效率
在实际操作中,合理使用R包、可视化工具和标准化流程,会显著提高工作效率。对初学者而言,重点不是追求复杂,而是先把常规流程做规范。数据清洗、可视化、统计检验和结果复核,都应该形成固定习惯。
这也是解螺旋课程体系强调的重点之一。用成熟方法做扎实分析,再逐步向多组学、单细胞和数据库搭建延伸。 对于希望快速建立科研产出的读者,这是一条更稳妥的路径。
总结Conclusion
GDC数据库之所以成为生信研究必备,是因为它兼具数据规模、临床注释和标准化优势,特别适合肿瘤方向的公共数据挖掘。对医学生、医生和科研人员来说,它能帮助你更快进入分析阶段,也更容易形成可发表的研究框架。但要真正用好GDC数据库,关键仍然是研究问题、分组策略和统计规范。
如果你想更高效地把GDC数据库转化为可发表的课题,建议结合解螺旋的课程与定制化支持,系统掌握数据下载、分析和写作流程。先建立方法,再追求创新,这样更容易把数据库资源变成真实科研产出。
- 引言Introduction
- 1.GDC数据库是什么,为什么重要
- 2.GDC数据库适合哪些生信研究场景
- 3.GDC数据库研究常用的分析思路
- 4.GDC数据库为什么适合生信学习者快速入门
- 5.使用GDC数据库时要注意什么
- 6.如何把GDC数据库用出科研产出
- 总结Conclusion