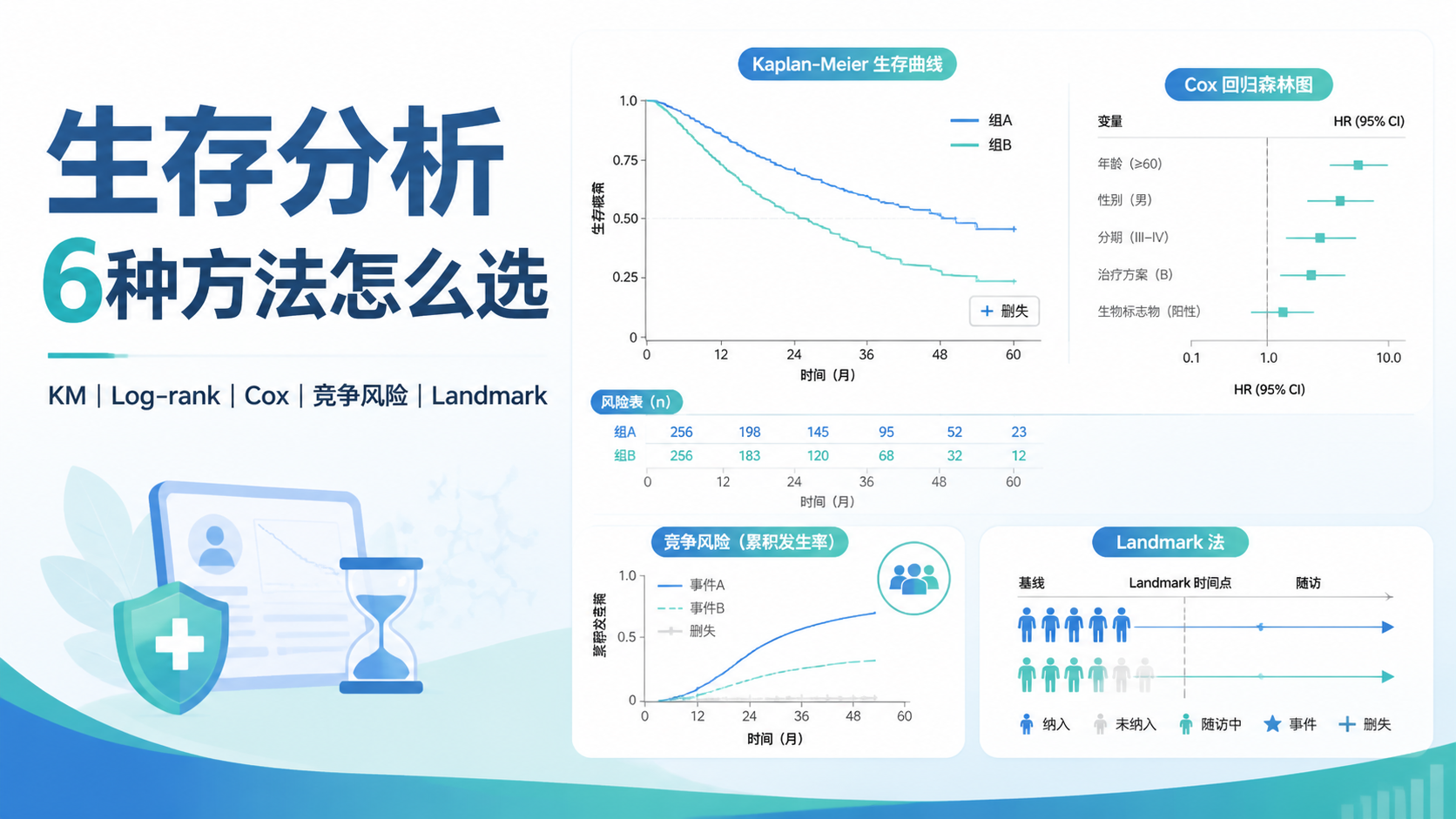
引言Introduction
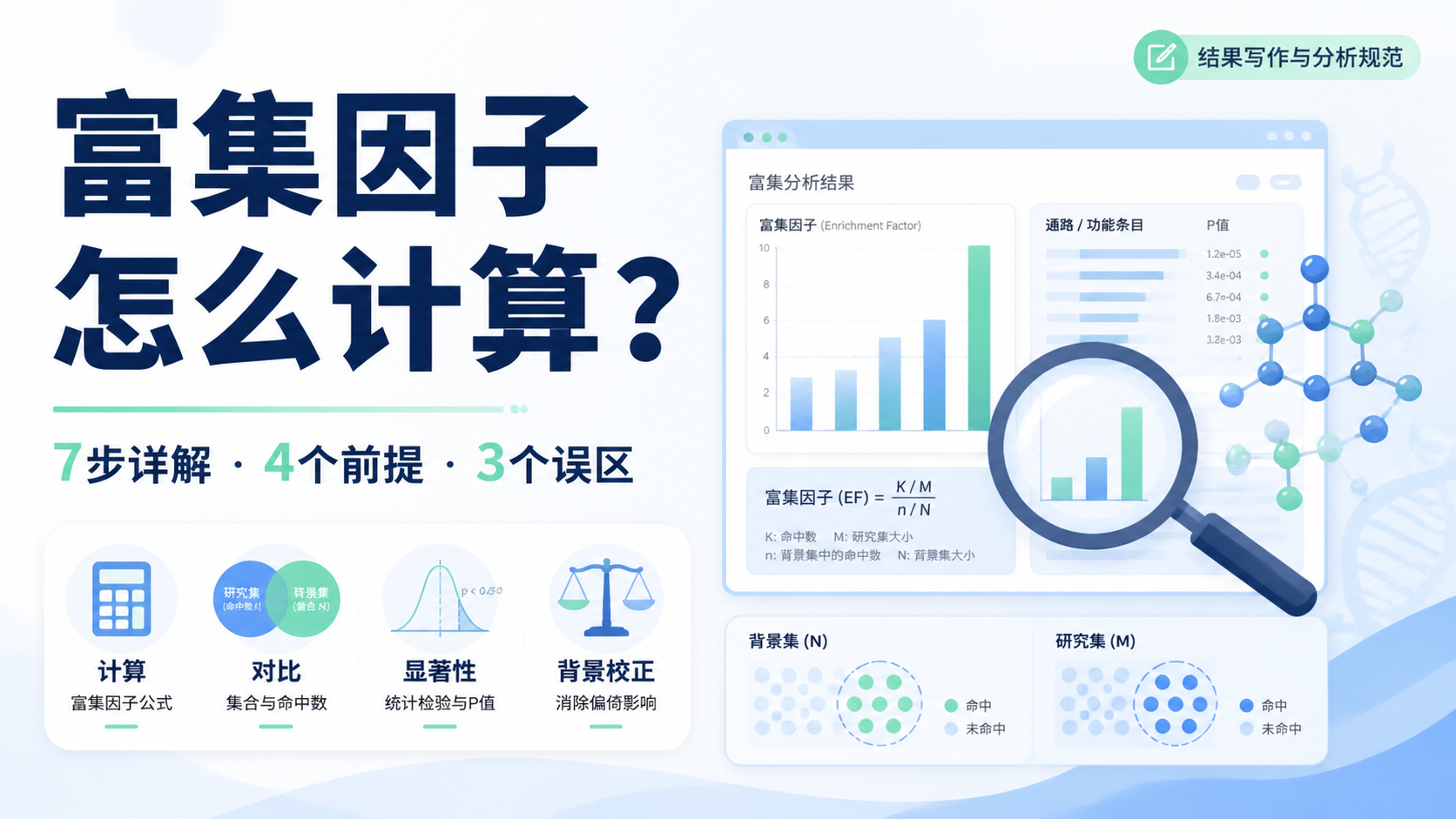
富集因子怎么计算,是很多医学生、医生和科研人员在做差异分析后最常遇到的问题。 结果表里有一堆基因、通路和数值,但不知道该看哪一项,更不知道如何判断“富集”是否真实可靠。本文用7步讲清富集因子的计算逻辑、常见公式和解读要点,帮助你少走弯路。
1. 先理解富集因子的本质
1.1 富集因子不是“越大越好”的绝对指标
富集因子本质上是一个比例指标,用来衡量某个基因集、通路或功能条目,在你的目标列表中出现的程度,是否高于背景水平。它常见于GO、KEGG、GSEA等分析场景。
它回答的是一个核心问题,某个条目在你的候选集合里是不是“比随机更集中”。 这也是为什么富集因子常与背景集、命中数、样本总数一起出现。没有背景,富集因子就失去比较基准。
1.2 它与富集倍数、富集比率要区分
在不同软件和文献中,富集因子有时会和“富集倍数”“enrichment ratio”混用。严格来说,命名可能不同,但计算思路通常围绕“观察频率”和“背景频率”的比较展开。
常见理解是:
- 观察到的比例
- 背景中的比例
- 二者的比值或差值
因此,第一步不是急着代公式,而是先确认你使用的软件定义。 这是避免结果解释错误的关键。
2. 搞清楚计算前的4个元素
2.1 明确目标集合
目标集合通常是差异表达基因、筛选后的蛋白列表,或某个分组中的候选分子。这个集合决定了“观察到多少命中”。
例如,你从1000个差异基因中挑选与炎症相关的80个基因,再去做通路分析。这里的1000个和80个,就是计算的起点。
2.2 明确背景集合
背景集合是计算富集因子最容易出错的地方。它可能是:
- 全基因组
- 检测到的全部基因
- 某一平台可检出的全部分子
背景集合选错,会直接改变富集因子大小。 比如把“全基因组”误当成“检测到的基因”,结果往往会被夸大或低估。
