引言Introduction
生存分析是临床研究里最常见,也最容易用错的一类统计方法。很多人只会画KM曲线,却分不清生存率、累计生存概率、删失数据和Log-rank检验。如果方法选错,结果可能“看起来正确”,但结论不可信。 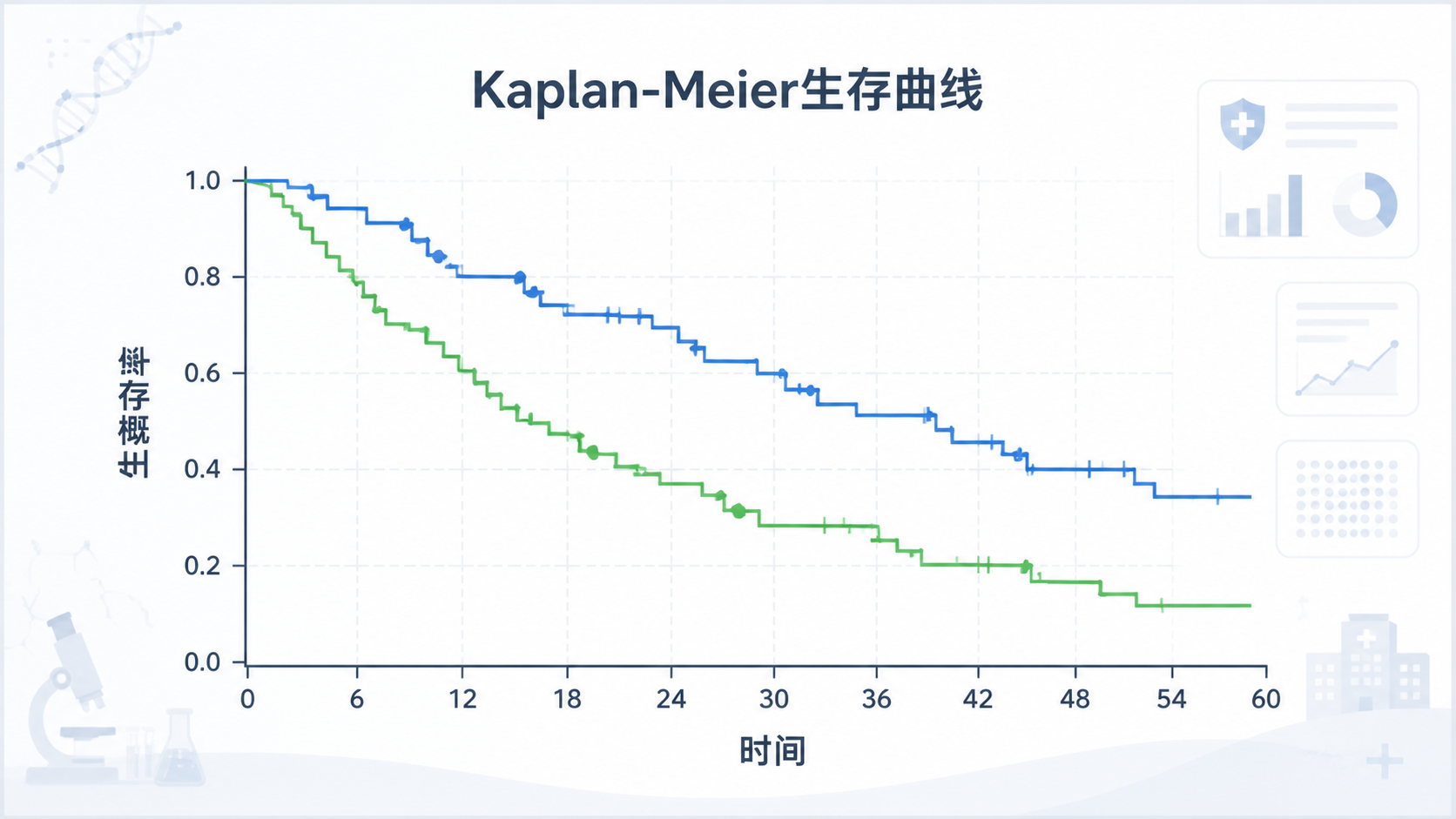
1. 先弄清楚:生存分析到底在分析什么
1.1 不是只看“活了多久”
生存分析研究的是 time to event ,也就是“事件发生的时间”。这里的事件不一定是死亡。
它可以是死亡、复发、进展、转移,也可以是下床活动、愈合、缓解等。
核心不是单纯的时间,而是“时间 + 结局”。 这也是生存分析和普通回归最大的区别。
在医学研究中,事件必须先定义,再收集时间。定义不同,统计结果就完全不同。
1.2 删失数据是生存分析的关键
临床随访里,不是每个患者都会观察到终点。常见情况有三类:
- 失访。
- 研究结束时仍未发生事件。
- 未发生你定义的事件,但出现了其他原因结局。
这些都属于删失。删失不是错误,而是生存分析必须处理的正常数据结构。
这也是为什么KM法、Log-rank检验和Cox回归会成为主流工具。
2. 6种方法怎么选,先看你的研究问题
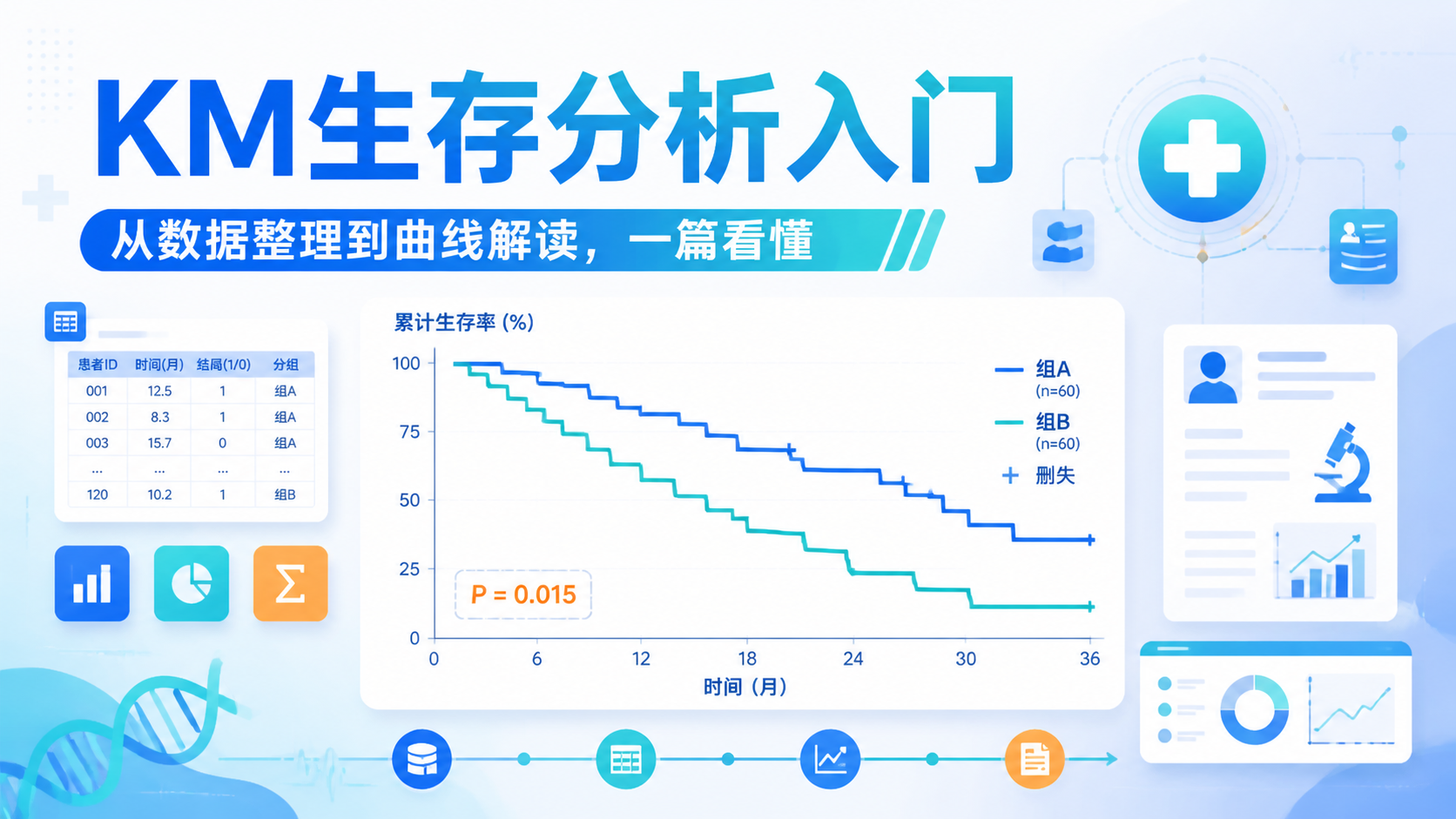
