引言Introduction
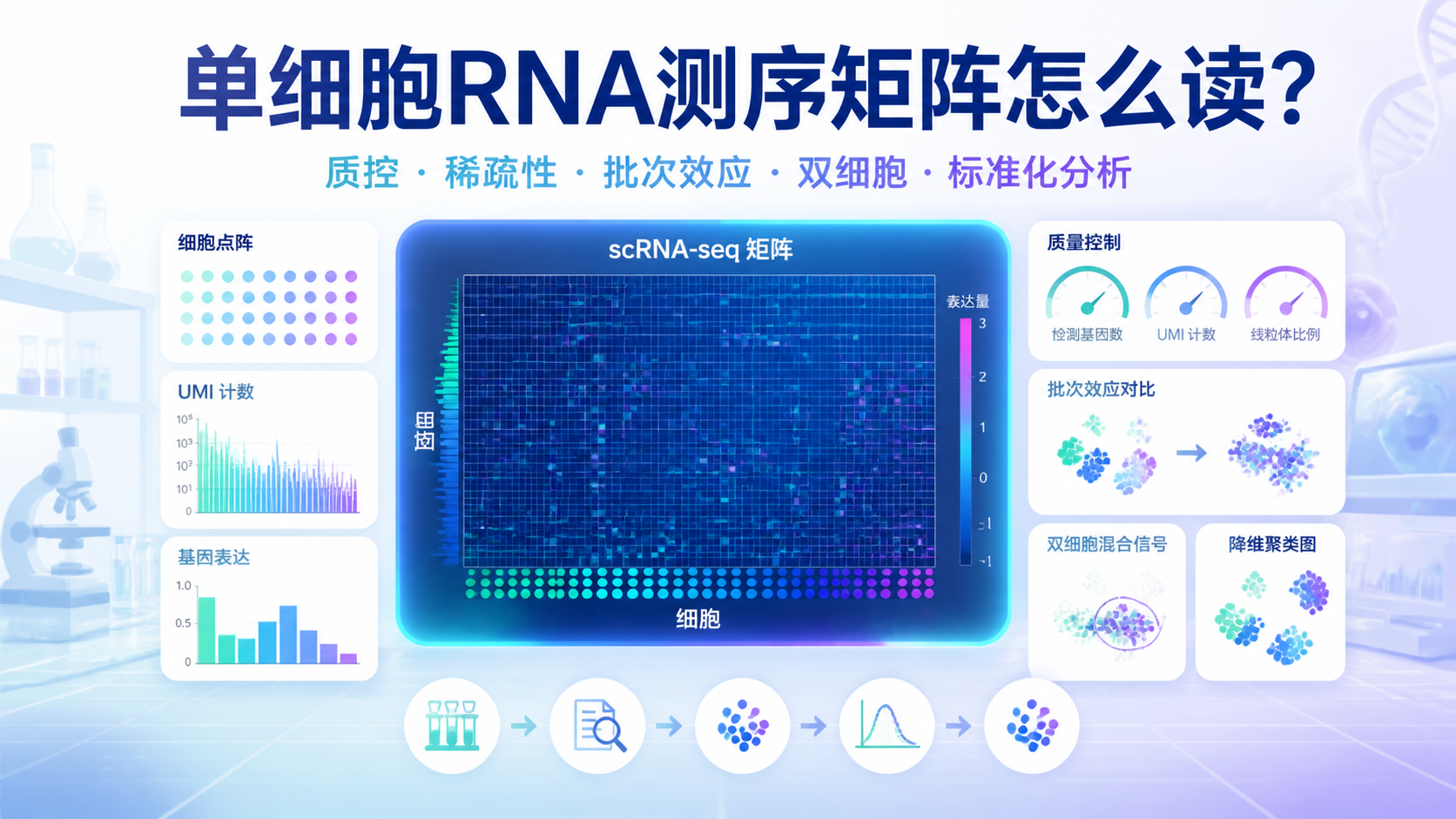
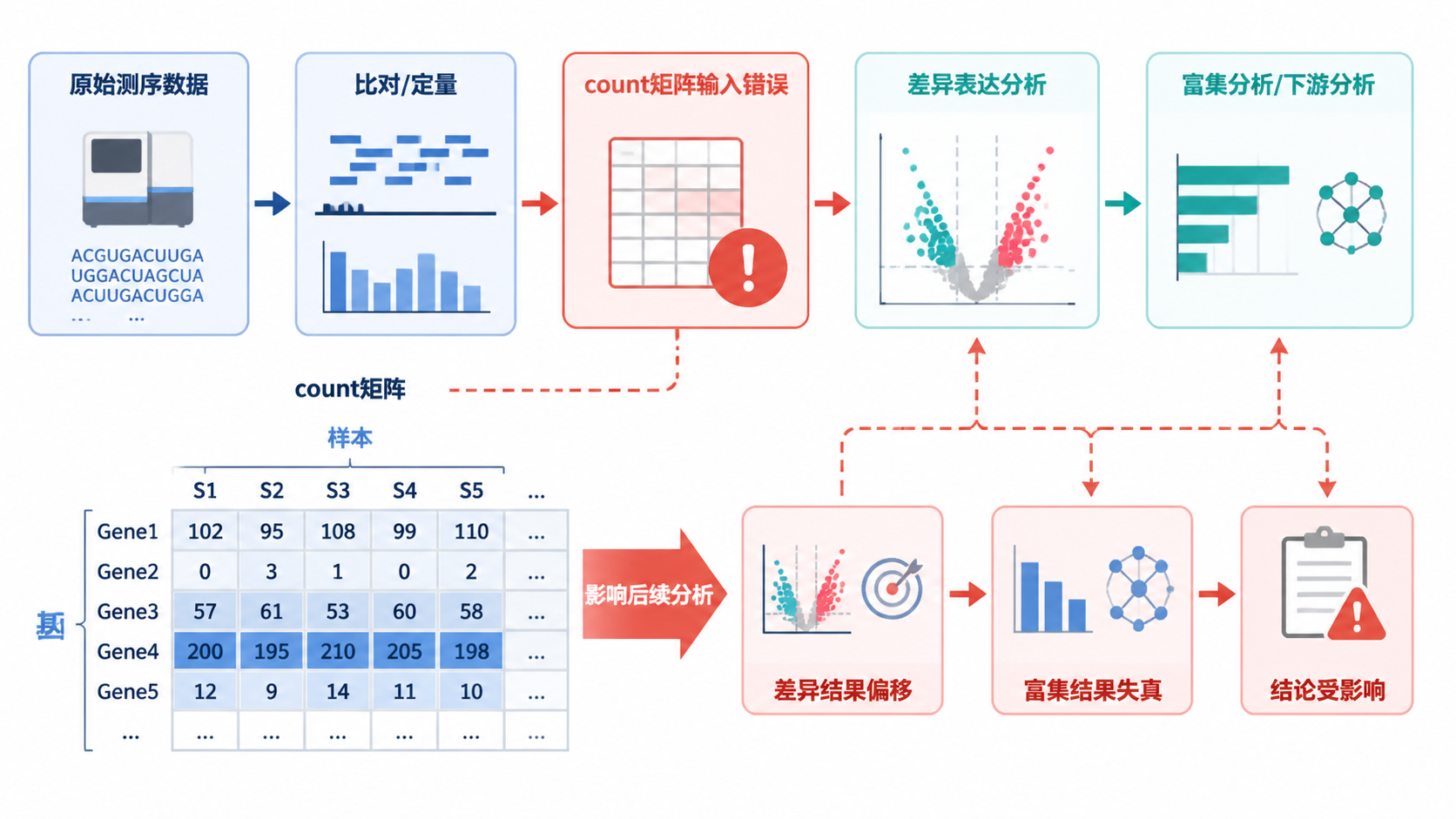
在转录组和单细胞分析里,count矩阵格式 一旦出错,后续标准化、差异分析、聚类都会受影响。很多问题并不在算法,而在输入矩阵本身。本文用5步梳理常见错误,帮助医学生、医生和科研人员快速排查。
1. 先弄清count矩阵格式到底是什么
1.1 行、列和数值要对应
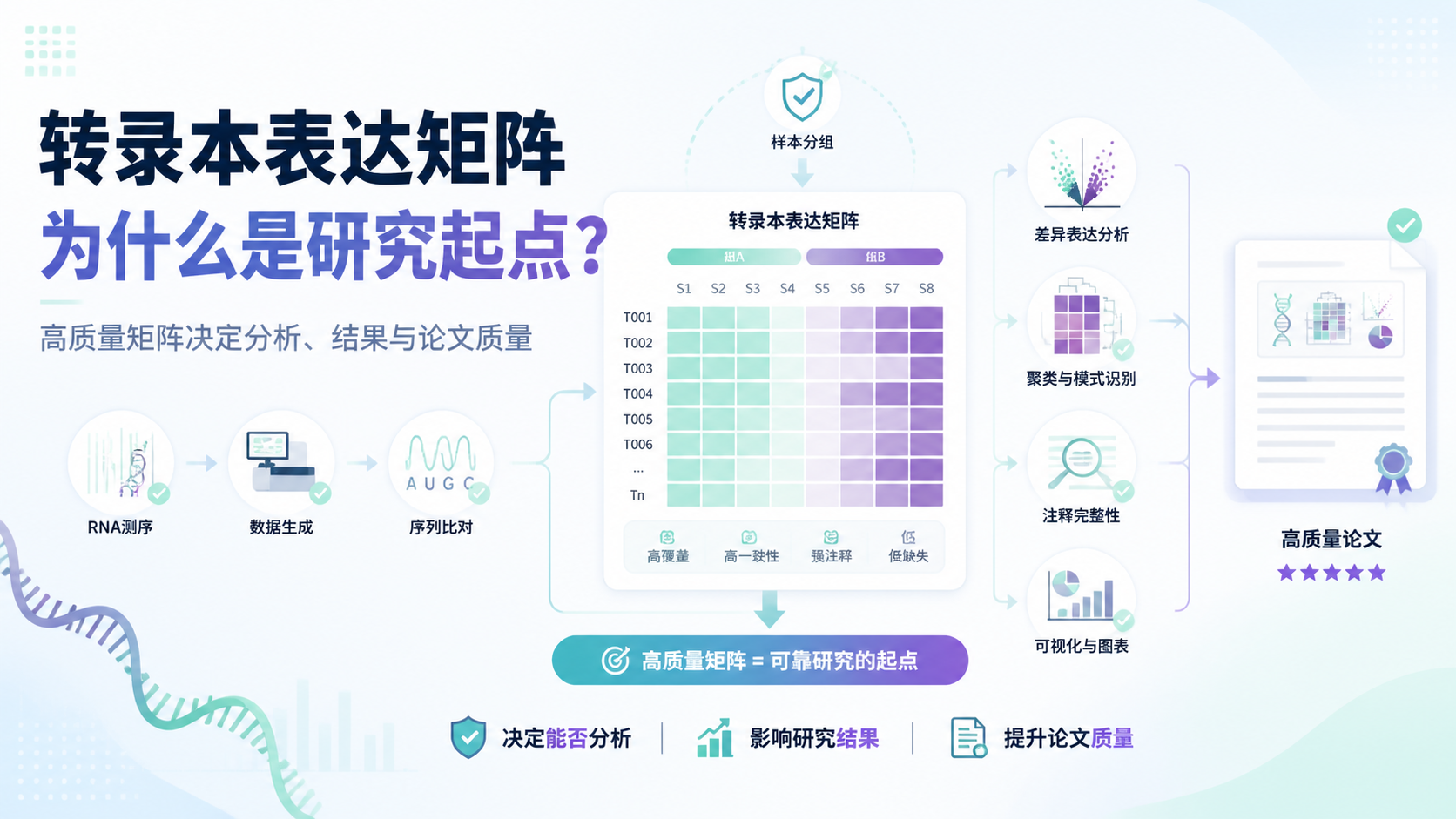
count矩阵格式 本质上是一个二维数据表。通常,行代表基因,列代表样本,单元格里的值代表原始计数。这个结构和R里的矩阵很接近,适合后续做表达量分析。
