引言Introduction
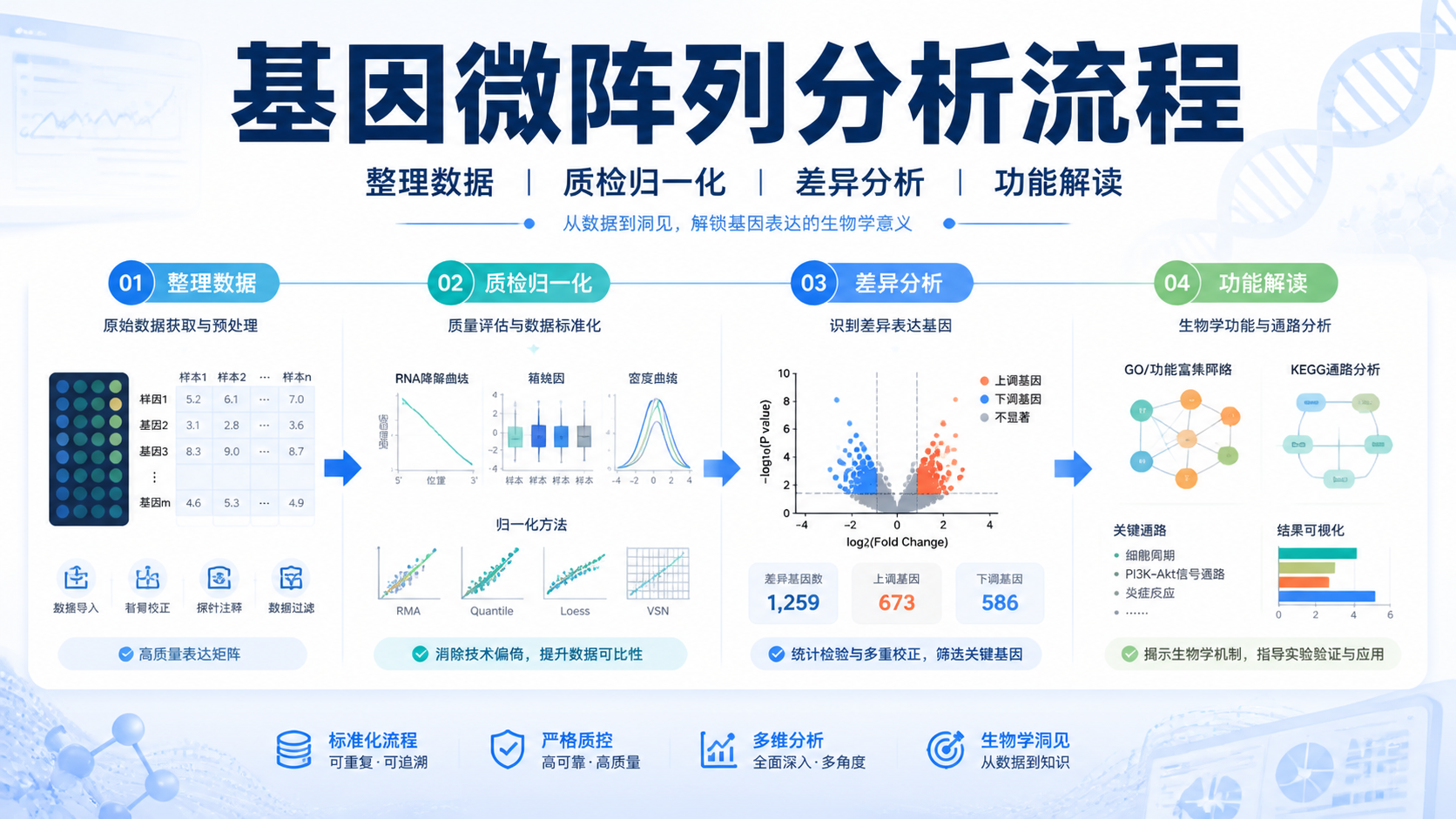
基因微阵列数据怎么做,很多人卡在第一步。文件格式不对、分组不清、归一化混乱,都会让后续差异分析失真。其实,只要把流程拆成3步,就能更稳地完成分析。
1. 先把基因微阵列数据整理对
1.1 明确数据类型和输入格式
基因微阵列数据常见于芯片表达谱分析。进入分析前,先确认数据是单个表达矩阵,还是多个数据集整合分析。NetworkAnalyst支持单个基因表达列表、多个表达数据、基因或蛋白列表、RNA测序文件和网络文件等输入类型。
如果是微阵列数据,最关键的是把表达矩阵整理成标准文本文件。 教程中建议将Excel转成制表符分隔的.txt文件,且文件大小不超过50MB。样本名、分组名、基因名和表达量都要清晰对应。
1.2 按规则标注分组信息
分组信息是基因微阵列数据分析的核心。教程中强调,分组名称首列要以“#Class:”开头,不同分组要单独占一行。这样工具才能识别实验组、对照组,或者多因素设计。
例如,只有一组样本时,可以直接写单分组数据。若有两组或更多组,就要在表格中按行区分。分组不规范,后面的差异分析和可视化结果都会受影响。
1.3 选择合适的物种和平台
上传到NetworkAnalyst时,需要选择物种、数据类型和ID类型。该平台支持17种常见物种的表达谱和功能分析。若研究物种不在列表中,也可选择“Not specified”,仍能做差异分析、火山图和热图。
对于公共数据库数据,建议优先确认芯片平台是否有良好注释。教程也提醒,平台选择尽量规范,常见平台如 Affymetrix、Illumina 等通常更稳定。平台注释越完整,后续映射到基因层面的结果越可靠。
2. 再做质检和归一化
2.1 质检先看四个结果
上传后,第一步不是急着做差异分析,而是先看质检结果。NetworkAnalyst会展示箱线图、计数总和、PCA和密度图等信息。左侧流程栏也会依次显示数据上传、质检、归一化、差异分析等步骤。