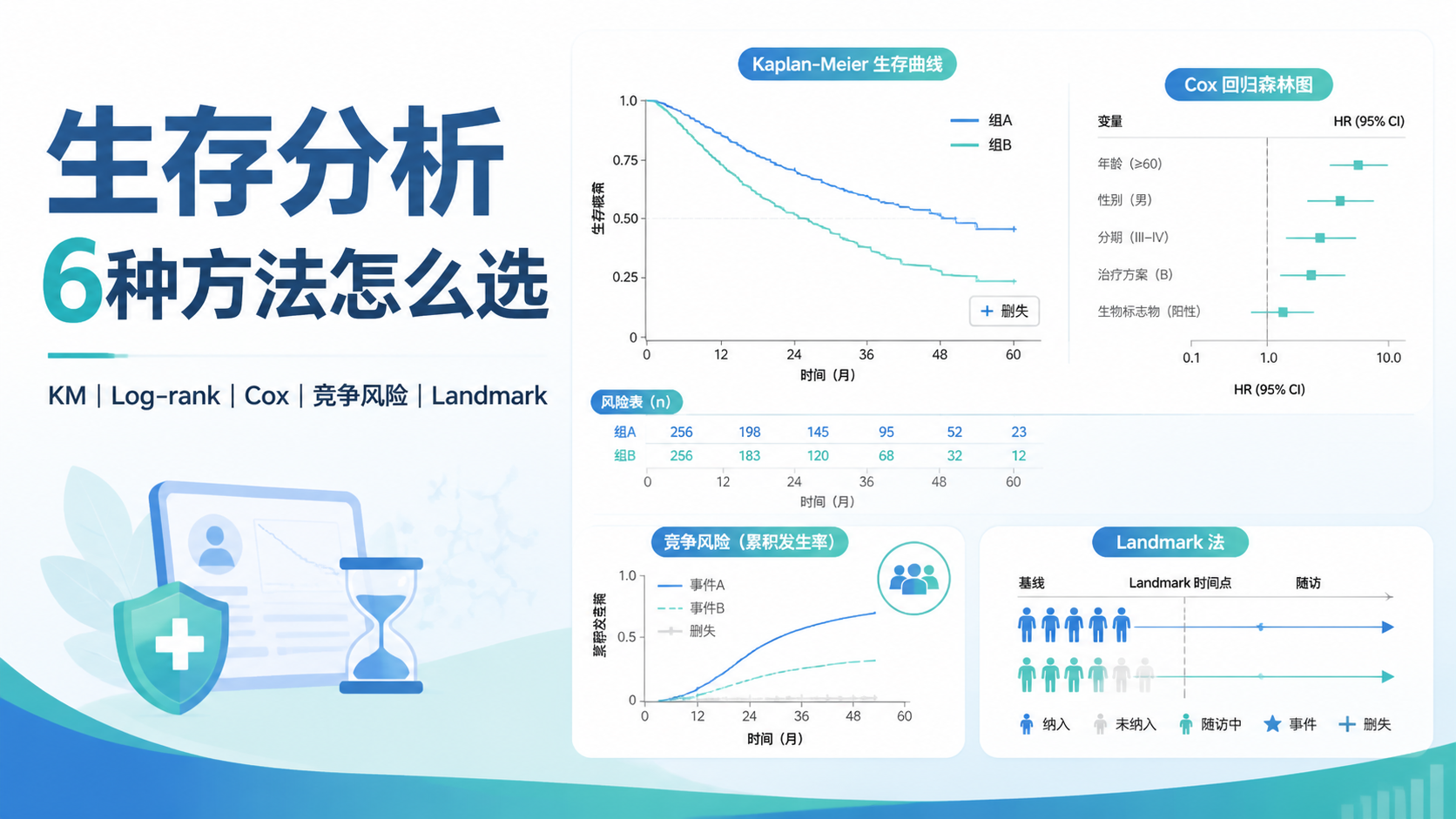
2.1 Kaplan-Meier法,最适合做生存描述
如果你的目标是看某组患者的生存情况,或者比较两组预后,首先想到的通常是KM法。
它能绘制生存曲线,直观展示不同时间点的生存概率。
KM法最常见的用途有三类:
- 描述单组生存情况。
- 比较分组后的生存差异。
- 报告中位生存时间和生存率。
在临床文章里,生存分析最常见的第一步就是KM法。
它适合样本量不大的研究,也适合做初步预后分析。
2.2 Log-rank检验,专门比较组间差异
如果你已经画出了KM曲线,下一步通常要判断两组曲线是否有统计学差异。
这时用的就是Log-rank检验。
它的特点是:
- 比较的是整个随访期间的生存差异。
- 对远期差异更敏感。
- 是KM分析的标准配套方法。
如果生存曲线没有明显交叉,Log-rank通常是首选。
如果曲线交叉明显,就要谨慎,因为它可能掩盖局部差异。
2.3 Cox回归,适合找独立预后因素
如果你不只是想“比较两组”,而是想找影响生存的因素,就要用Cox回归。
它是生存分析里的多因素模型,常用于筛选独立预后因素。
Cox回归最常报告的是HR,也就是风险比。
- HR > 1,说明风险更高。