在实际工作中,最常见的错误是把行列顺序弄反。比如把样本放在行,基因放在列。这样做不一定立刻报错,但会让下游分析逻辑混乱。
1.2 count矩阵和普通表格不一样
count矩阵格式强调的是“可计算”。如果数值里混入字符,R会自动把数字转成字符型。这样一来,原本应当用于计算的列就失去了数值属性。
一旦矩阵中出现文本、符号或不统一的数据类型,就要先清洗,再进入分析。 这一步非常关键。
2. 第一步避坑:检查数据类型是否统一
2.1 数字和字符混在一起会出问题
R对混合类型的处理很直接。只要向量里有字符,数字也可能被转成字符。对于count矩阵格式来说,这意味着原本应该是整数计数的数据,可能被错误识别。
例如,基因计数列中如果混入“NA”“low”“-”等文本,后续求和、均值、筛选都会受到影响。
2.2 正确做法是先确认数值列
建议在导入后立刻检查:
- 每一列的类型
- 是否存在字符列
- 是否有空值或异常符号
如果发现某些列不是纯数值,应先转换或剔除。 对于科研数据,这是最基础也最容易忽略的一步。
3. 第二步避坑:样本和基因方向别弄反
3.1 维度放反会直接影响分析
count矩阵格式最常见的结构是“行是基因,列是样本”。但很多人从Excel导出后,习惯把样本写在第一列,基因写在第一行,结果在导入R后方向错位。
这类问题不会总是报错,但会导致:
- 样本数判断错误
- 基因数统计错误
- 后续分组信息无法匹配
3.2 导入后先看维度
一个实用习惯是先检查矩阵尺寸。比如:
- 基因数是否明显大于样本数
- 每列是否对应一个样本
- 每行是否对应一个基因
如果一个“count矩阵格式”里样本数看起来远多于基因数,就要优先怀疑方向是否反了。
4. 第三步避坑:不要忽略行名和列名
4.1 标签缺失会让对象失去可追踪性
