





引言Introduction
GSVA富集分析常用于把“基因层面”转成“通路层面”,但很多人拿到结果后只会看热图,不知道该先看什么、怎么判断是否有生物学意义。如果你也在做GSVA富集分析,这篇文章会帮你快速理清结果解读框架。
1. 先理解GSVA富集分析的输出是什么
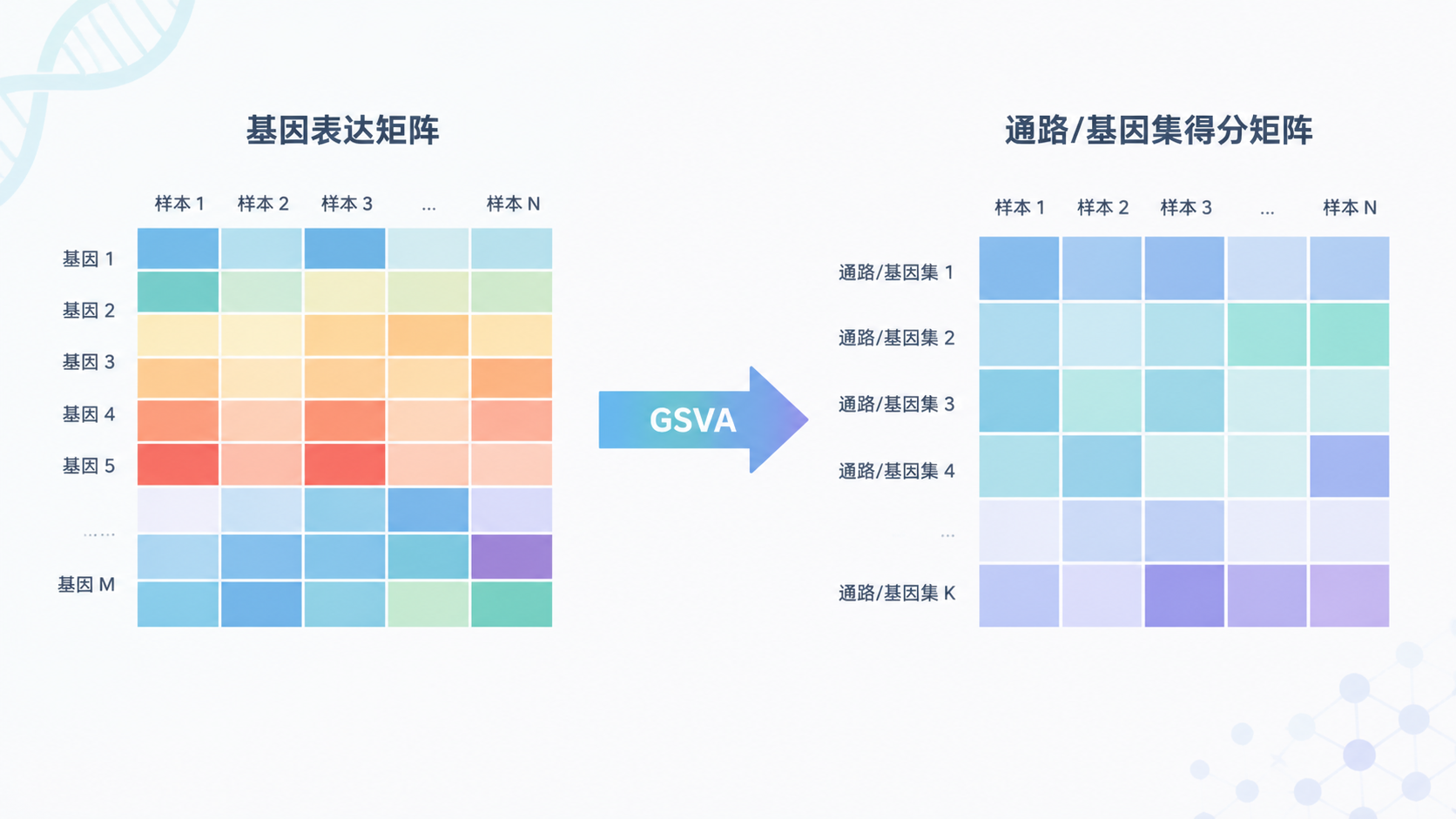
1.1 从表达矩阵到基因集矩阵
GSVA的核心,不是直接找差异基因,而是把基因×样本表达矩阵 转换成基因集×样本得分矩阵 。这一步非常关键。因为后续比较的对象,已经从单个基因变成了通路或功能基因集。
换句话说,GSVA富集分析的结果,本质上是每个样本在每条通路上的活性评分。 这个评分不是“是否富集”的二元判断,而是连续数值。它更适合做样本间比较、分组差异分析和聚类分析。
1.2 结果文件通常怎么看
完成GSVA后,你通常会得到一个新的矩阵。行是基因集或通路,列是样本,数值是富集得分。这个矩阵可以继续接入limma做差异分析,也可以用于热图、分组比较、生存分析、CNV通路分析等。
因此,GSVA富集分析不只是一个终点,而是后续通路水平统计分析的起点。 这一点和传统富集分析很不同。传统方法更强调“哪些通路显著”,GSVA更强调“每个样本的通路活性如何变化”。
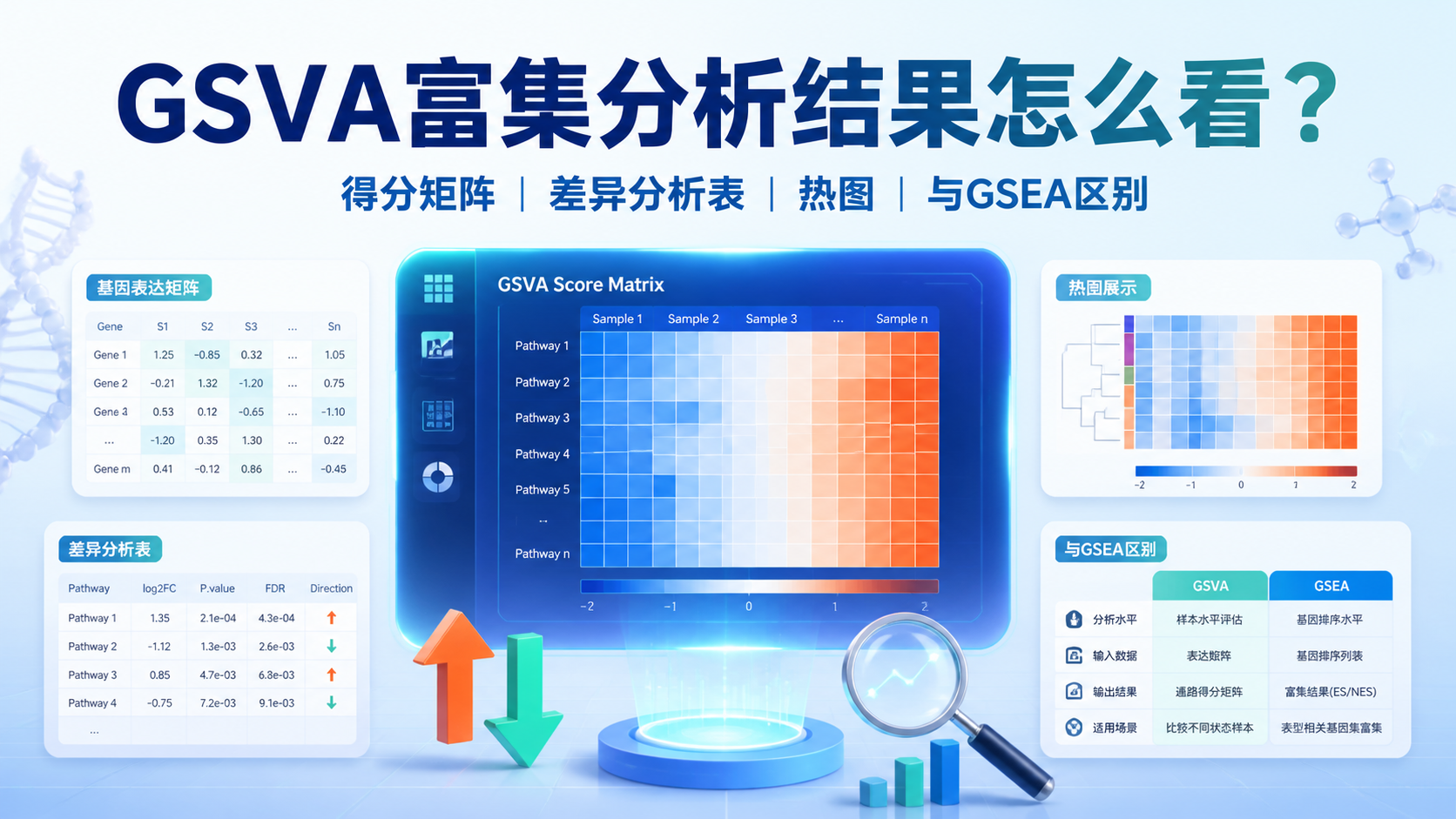
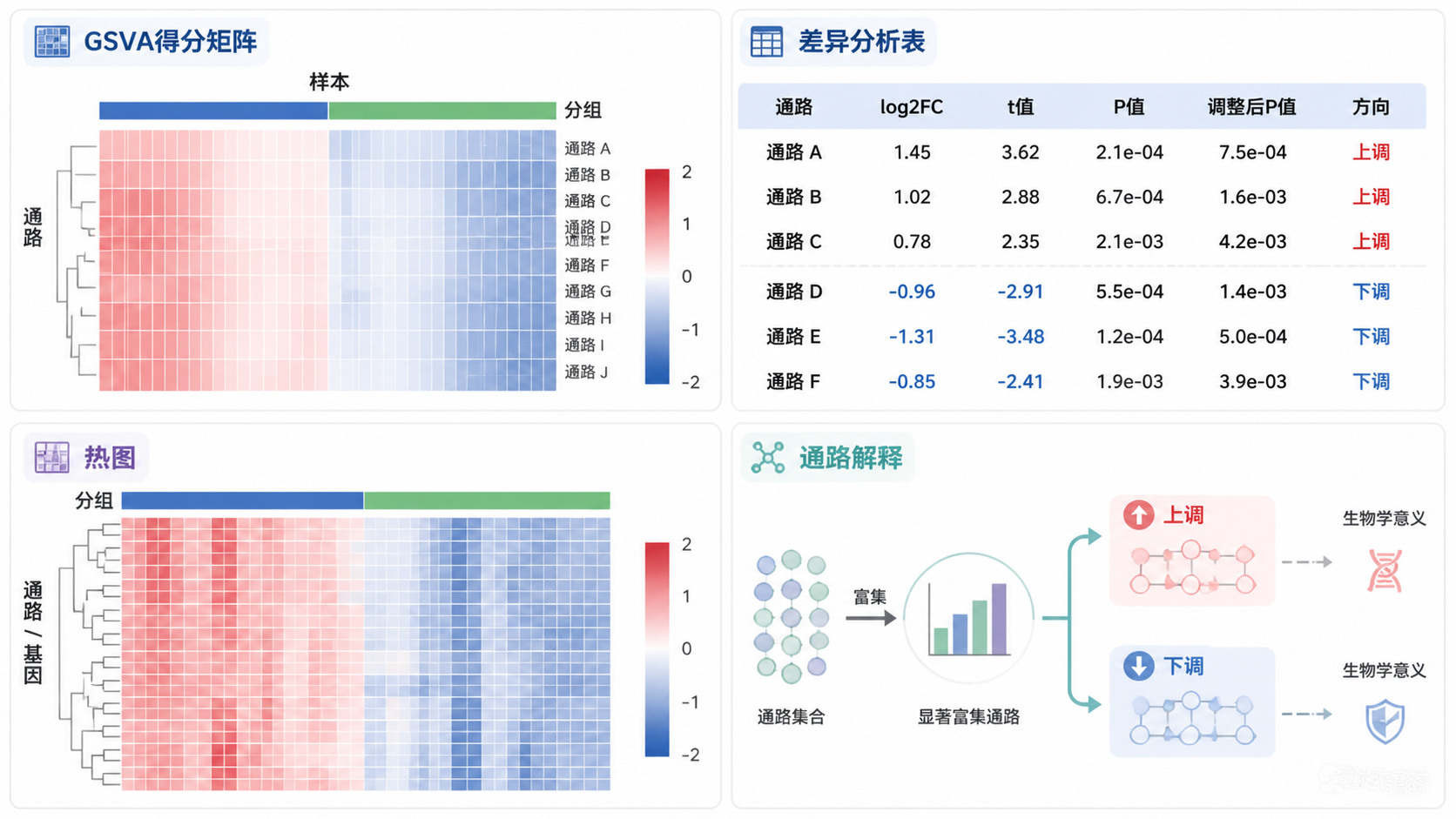
2. 必看的第1类结果:GSVA得分矩阵