- HR < 1,说明风险更低。
- HR = 1,说明无差异。
单因素Cox看的是粗略关联,多因素Cox看的是校正后的独立效应。
这点在论文写作里非常重要。
3. 另外3种方法,什么时候需要考虑
3.1 寿命表法,临床研究里很少用
寿命表法也是一种生存描述方法,但在实际临床研究中使用很少。
它更偏向分组汇总,灵活性不如KM法。
如果你做的是常规医学研究,通常不必优先考虑它。
大多数情况下,KM法比寿命表法更实用,也更容易发表。
3.2 竞争风险模型,适合“其他事件抢先发生”
当一个患者可能发生多个互相竞争的结局时,单纯KM法会高估目标事件概率。
比如研究某种肿瘤相关死亡,但患者可能先死于心血管事件。
这时就要考虑竞争风险模型。
它适用于:
- 多结局共存。
- 其他事件会阻止目标事件发生。
- 需要更真实的累积发生率估计。
如果结局类型不是单一事件,竞争风险模型往往比传统KM更合理。
3.3 two-stage或landmark法,适合曲线交叉或动态效应
当KM曲线交叉时,Log-rank和常规Cox可能不够理想。
这时可以考虑 two-stage 方法或 landmark 方法。
它们常用于:
- 暴露效应随时间变化。
- 早期和晚期效应方向不同。
- 生存曲线交叉明显。
这类方法更偏方法学研究,也更考验统计设计。