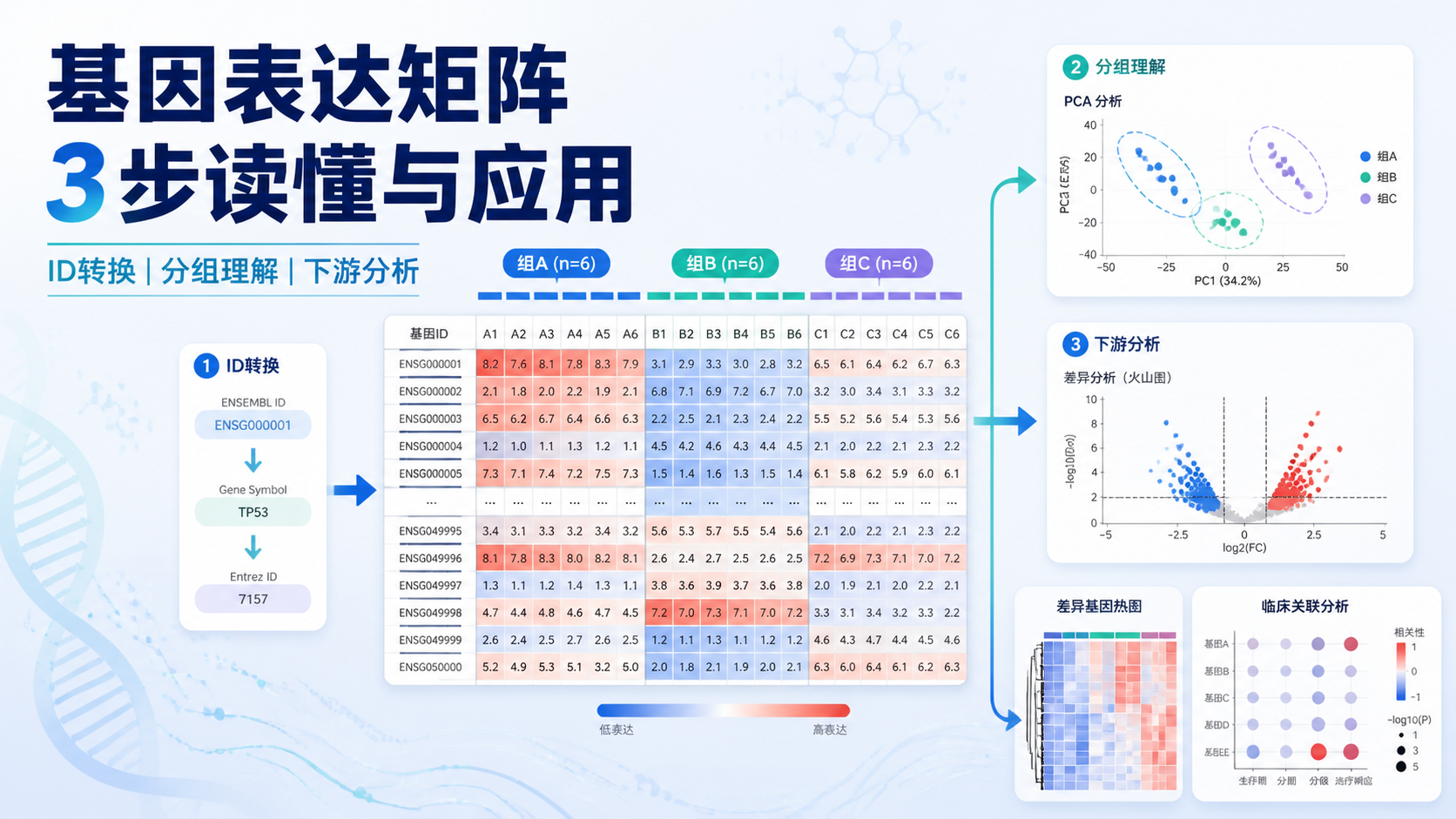
在R里,向量和矩阵都可以通过 names 赋标签。count矩阵格式也一样,行名和列名相当于数据的身份标识。没有它们,后续很难定位异常值。
如果没有清晰的基因名和样本名,差异表达结果、热图和富集分析都很难准确对应。
4.2 重名和覆盖也要注意
在代码中,如果对同一个对象重复赋值,后面的内容会覆盖前面的内容。这个问题在处理count矩阵格式时很常见。
建议你在导入后立刻检查:
- 行名是否重复
- 列名是否重复
- 是否存在空白名称
- 名称是否被自动改写
名字一旦错乱,下游注释和合并都会出问题。
5. 第四步避坑:注意下标、缺失值和越界提取
5.1 提取数据时要看范围
在R中,向量和矩阵都可以通过下标提取元素。count矩阵格式也常用于按行或按列筛选。问题在于,提取范围一旦越界,就会报错或返回NA。