这一步的目的很明确:判断样本是否可比,是否存在离群点,是否需要进一步处理。如果质检不过关,后面的统计结论就不稳。
2.2 归一化决定结果可信度
教程中给出一个实用判断。若芯片数据的log2FC均值通常小于16,测序数据通常小于20,往往提示已经做过归一化,可选择None。若未归一化,可选log2转换、方差稳定性归一化、分位数归一化或分位数归一化后VSN。
其中,log2转换是最常用的方法 。它能减少极端值影响,让不同样本间的表达分布更接近。对微阵列数据来说,归一化做得好,箱线图会更整齐,PCA也更容易把组别分开。
2.3 常见错误要提前避开
基因微阵列数据里,最常见的错误不是算法,而是数据前处理。比如探针没正确注释成基因名,或者样本编号和临床信息对不上。教程也特别强调,处理过程中要检查交集,避免表达矩阵和临床ID不一致。
一句话:数据整理和归一化做不好,差异分析再漂亮也不可靠。
3. 最后进入差异分析和功能解读
3.1 差异分析先找显著基因
完成质检和归一化后,就可以进入差异分析。NetworkAnalyst会基于你上传的数据输出差异基因,并提供火山图、热图等可视化结果。对于研究者来说,这一步的目标不是“找最多基因”,而是找“最有解释力的基因”。
教程中提到,差异分析属于“挑”,即挑选不同条件下表达显著差异的基因。如果你的样本来自肿瘤与正常组织,或者处理前后对比,差异基因就是后续机制研究的起点。
3.2 功能富集和网络分析提高解释力
基因微阵列数据做完差异分析后,通常还要做功能富集和网络分析。NetworkAnalyst的主要功能就包括差异基因分析、功能富集分析、互作网络分析,以及多个数据集的荟萃分析。
这一步的价值在于,把“基因列表”变成“生物学结论”。例如,你可以进一步看这些差异基因是否集中在某些通路、分子功能或蛋白互作模块中。对医学生和科研人员来说,这比单纯列出基因名更接近论文写作需求。
3.3 多数据集整合时更要统一标准