如果你的曲线交叉,别急着套Log-rank,先判断是不是动态效应。
4. 实战选择:6种方法怎么落地
4.1 先问自己3个问题
做生存分析前,先判断这3件事:
- 你是要描述生存,还是比较组间差异。
- 你的结局是不是单一事件。
- 生存曲线有没有交叉,是否存在时间依赖效应。
这三个问题,基本决定了方法选择。
不是先选软件,而是先选问题。
4.2 常规临床文章的推荐顺序
如果是大多数临床研究,建议按这个顺序做:
- 第一步,KM法画曲线。
- 第二步,Log-rank检验比较差异。
- 第三步,单因素Cox筛选变量。
- 第四步,多因素Cox找独立因素。
这套流程最符合常规论文写作逻辑。
也最容易让审稿人理解。
4.3 什么情况下要升级方法
遇到下面情况,就不要只停留在KM和Log-rank:
- 曲线交叉。
- 结局有竞争风险。
- 事件时间分布明显不均。
- 想做时间依赖分析。
这时需要根据研究设计,选择更合适的统计框架。
方法不是越复杂越好,而是越匹配研究问题越好。
5. 结果报告时,最容易出错的地方
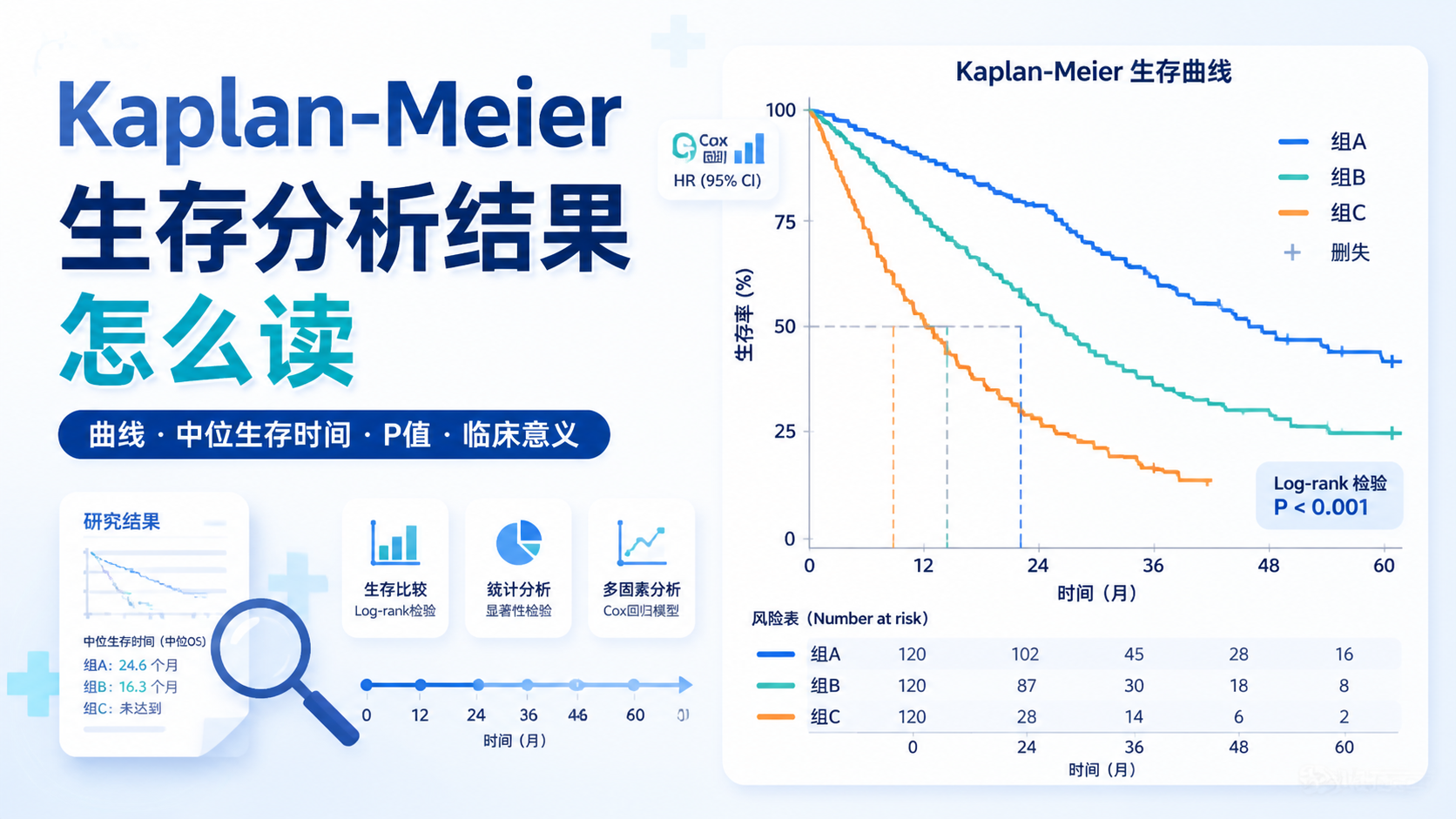
5.1 中位生存时间和中位随访时间不是一回事
这两个概念经常被混淆。
中位生存时间是看“事件发生到什么时间”。
