引言Introduction
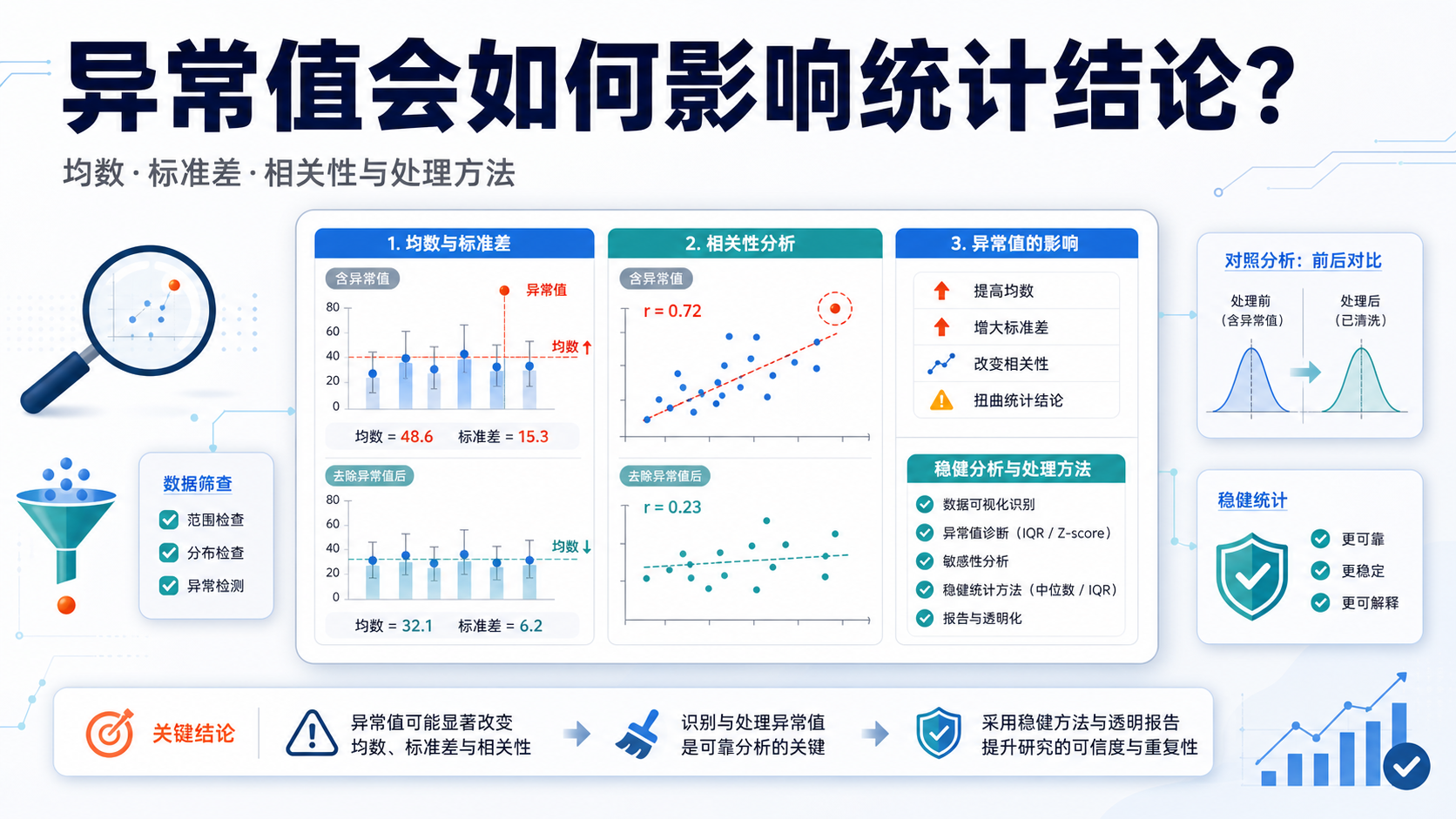
数据清洗异常值处理,是临床研究和真实世界数据分析里最容易出错的一步。异常值识别出来了,不代表问题结束。如果处理不当,结论可能被少数极端值带偏。
1. 先核实,再决定是否修正
1.1 优先回到原始资料核对
在数据清洗异常值处理时,第一原则不是删除,而是核查。课程内容明确提到,发现异常值后,条件允许时应先与原始档案或调查对象校对 ,确认是否存在录入错误、记录错误或抄写错误。
例如,住院患者基本信息里,38岁成年男性身高被记成280cm,这类值显然不符合常识。若能联系到原始来源,且真实值确认为180cm,就可以直接修正。
这一步的价值在于,它处理的不是“异常”,而是“错误”。
1.2 适用场景是“可追溯的异常”
核实法最适合用于关键变量清晰、原始信息可回查的场景。比如电子病历、纸质表单、随访记录。
但现实中,很多研究并不能重新联系受试者,也无法回到原始数据源。这时就要进入下一步判断:这个异常值,是否足以影响分析结论。
要点是先判断它是不是“真错误”,而不是先把它当成“坏数据”。
在临床研究中,这种判断比简单删除更重要,因为它直接关系到样本保真度和结果可信度。
2. 无法核实时,按研究重要性处理
2.1 关键变量的明显逻辑错误,可考虑个案删除
当异常值无法核实时,如果该变量又是研究中的重要变量,例如分组变量或结局变量,就需要结合专业知识和统计学判断。
知识库明确指出,对存在明显逻辑错误的个案,可采用个案删除法 。
例如,某17岁女学生体重记录为5kg,这类值明显不合理。若体重是结局变量,而且无法确认原始信息,通常应将该个案排除在分析范围之外。
但这一方法有代价。删除个案会损失样本量。 因此更适合样本量较大、异常比例不高的研究。
2.2 删除前后做一次敏感性比较
如果没有明确理由支持删除,建议先做前后对比分析。知识库提到,可在剔除异常值前后分别进行统计分析。
如果两次结果一致,说明该异常值对结论影响不大。
如果结果相互矛盾,就要谨慎,不能仅凭经验删除。
这一步本质上是敏感性分析。它能帮助研究者判断,异常值到底是“噪声”,还是“信号”。