2.1 得分矩阵是最原始、最核心的结果
解读GSVA富集分析时,第一类必须看的结果就是得分矩阵。它直接反映每个样本在每个通路上的相对活性。没有这个矩阵,后面的差异分析和可视化都无从谈起。
这里要注意,GSVA分析得到的不是基因表达量,而是基因集层面的信号值。也就是说,原始表达矩阵中的“基因名”会被替换成“通路名”或“基因集名”。
2.2 先看分布,再看异常值
读矩阵时,建议先做两步检查。
- 看每个样本的得分分布是否大致一致。
- 看是否存在极端值或异常样本。
如果某些样本整体偏离很大,可能要回头检查输入表达矩阵的标准化方式。知识库中明确提到,GSVA的kcdf参数需要与数据类型匹配 。
- Gaussian,适用于芯片表达矩阵,以及log-CPM、log-RPKM、log-TPM等标准化后的RNA-seq数据。
- Poisson,适用于未标准化的RNA-seq count矩阵。
输入数据类型不对,后面的GSVA富集分析解读就会失真。
3. 必看的第2类结果:差异分析表
3.1 为什么GSVA结果还要做差异分析
很多人以为GSVA跑完就结束了,其实真正有价值的是把通路得分矩阵再做差异分析。知识库中推荐使用limma包,流程是lmFit、eBayes、topTable。这样可以回答一个更具体的问题:不同分组之间,哪些通路活性显著不同?
对于医学生、医生和科研人员来说,这一步最接近“机制解释”。因为你不再只看某个基因上调,而是看整条通路是否被激活或抑制。
3.2 差异表重点看哪几列