2.3 明确命中数和集合大小
你还需要两个最基本的数据:
- 命中数,目标集合中落入某通路或功能条目的数量
- 集合大小,该通路或功能条目在背景中的总数
这两个数是富集因子的核心输入。没有它们,无法进行规范计算。
2.4 明确分析类型
不同分析类型,公式表达会不同:
- 过度富集分析,常用比例比较
- GSEA,常结合排序统计和运行富集分数
- 功能注释分析,可能输出富集倍数、p值和FDR
同样叫“富集因子”,在不同场景下并不一定代表完全相同的数学含义。
3. 富集因子怎么计算:7步详解
3.1 第一步,确定目标条目
先选定你要评估的条目,比如某条通路、GO术语或疾病相关基因集。
不要同时混入多个层级的概念,否则结果不可解释。
3.2 第二步,统计目标集合中的命中数
统计你的候选列表里,有多少个分子属于该条目。
记为 k。
例如,某通路在差异基因中命中 12 个,那么 k=12。
3.3 第三步,统计目标集合总数
统计你用于分析的候选集合总量。
记为 n。
例如,你总共分析了 200 个差异基因,那么 n=200。
3.4 第四步,统计背景中的条目总数
在背景集合中,统计该条目包含多少个分子。
记为 K。
例如,背景中该通路共有 80 个基因,那么 K=80。
3.5 第五步,统计背景集合总数
统计背景集合的总数。
记为 N。
例如,背景可检出的基因总数为 20,000 个,那么 N=20,000。
3.6 第六步,套用常见富集因子公式
最常见的理解方式是:
富集因子 = 目标集合中该条目的比例 ÷ 背景中该条目的比例
也就是:
富集因子 = (k / n) ÷ (K / N)
代入上面的示例:
- k = 12
- n = 200
- K = 80
- N = 20,000
则:
- 目标比例 = 12/200 = 0.06
- 背景比例 = 80/20,000 = 0.004
- 富集因子 = 0.06/0.004 = 15
这个结果表示,该条目在你的候选集合中出现的频率,是背景的15倍。