对于矩阵来说:
- 提取不存在的行或列,可能直接报错
- 取值超出范围,会导致结果异常
- 删除索引写错,会误删数据
5.2 缺失值不是小问题
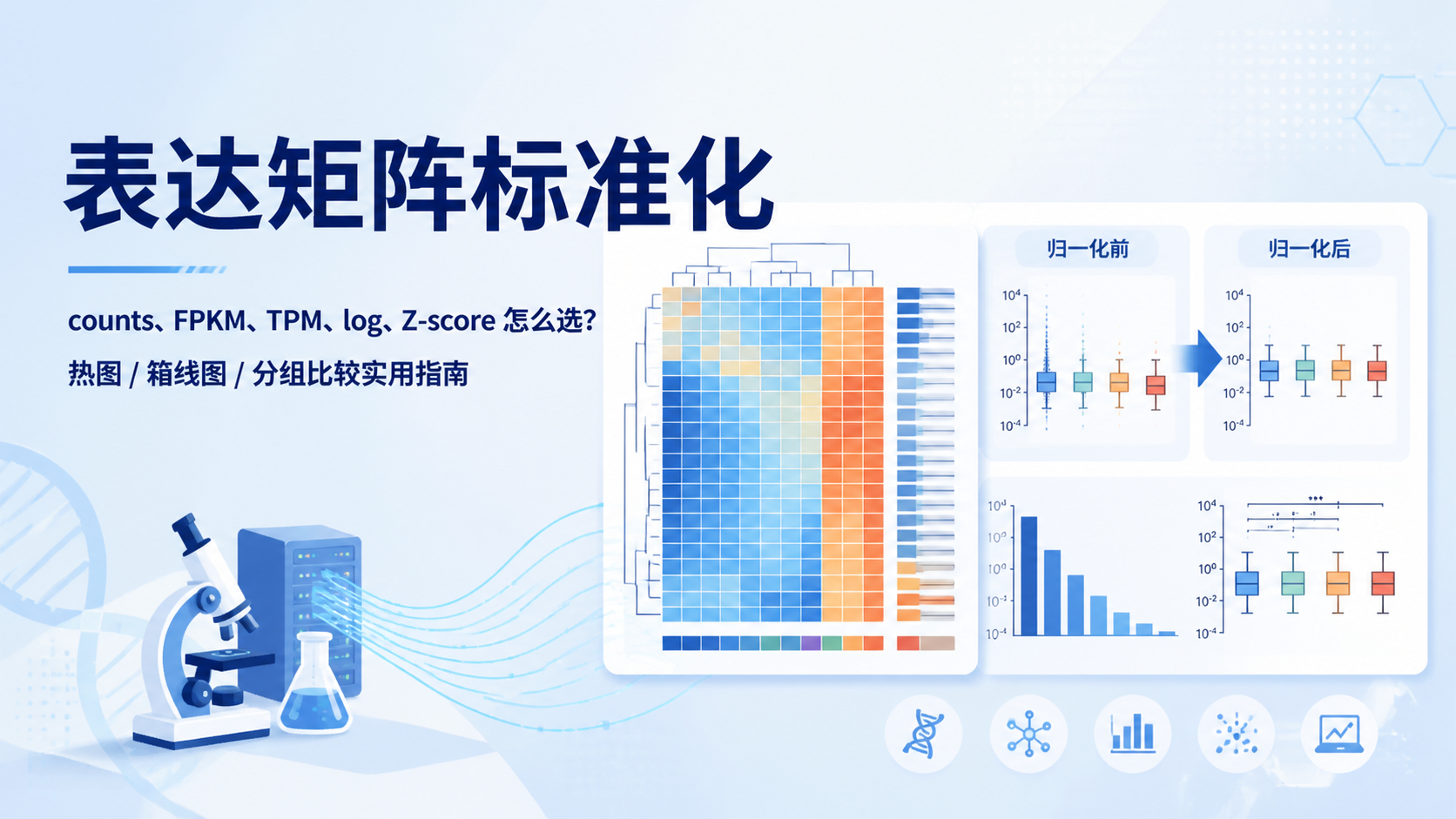
NA代表空值。对于计数矩阵,NA会影响:
- 归一化
- 过滤低表达基因
- 统计检验
- 可视化绘图
在正式分析前,建议先统计缺失值数量,再决定是否填补、删除或重新导入。
6. 第五步避坑:用基础函数快速自检
6.1 先看结构,再做分析
R里有一些基础函数,能帮助你快速判断count矩阵格式是否正常。例如:
- 查看维度
- 查看前几行
- 查看每列类型
- 查看是否有异常值
这些操作很基础,但非常有效。很多时候,问题不在模型,而在输入数据是否干净。
6.2 先做最小化检查清单