根据课程内容,limma差异分析结果通常有7列,但最需要关注的是这三列:
- 通路或基因集名称
- logFC
- 校正后P值,通常是adj.P.Val或p.adjust
logFC告诉你通路在两组之间是上调还是下调。 校正后P值告诉你这个变化是否可靠。只看原始P值不够,因为多重检验下假阳性风险很高。
3.3 如何快速判断结果是否可信
解读GSVA富集分析时,建议优先筛选:
- 校正后P值小于0.05
- logFC绝对值较大
- 生物学方向和研究问题一致
例如,如果研究的是炎症相关过程,就要重点看免疫、细胞因子、NF-κB、抗原呈递等通路是否发生系统性变化。统计显著只是第一步,生物学可解释性才是最终目标。
4. 必看的第3类结果:热图
4.1 热图不是“好看”,而是最直观的模式图
GSVA富集分析的热图,通常由pheatmap绘制。它可以同时展示样本聚类和通路聚类。对于结果解读来说,热图非常重要,因为它能告诉你:通路信号的变化,是不是能把样本自然分开。
4.2 热图要看哪四个信息
看热图时,建议重点关注四件事:
- 样本是否按分组聚在一起。
- 差异通路是否形成清晰模块。
- 红蓝颜色变化是否一致。
- 是否存在少数通路驱动了整体分组。
知识库中提到,热图里红色表示信号高,蓝色表示信号低。如果高信号通路集中在某组,而低信号通路集中在另一组,说明GSVA富集分析抓到了较稳定的通路层面差异。
4.3 热图结果如何用于论文表达
写论文时,不要只说“热图显示两组差异明显”。更好的写法是:
- 某组样本在一组免疫相关通路上整体升高
- 另一组样本在代谢相关通路上整体降低