中位随访时间是看“观察了多久”。
前者反映结局,后者反映观察长度。
写论文时必须区分,否则容易被审稿人指出。
5.2 生存率、累计生存概率也不是随便混用
生存率、生存概率、累计生存概率在具体语境中不能乱用。
在KM分析里,通常报告的是某时间点的生存概率或生存率。
建议统一表达,避免同一篇文章里概念混乱。
尤其是医学期刊,方法描述要准确。
5.3 HR的解释要结合模型类型
很多人只会写“HR显著升高”。
但必须区分:
- 单因素HR。
- 调整后的多因素HR。
前者是粗关联,后者才更接近独立效应。
如果没有校正混杂因素,结论不能直接写成“独立危险因素”。
6. 论文里怎么写,才符合规范
6.1 常见写法要规范
生存分析部分通常可以这样组织:
- 使用Kaplan-Meier法绘制生存曲线。
- 使用Log-rank检验比较组间差异。
- 使用Cox回归分析预后因素。
如果涉及更复杂设计,再补充竞争风险模型或其他方法。
方法描述越清楚,结果越容易被信任。
6.2 数据质量比方法更重要
再好的方法,也建立在正确的数据定义上。
终点定义不清、删失标记错误、随访时间计算错误,都会直接影响结果。
临床研究里最常见的问题包括:
- 终点定义前后不一致。
- 失访处理不规范。
- 随访日期记录有误。
