引言Introduction
测序覆盖度数据直接决定你能否“看见”真实变异。覆盖不够,漏检、假阴性和结果不稳定就会增加。对医学生、医生和科研人员来说,理解测序覆盖度数据 ,是解读WES、TMB和变异验证结果的基础。
1. 什么是测序覆盖度数据
1.1 覆盖度、深度和覆盖率的区别
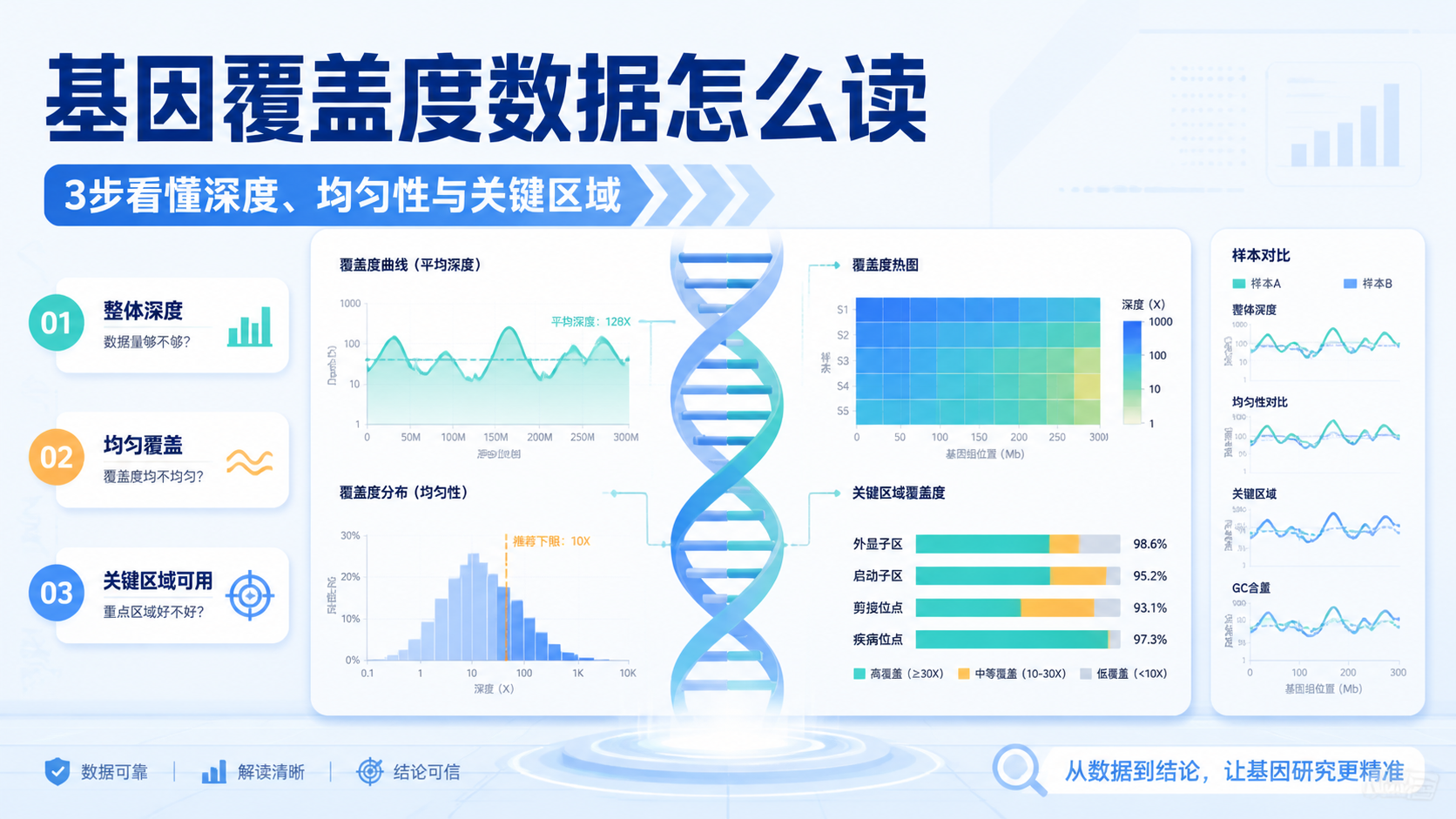
测序覆盖度数据 常被混用,但严格来说,深度和覆盖率不是一回事。深度是某个碱基被重复测到的次数。覆盖率是目标区域中有多少比例被测到。二者共同决定分析质量。
在WES中,测序覆盖度数据通常会结合5x、10x、20x、30x等阈值一起看。阈值越高,说明可用于可靠分析的区域越多。对于变异检测,30x以下区域的稳定性通常不如高深度区域。
1.2 为什么WES特别依赖覆盖度
全外显子测序的目标是外显子区域,但真实数据中仍会受到捕获效率、GC含量、文库质量和重复率影响。测序覆盖度数据不均匀,往往会导致某些外显子“看不见”或“看不清”。
知识库中的分析流程也强调,原始数据要先做质控,再去接头、去低质量reads、比对、去重复,随后统计目标区域覆盖度和次级深度。也就是说,覆盖度不是最后补看的指标,而是流程中的核心环节。
2. 测序覆盖度数据如何影响变异检测
2.1 低覆盖会带来假阴性
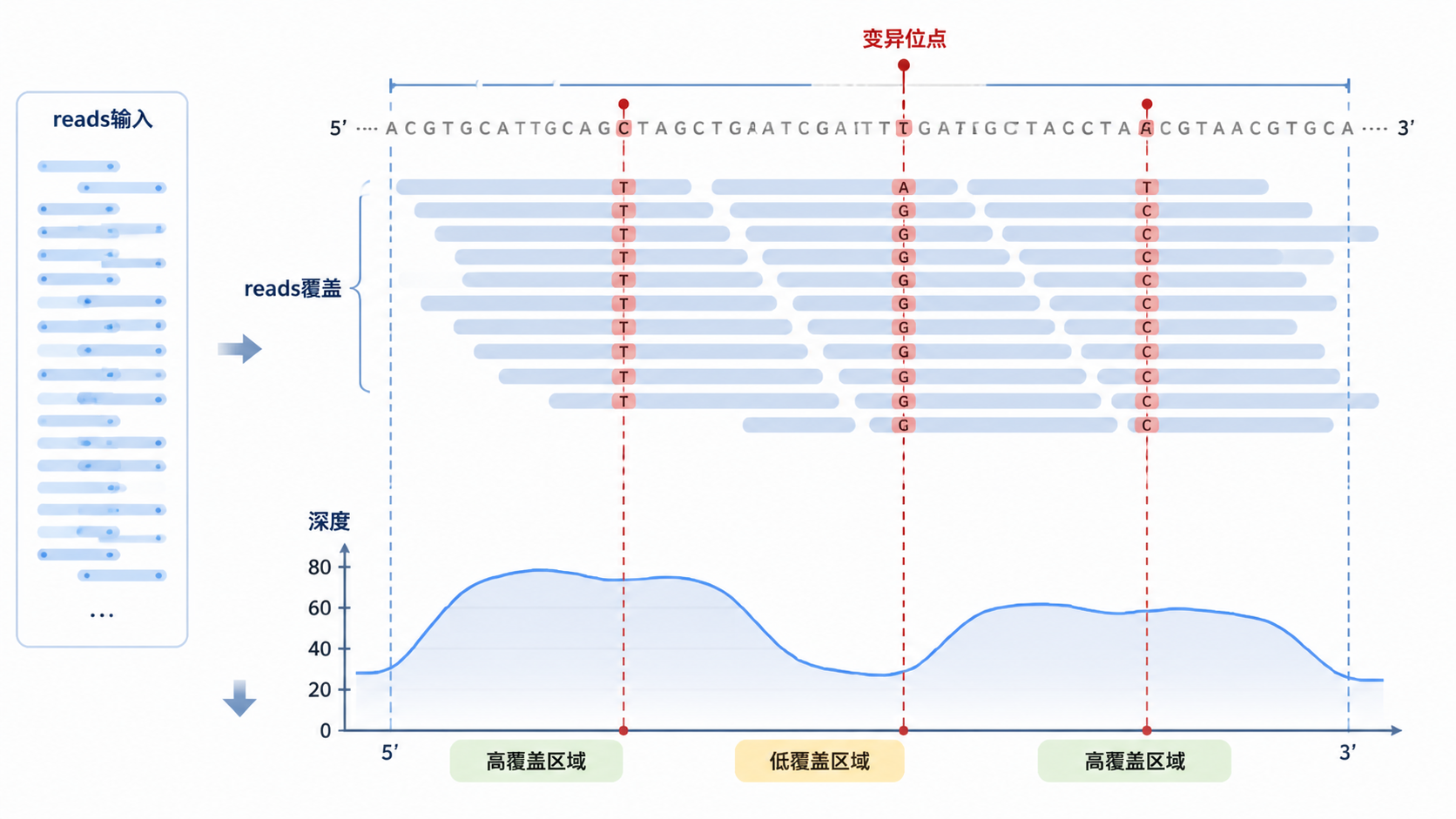
在SNP和Indel检测中,覆盖度不足会直接影响检出率。尤其是体细胞突变和低频突变。覆盖度越低,等位基因频率越低的突变越容易被漏掉。 这会让临床报告和科研结论都偏向保守。