- 样本聚类与分组信息一致,提示通路特征具有分类能力
这类表述比单纯描述颜色变化更符合E-E-A-T要求,也更有说服力。
5. 必看的第4类结果:GSVA与GSEA、传统富集的关系
5.1 三者不是一回事
很多人把GSVA、GSEA和传统富集混在一起。其实它们的输入和输出都不一样。
- 传统富集分析通常先基于差异基因。
- GSEA基于排序基因列表,不要求先筛差异基因。
- GSVA则进一步把每个样本转换成通路得分,再做样本级分析。
GSVA富集分析的优势在于,它能从样本维度刻画通路活性,而不是只给出一份“显著通路清单”。
5.2 为什么这个区别重要
对于临床样本、肿瘤分型、疗效预测这类问题,单纯的通路名单往往不够。研究者更关心:
- 哪些样本通路活性更高
- 通路活性是否与分组、分期、预后相关
- 是否能形成稳定的分型模式
这也是为什么GSVA富集分析常用于生存分析、聚类、CNV通路和跨组织比较。它的重点不是“是否富集”,而是“富集信号在样本间如何波动”。
5.3 参数设置也会影响结果解读
解读结果前,还要确认几个关键参数是否合理。知识库中提到:
- method默认是gsva
- kcdf要与数据类型匹配
- min.sz和max.sz控制基因集大小
- mx.diff和abs.ranking会影响富集得分计算方式
如果这些参数设置不合适,结果可能偏向某些基因集,影响后续判断。所以GSVA富集分析不是单看输出,还要回头检查参数与数据是否匹配。
6. GSVA富集分析结果解读的实用流程
6.1 建议按这个顺序看