对于医学生、医生和科研人员来说,这一步尤其关键,因为临床结论通常不能建立在单次主观判断上。
2.3 也可以改为缺失值,再按缺失值规则处理
当异常值不宜直接删除时,另一种常见做法是把异常值改为缺失值,再按缺失值处理流程继续分析。
知识库中提到,缺失值后续可用多种方法处理,如均值/众数填补、回归法、多重填补法等。
这种方法的优点是保留了数据处理的连续性。
它尤其适合那些“值明显不可信,但又不能确认是否应完全剔除”的场景。
本质上,这是把一个无法解释的异常,转化为一个更标准的统计问题。
3. 不删除,也能通过稳健分析降低影响
3.1 中位数比均数更抗极端值
如果选择保留异常值,就要考虑它对统计结果的影响。知识库提到,在存在特别大或特别小的异常值时,均数会被明显拉高或拉低。
此时可改用中位数 描述数据的中心趋势。
例如,在分布偏态或极端值较多的临床指标中,中位数通常比均数更稳健。
它不会被单个极端值“拖走”。
这也是临床研究里常见的描述方式,尤其适用于住院天数、实验室指标、费用数据等偏态变量。
3.2 对数变换和截尾均数也是常用工具
对于大于0的观测值,可以考虑对数变换,之后再计算几何均数。知识库指出,这种方法可降低极大值的影响。
但也要注意,它会夸大极小值的影响,因此不能机械使用。
另一种稳健指标是截尾均数 。它的做法是先把数据排序,再从两端各截掉一定比例的数据,最后计算剩余数据的均数。
课程中明确说明,这种方法能减少异常值干扰,在体育评分、赛事评价中已有广泛应用。
不过,截尾比例没有统一标准。不同软件默认值也不同,有的两端各截5%,有的各截10%。
因此,在正式研究中应结合样本分布、软件设定和研究目的来决定,不能照搬默认参数。
3.3 保留并标记,也是处理方式
知识库还强调,不处理异常值本身也是一种处理方式。
如果确认该值真实存在,或者研究目的本就需要保留极端个体,那么可以保留异常值,但要做好标记,在后续分析中评估它对结果的影响。
这类策略常见于探索性研究、稀有病研究或极端表型分析。
关键不在于“有没有异常值”,而在于研究者是否知道它的存在,并能解释它对结果的可能影响。
4. 临床研究中更稳妥的数据清洗思路