例如,GATK的HaplotypeCaller常用于胚系突变检测,Mutect2常用于体细胞突变检测。无论使用哪种算法,输入数据的覆盖度都决定了候选位点是否能达到可信阈值。没有足够reads支撑,软件很难给出稳健判断。
2.2 高覆盖不等于高质量
很多人只看平均深度,但这并不够。平均深度高,不代表每个目标位点都覆盖均匀。 如果某些区域出现“断崖式下降”,这些区域仍然可能漏检。
因此,分析时要同时看:
- 平均深度。
- 目标区域覆盖率。
- 不同阈值下的覆盖比例。
- 重复率和mapping rate。
知识库提到,如果150x和200x之间没有明显数值跳跃,说明panel设计比较合理,不会因深度增加导致局部覆盖突然下滑。这个思路同样适用于WES的覆盖度评估。
3. 覆盖度数据在分析流程中的关键位置
3.1 质控后先看覆盖度
标准流程一般是:
- 原始数据质控。
- 去接头、去低质量reads。
- 比对到参考基因组。
- 去重复或标记重复。
- 统计覆盖度和深度。
- 进行变异检测和注释。
如果覆盖度统计放得太晚,就会把技术问题误判成生物学差异。 这在病例队列研究中特别常见。比如某些样本看似突变较少,实际可能只是捕获失败或有效深度不足。
3.2 目标区域覆盖度决定后续注释可靠性
变异检测之后还要做注释。包括基因注释、数据库频率查询、SIFT、PolyPhen等致病性评估。但这些注释建立在“先检到位点”的基础上。 如果位点本身因为覆盖不足而漏掉,后续所有注释都无从谈起。