如果你刚拿到结果,可以按以下顺序解读:
- 先确认输入数据类型和标准化方式。
- 再看GSVA得分矩阵的整体分布。
- 然后做limma差异分析。
- 接着看热图和分组模式。
- 最后结合具体通路做生物学解释。
这个顺序比直接看显著通路更稳妥。
6.2 结果解释要避免的错误
常见错误有三个:
- 只看P值,不看logFC
- 只看热图,不看原始矩阵
- 只做统计,不结合研究背景
对于科研写作,最重要的是把统计结果和机制问题对应起来。比如炎症、代谢、细胞周期、DNA修复、免疫浸润等方向,往往更容易形成可解释的结果框架。
总结Conclusion
GSVA富集分析的解读,关键不是“有没有显著通路”,而是通路在样本间如何变化、是否能支撑分组差异、是否具备生物学解释力 。真正要看的4类结果是:得分矩阵、差异分析表、热图,以及它与GSEA和传统富集分析的关系。
如果你正在做GSVA富集分析,却还停留在“跑完软件看热图”的阶段,可以借助解螺旋 的生信课程和实操资源,快速把结果解读能力补齐。从参数设置到结果可视化,再到通路层面的论文表达,解螺旋都能帮助你更高效地完成分析闭环。
- 引言Introduction
- 1. 先理解GSVA富集分析的输出是什么
- 2. 必看的第1类结果:GSVA得分矩阵
- 3. 必看的第2类结果:差异分析表
- 4. 必看的第3类结果:热图
- 5. 必看的第4类结果:GSVA与GSEA、传统富集的关系
- 6. GSVA富集分析结果解读的实用流程
- 总结Conclusion