如果你手上不止一个基因微阵列数据集,还想做整合分析,前提是样本条件尽量相近。教程中指出,多个数据集可以进行荟萃分析,但前提是数据来源、组织类型、分组逻辑尽量一致。
另外,做公共数据二次挖掘时,要注意样本量、组织来源、分组信息、测序类型和注释完整性。不一致的数据不要硬拼,否则结果容易失真。
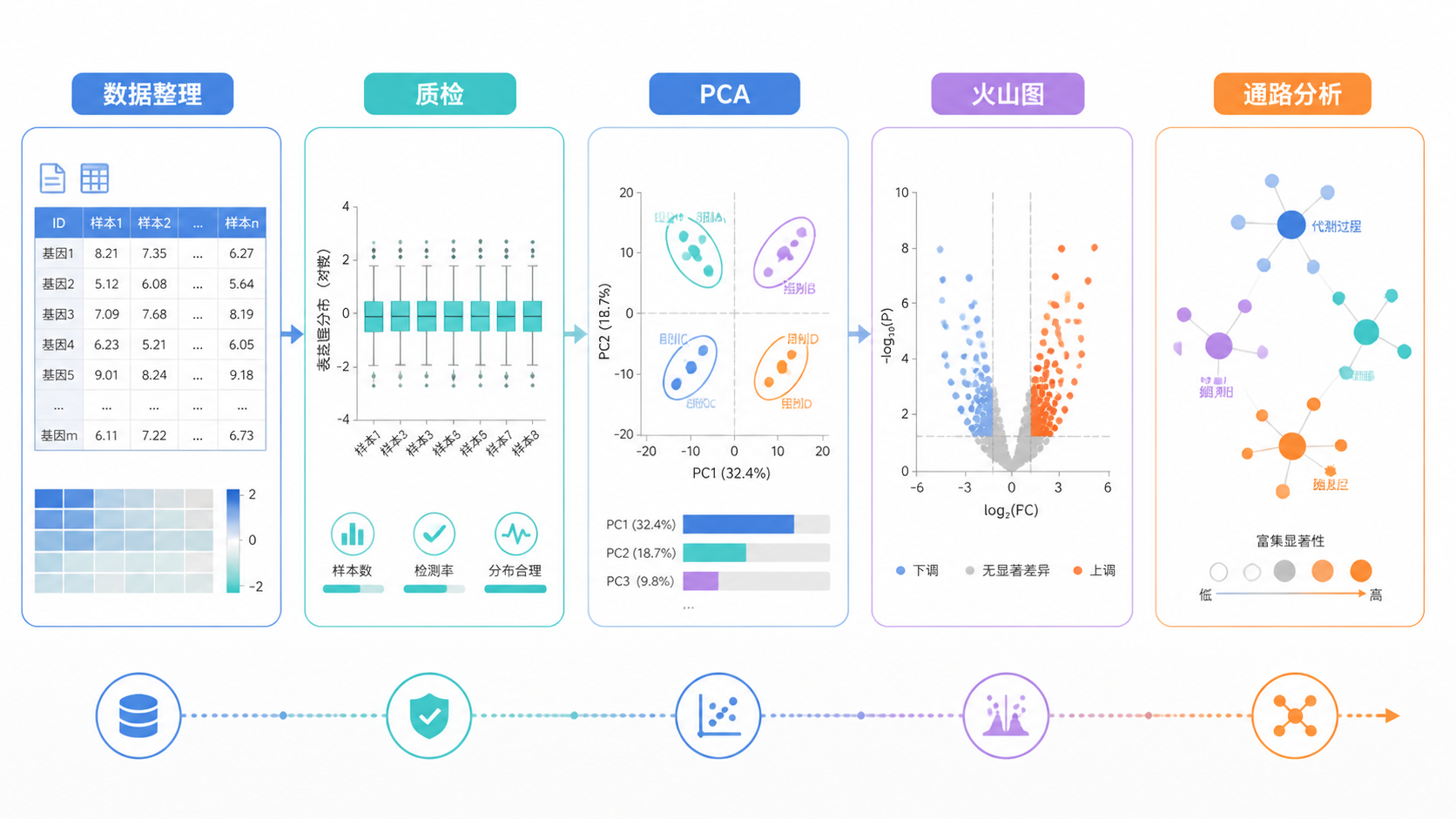
4. 用3步把分析流程走稳
4.1 第一步,整理成可上传的标准表格
把Excel整理成标准.txt,确认样本名、分组名、基因名和表达值对应无误。需要时补上“#Class:”分组标识。上传前先检查文件大小和平台类型。
4.2 第二步,先质检,再归一化
先看箱线图、PCA、密度图和计数总和,再决定是否需要log2转换或其他归一化方式。这一步直接决定后续统计是否可信。
4.3 第三步,做差异分析并连接功能解释
在获得差异基因后,再接功能富集和网络分析。这样可以把结果从“表达变化”推进到“机制假设”。对于论文、课题和汇报,这都是更完整的分析链条。
4.4 想节省时间,可以直接用成熟平台
如果你希望少走弯路,解螺旋的分析思路很适合用来快速上手。它能帮助你把基因微阵列数据从整理、质检、归一化,到差异分析和网络解释,按步骤推进,减少格式错误和流程遗漏。对刚接触芯片数据的医学生、医生和科研人员,这类标准化路径尤其重要。
总结Conclusion
基因微阵列数据怎么做,核心就是三步。先整理数据格式,再做质检和归一化,最后进入差异分析与功能解读。只要前处理规范,结果就更容易稳定,也更适合论文和课题使用。
如果你正在处理基因微阵列数据,但卡在上传格式、归一化判断或差异分析流程,建议直接参考解螺旋的标准化分析思路,少走弯路,尽快把数据转化为可发表的结果。
- 引言Introduction
- 1. 先把基因微阵列数据整理对
- 2. 再做质检和归一化
- 3. 最后进入差异分析和功能解读
- 4. 用3步把分析流程走稳
- 总结Conclusion