在临床或科研报告中,覆盖度信息还常用于解释为什么某些基因未检出明确变异。对于医学生和医生来说,这一点很重要。它能避免把“未发现”误读成“肯定没有”。
4. 测序覆盖度数据与验证实验的关系
4.1 覆盖度决定是否需要补充验证
当测序覆盖度数据不理想时,验证实验的重要性会进一步上升。知识库中提到,研究会用Sanger测序或三代测序验证关键位点真实性。原因很直接。覆盖度不足时,二代测序给出的位点可信度可能不够。
对于首次发现的候选位点,尤其是新发突变、致病突变或关键氨基酸替换,验证步骤几乎不可省略。比如位点R11339Q这类结果,只有在覆盖和注释都充分的前提下,才更容易被认可。
4.2 覆盖度不均时,验证更要谨慎
如果一个区域在样本间覆盖差异很大,那么变异频率比较就会失真。此时不能简单用“有没有检出”下结论,而要先看该区域是否具备足够的测序覆盖度数据支撑。
这也是为什么很多论文会同时给出:
- 原始reads质量统计。
- 比对率。
- 平均深度。
- 覆盖到20x、30x的比例。
- 关键位点的测序图谱。
这些信息共同构成结果可信度,而不是单一数字。
5. 覆盖度数据在临床与科研中的实际意义
5.1 产前诊断和罕见病研究更依赖覆盖度
在产前诊断、罕见病和肿瘤研究中,样本往往少,容错率低。任何一个关键位点的漏检,都可能影响后续判断。测序覆盖度数据越稳定,临床解释空间越小,结论越可信。