- 事件编码错误。
这些问题一旦出现,后面所有生存分析都会受影响。
所以生存分析之前,必须先做好数据清洗。
6.3 高质量图表能显著提升可读性
生存曲线不是只要能画出来就行。
还要看是否清晰、是否标注删失点、是否有中位生存时间线、是否配色合理。
一张规范的生存曲线图,往往比大段文字更能说服审稿人。
这也是解螺旋在科研作图和分析支持中最强调的地方。
总结Conclusion
生存分析的本质,是在处理“时间 + 事件”的临床问题。
对于大多数医学研究,优先顺序通常是:KM法描述,Log-rank比较,Cox回归筛选预后因素。
如果出现曲线交叉、竞争风险或时间依赖效应,就需要升级到更合适的方法。
真正决定结果质量的,不只是统计模型,而是终点定义、删失处理和数据规范。
如果你希望把生存分析做得更稳、更快、更符合投稿要求,可以借助解螺旋的科研支持与分析服务,减少方法选择和结果解释上的偏差,提升论文效率与可信度。
- 引言Introduction
- 1. 先弄清楚:生存分析到底在分析什么
- 2. 6种方法怎么选,先看你的研究问题
- 3. 另外3种方法,什么时候需要考虑
- 4. 实战选择:6种方法怎么落地
- 5. 结果报告时,最容易出错的地方
- 6. 论文里怎么写,才符合规范
- 总结Conclusion