3.7 第七步,结合显著性一起解释
富集因子大,不等于结论一定可靠。
你还要看 p 值、校正后的 FDR 或 q 值。
因为在高通量分析中,很多条目都可能“看起来富集”,但只有在统计学显著时,才更值得优先关注。
正确的顺序是先看显著性,再看富集因子,最后结合生物学意义判断。
4. 计算时最常见的3个误区
4.1 把命中数当成富集因子
命中数只是“多少个基因落入该条目”,不能直接代表富集程度。
一个条目命中20个基因,未必比命中10个基因的条目更富集,因为背景大小可能不同。
4.2 忽略背景校正
如果背景集合过小,富集因子会偏高。
如果背景集合过大,富集因子可能被稀释。
这也是为什么不同软件、不同数据库,结果可能不完全一致。
4.3 只看富集因子,不看多重检验
高通量研究会同时检验很多条目。
如果不做FDR校正,假阳性会明显增加。
对于科研论文和临床转化分析,富集因子必须与显著性指标联动解读。
5. 结果该怎么写,才更符合论文规范
5.1 建议写清公式和背景
在方法部分,最好说明:
- 采用了什么数据库
- 背景集合是什么
- 富集因子如何定义
- 是否进行了FDR校正
这样别人才能复现你的结果。
5.2 结果部分要同时报告多个指标
建议至少报告:
- 条目名称
- 命中基因数
- 富集因子
- p值
- FDR或q值
单独写一个富集因子,信息是不完整的。
5.3 图表展示要简洁
常用展示方式包括:
- 气泡图
- 柱状图
- 网络图
- 热图
如果是通路分析,气泡图最直观,因为它能同时表达富集因子、显著性和命中数。
6. 实际分析中如何提高富集因子的可信度
6.1 先保证输入数据质量
输入列表越干净,结果越稳。
建议先完成:
- 去重
- ID转换
- 物种统一
- 背景一致化
任何一个环节出错,都可能影响富集因子。
6.2 优先使用可复现的分析流程
建议使用标准化流程完成分析,并保留版本信息。
包括数据库版本、注释版本、软件版本和参数设置。
对于科研人员来说,可复现性和富集因子同样重要。
因为可复现,才有可信度。