知识库中的产前WES研究显示,WES能在核型和染色体微阵列正常时检测到更多异常案例。这个优势的前提之一,就是测序覆盖度达到足够水平。否则,WES的灵敏度优势会被稀释。
5.2 在TMB和panel分析里,覆盖度同样重要
TMB虽然是统计概念,但它的计算仍依赖变异检出。对于panel或WES数据,覆盖度会影响体细胞突变数量,从而影响TMB结果。覆盖不足会低估TMB,覆盖不均会放大样本间偏差。
因此,在肿瘤分析中,不能只看突变数,还要看捕获区域大小、测序深度、过滤规则和样本类型。组织样本、ctDNA和不同panel的覆盖表现都不同,不能混用同一标准。
6. 如何解读一份覆盖度结果
6.1 看这几个核心指标
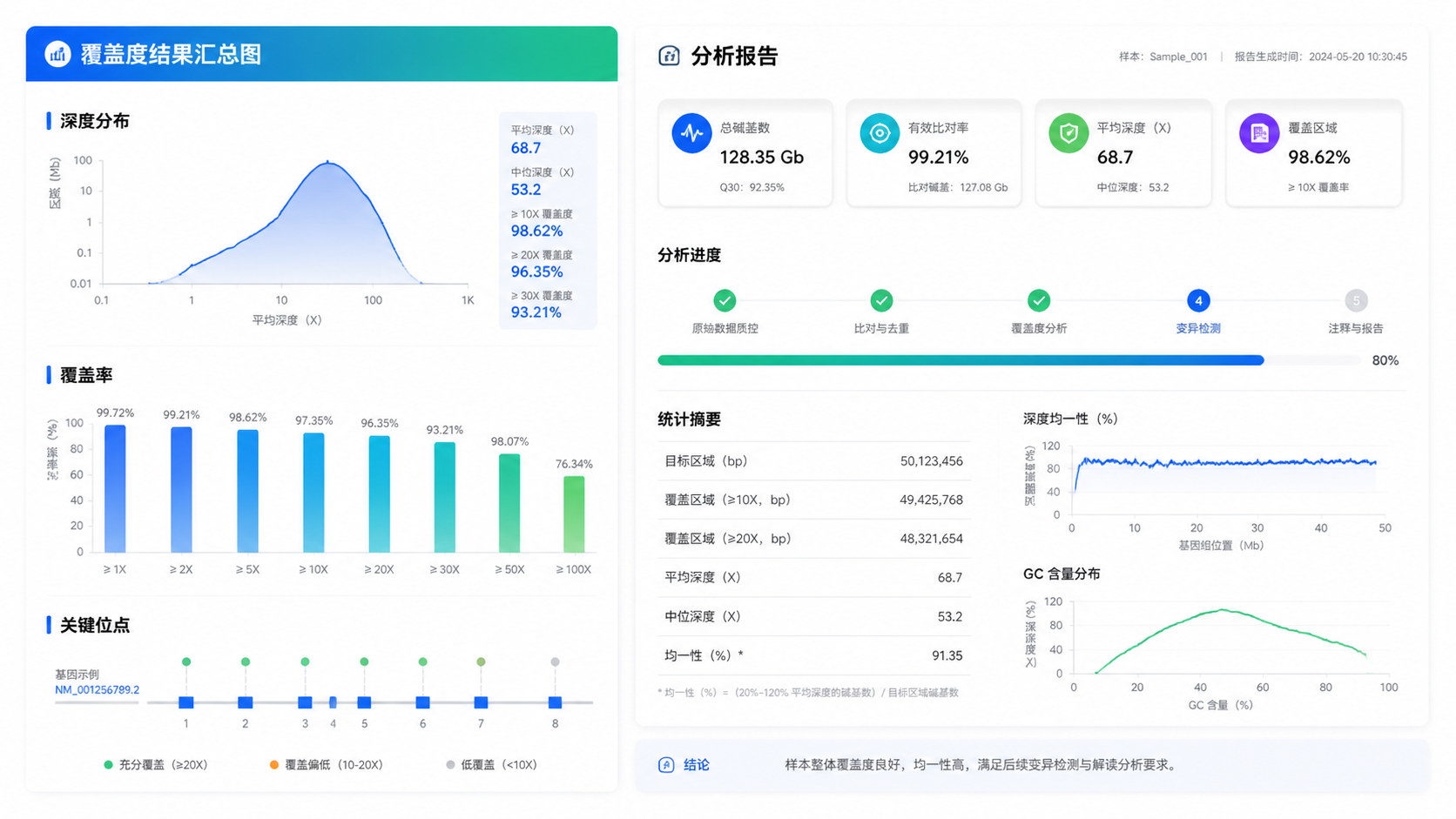
解读测序覆盖度数据 时,建议优先看以下指标:
- 平均测序深度。
- 目标区域覆盖率。
- 20x、30x及更高阈值的覆盖比例。
- Mapping rate。
- 重复率。
- 关键基因或关键位点的局部深度。
如果平均深度合格,但30x覆盖率很低,说明数据并不稳。反之,如果覆盖率高且分布均匀,后续变异分析的可信度会明显提高。
6.2 结合研究目的来判断
不同任务对覆盖度要求不同。胚系变异、体细胞突变、低频突变和产前诊断的阈值都不一样。不要用同一个覆盖标准套所有项目。 这是很多初学者最常见的误区。
科研场景中,更关注全局一致性和可重复性。临床场景中,更关注关键位点是否足够可靠。分析前先定义目的,后面读覆盖度结果才不会偏。
7. 实际优化建议
7.1 从实验设计开始控制覆盖度