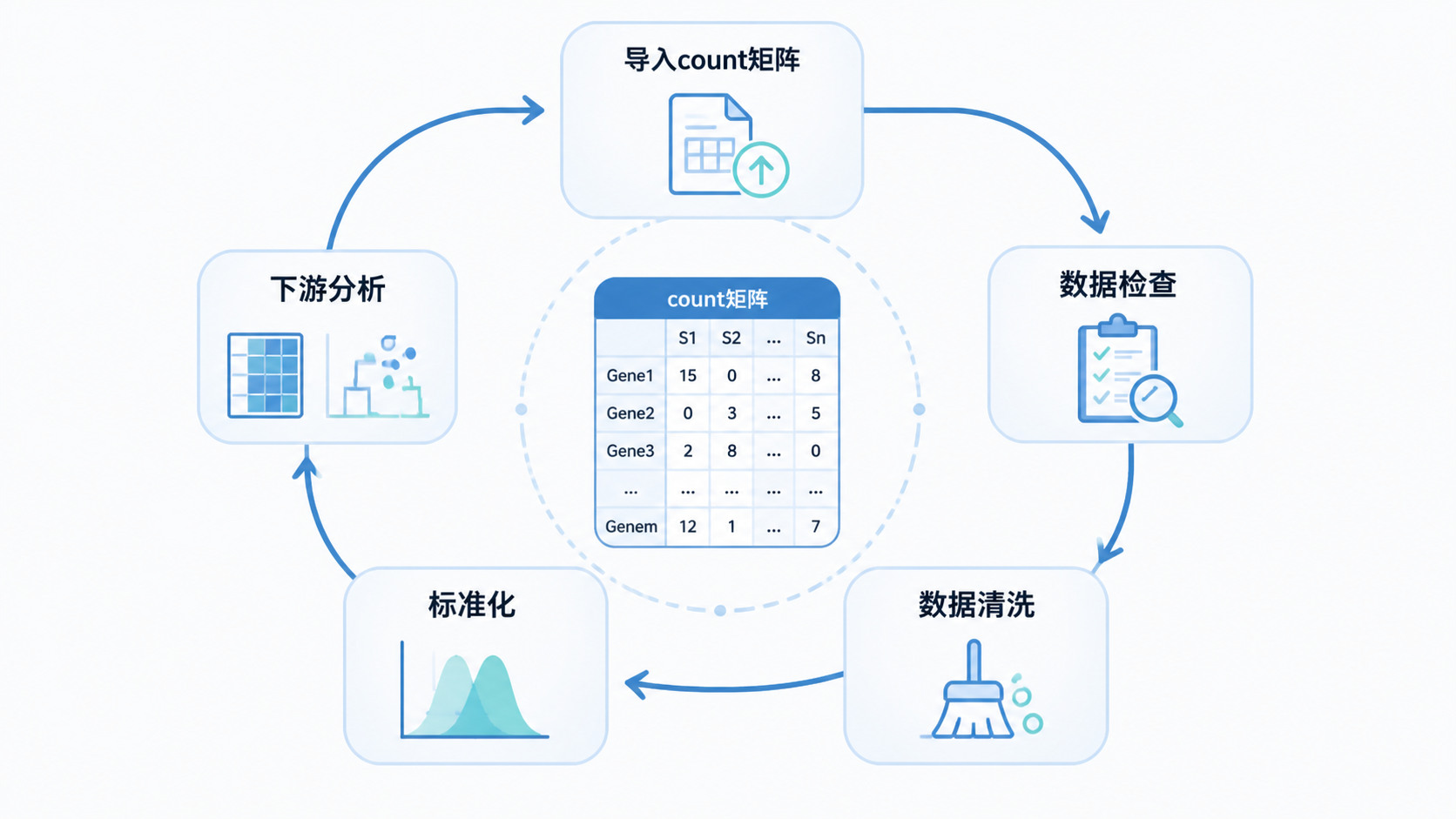
建议每次导入count矩阵格式后,按下面顺序检查:
- 行列是否符合“基因在行,样本在列”
- 数值是否全为整数或数值型
- 行名、列名是否完整且唯一
- 是否存在NA、空字符、异常符号
- 维度是否符合实验设计
把这5项做完,能过滤掉大部分低级错误。
7. 从R基础到科研实战,怎么养成稳定习惯
7.1 先理解矩阵,再处理count矩阵
count矩阵格式本质上还是矩阵。R中矩阵是二维结构,支持按行、按列提取,也支持直接运算。理解这一点,才能避免把表格当成普通文本处理。
如果你能熟练使用切片、筛选、查看长度和检查类型,就能更快发现问题。
7.2 让流程标准化
科研数据处理最怕“每次都临时想办法”。建议把导入、检查、清洗、保存做成固定流程。这样即使面对新项目,也能快速定位count矩阵格式错误。
稳定的输入规范,往往比复杂的算法更能决定分析质量。
总结Conclusion
count矩阵格式看似简单,实则是转录组和单细胞分析的入口。只要在数据类型、行列方向、名称标签、下标提取和缺失值这5个环节提前排查,就能显著减少后续分析错误。
如果你希望把这些检查步骤变成标准化流程,可以借助解螺旋品牌的科研数据处理工具与方法支持,提升导入、清洗和分析效率。
- 引言Introduction
- 1. 先弄清count矩阵格式到底是什么
- 2. 第一步避坑:检查数据类型是否统一
- 3. 第二步避坑:样本和基因方向别弄反
- 4. 第三步避坑:不要忽略行名和列名
- 5. 第四步避坑:注意下标、缺失值和越界提取
- 6. 第五步避坑:用基础函数快速自检
- 7. 从R基础到科研实战,怎么养成稳定习惯
- 总结Conclusion