6.3 结合生物学背景做二次筛选
不是所有显著结果都值得写进论文。
你还要结合疾病机制、药理路径、组织特异性和实验设计进行筛选。
例如,在炎症相关研究中,免疫通路和细胞因子信号往往比泛化代谢通路更有解释力。
7. 富集因子计算后,如何更高效完成分析与写作
7.1 从“会算”到“会讲”很关键
很多人能算出富集因子,却不会把结果组织成论文语言。
这会影响摘要、结果和讨论部分的表达质量。
你需要把“数值结果”转化成“机制解释”,再转化成“图表证据”。
这一步决定了文章是否专业。
7.2 用标准化工具减少重复劳动
对于医学生和科研人员来说,真正耗时的往往不是计算本身,而是:
- 数据整理
- 结果筛选
- 图表排版
- 论文语言润色
这时候,标准化的分析和写作支持会显著提高效率。解螺旋品牌 提供面向科研场景的内容与工具支持,能够帮助你更快完成数据表达、结果梳理和论文呈现,让富集因子分析不再停留在“算出来”,而是顺利走向“写得清、投得出”。

总结Conclusion
富集因子怎么计算,核心就是比较“目标集合中的比例”和“背景集合中的比例”。 你只要掌握目标数、命中数、背景数和背景总量这4个要素,再按7步流程计算,就能快速得到可解释的结果。
但要记住,富集因子不是孤立指标。它必须结合 p 值、FDR、背景定义和生物学意义一起判断。对医学生、医生和科研人员而言,真正有价值的不是“算出一个数”,而是把这个数变成能支撑机制假设和论文结论的证据。
如果你希望进一步提高分析效率、减少写作负担,并把富集因子结果更规范地呈现出来,可以关注解螺旋品牌 ,让数据分析、结果表达和科研写作衔接得更顺畅。
- 引言Introduction
- 1. 先理解富集因子的本质
- 2. 搞清楚计算前的4个元素
- 3. 富集因子怎么计算:7步详解
- 4. 计算时最常见的3个误区
- 5. 结果该怎么写,才更符合论文规范
- 6. 实际分析中如何提高富集因子的可信度
- 7. 富集因子计算后,如何更高效完成分析与写作
- 总结Conclusion