覆盖度问题,不只是生信问题。很多时候根源在实验设计。包括:
- DNA起始量是否足够。
- 文库质量是否合格。
- 探针设计是否合理。
- 捕获区域是否均匀。
- 测序量是否匹配目标深度。
知识库明确提到,panel设计和覆盖曲线要一起看。这个逻辑同样适用于WES。好的实验设计,能减少后期覆盖盲区。
7.2 从分析流程中及时发现问题
数据分析时,建议在比对后尽早做覆盖统计。不要等到变异报告阶段才发现某个区域根本没有足够reads。这样会浪费时间,也会影响报告质量。
对于常规WES分析,最好把覆盖度结果和变异结果一起出图。让读者能一眼看到数据是否支持结论。这也是E-E-A-T要求中的“可验证性”体现。
总结Conclusion
测序覆盖度数据不是附属指标,而是决定测序分析成败的核心变量。 它影响变异检出、结果稳定性、验证必要性以及临床解释力度。对医学生、医生和科研人员来说,读懂覆盖度,就等于读懂了一份测序报告的可信边界。
如果你希望把覆盖度、深度、变异注释和结果汇报串成完整分析链路,可以借助解螺旋品牌的生信内容与分析支持 ,把复杂数据转化为可发表、可汇报、可落地的结果。
- 引言Introduction
- 1. 什么是测序覆盖度数据
- 2. 测序覆盖度数据如何影响变异检测
- 3. 覆盖度数据在分析流程中的关键位置
- 4. 测序覆盖度数据与验证实验的关系
- 5. 覆盖度数据在临床与科研中的实际意义
- 6. 如何解读一份覆盖度结果
- 7. 实际优化建议
- 总结Conclusion