4.1 先识别,再分类,再处理
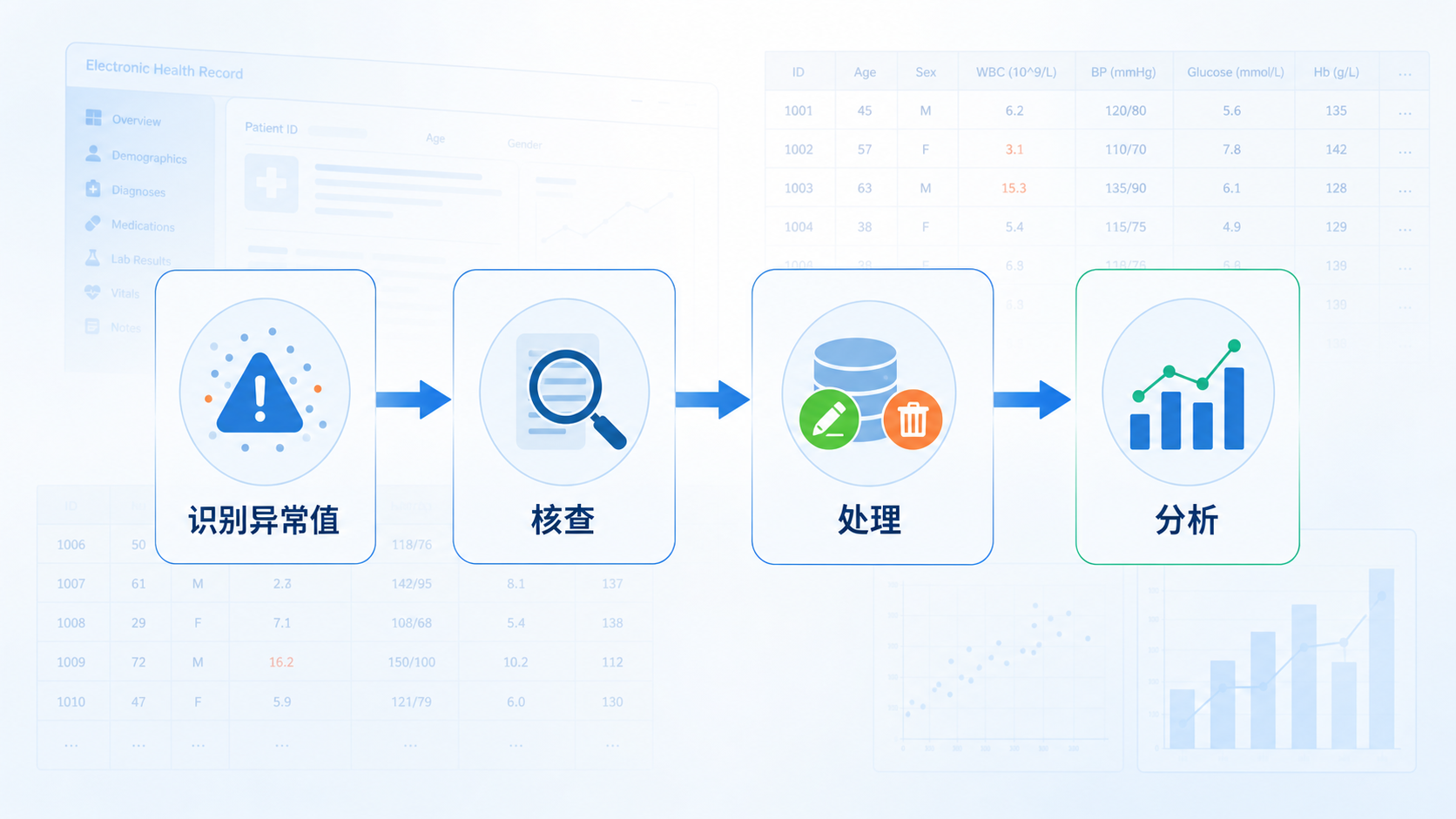
数据清洗异常值处理不是单一步骤,而是一个顺序明确的流程。
先识别异常值,再判断它是录入错误、逻辑错误,还是合理但极端的真实值。
然后再决定修正、删除、转为缺失值、稳健分析,或者直接保留。
这一顺序非常重要。因为不同类型的异常值,对结论的影响完全不同。
连续变量可以借助极值、箱线图、z-score识别。
分类变量则可借助频数分布法、个案选择结合频数法识别。
识别方法对了,后续处理才有意义。
4.2 研究设计决定处理强度
如果是大样本研究,且异常比例很低,个案删除的可行性更高。
如果是小样本研究,随意删除会造成更大偏倚。
如果涉及结局变量、分组变量等关键字段,则应格外谨慎。
临床研究的核心不是“把数据洗得很干净”,而是“把数据处理得可解释、可复核、可复现”。
这也是 E-E-A-T 中专业性和可信度的体现。
4.3 用标准化工具减少人工失误
在实际项目中,异常值处理往往依赖团队协作。
如果没有统一标准,容易出现同一批数据被不同人做出不同处理的情况。
这会直接影响分析一致性和论文可重复性。
像解螺旋这类面向临床研究的数据分析与写作工具,价值就在于帮助研究者把异常值识别、清洗、分析流程标准化。
把规则固化下来,才能减少主观判断带来的偏差,让数据清洗异常值处理更高效、更规范。
总结Conclusion
数据清洗异常值处理,核心不是“删不删”,而是“怎么判断、怎么留证据、怎么保证结果可靠”。
最稳妥的路径有三步:先核实原始数据,再按重要性决定删除或转缺失,最后用稳健统计降低极端值影响。
对于临床研究者来说,异常值处理的目标不是消灭异常,而是让分析更接近真实世界。
如果你希望把异常值识别、处理和统计分析做得更规范,建议借助解螺旋品牌相关工具和方法,减少人工判断误差,提升数据清洗效率与论文质量。

- 引言Introduction
- 1. 先核实,再决定是否修正
- 2. 无法核实时,按研究重要性处理
- 3. 不删除,也能通过稳健分析降低影响
- 4. 临床研究中更稳妥的数据清洗思路
- 总结Conclusion